Docker与k8s的恩怨情仇——Kubernetes的创新
Posted powertoolsteam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker与k8s的恩怨情仇——Kubernetes的创新相关的知识,希望对你有一定的参考价值。
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
上节中我们提到了社区生态的发展使得Kubernetes得到了良性的发展和传播。比起相对封闭的Docker社区开放的CNCF社区获得了更大成功,但仅仅是社区的活力对比还不足以让Docker这么快的败下阵来,其根本原因是Kubernetes的对容器编排技术的理解比起Docker更胜一筹。这种优势几乎是压到性的降维打击,Docker毫无还手之力。
接下来便为大家介绍在这场容器大战之中,Kubernetes如何占据优势地位。
容器编排
所谓容器编排,其实就是处理容器和容器之间的关系,在一个分布式的大型系统里,不可能是以多个单一个体存在的,它们可能是一个与多个,一群与一群这样相互交织着。

Docker的容器编排功能
Docker构建的是以Docker容器为最核心的PaaS生态,包括以Docker Compose为主的简单容器关系编排,以及以Docker Swarm为主的线上运维平台。用户可以通过Docker Compose处理自己集群中容器之间的关系,并且通过Docker Swarm管理运维自己的集群,可以看到这一切其实就是当初Cloud Foundry的PaaS功能,所主打的就是和Docker容器的无缝集成。
Docker Compose做到的是为多个有交互关系建立一种“连接”,把它们全部编写在一个docker-compose.yaml文件中,然后统一发布(我后面说到的组里的ELK功能就是这样做的),这样做也有优点,就是对于简单的几个容器之间的交互来说非常便利。但是对于大型的集群来说却有些杯水车薪,并且这种每出现一种新需求就需要单独做一项新功能的开发模式,将使后期代码维护变得十分困难。
Kubernetes如果要和Docker对抗,肯定不能仅仅只做Docker容器管理这种Docker本身就已经支持的功能了,这样的话别说分庭抗礼,可能连Docker的基本用户都吸引不到。因此在Kubernetes设计之初,就确定了不以Docker为核心依赖的设计理念。在Kubernetes中,Docker仅是容器运行时实现的一个可选项,用户可以依据自己的喜好任意调换自己需要的容器内容且Kubernetes为这些容器都提供了接口。此外,Kubernetes准确的抓住了Docker容器的一个致命性的弱点进行了自身创新。
接下来就让我们一起来了解,这个给Docker造成降维打击的内容究竟是什么?
Kubernetes的容器编排功能

与Docker这种站在容器视角上只能处理容器之间的关系所不同,Kubernetes所做的是从软件工程的设计理念出发,将关系进行了不同类的划分,定义了紧密关系(Pod之间)和交互关系(Service之间)的概念,然后再对不同的关系进行特定的编排实现。
乍一听你可能是一头雾水。这里举个不太实际但是一看就懂的例子:如果把容器之间的关系比作人之间的关系,Docker能处理的是仅仅是站在单一个体的角度上,处理人与人之间的人际关系;而Kubernetes确是上帝,站在上帝视角不仅能处理人与人之间的人际关系,还能处理狗与狗之间的狗际关系,最主要的是能处理人与狗之间的交往关系。

而实现上述紧密关系的原理,就是Kubernetes创新的Pod。
Pod是Kubernetes所创新的一个概念,其原型是Borg中的Alloc,是Kubernetes运行应用的最小执行单元,由一个或者多个紧密协作的容器组合而成,其出现的原因是针对容器的一个致命性弱点——单一进程这问题的扩展,让容器有了进程组的概念。通过第一节,我们知道了容器的本质是一个进程,其本身就是超级进程,其他进程都必须是它的子进程,因此在容器中,没有进程组的概念,而在日常的程序运行中,进程组是常常配合使用的。
使用Pod处理紧密关系
为了给大家介绍Pod处理紧密关系的原理,这里举一个进程组的例子:
Linux中有一个负责操作系统日志处理的程序rsyslogd是由三个模块组成,分别是:imklog模块、muxsock模块以及rsyslogd自己的main函数主进程。这三个进程组一定要运行在同一台机器上,否则它们之间的基于Socket的通信和文件的交换都会出现问题。
而上述的这个问题,如果出现在Docker中,就不得不使用三个不同的容器分别描述了,并且用户还得自己模拟处理它们三个之间的通信关系,这种复杂度可能比使用容器运维都高的多。并且对于这个问题的运维,Docker Swarm也有自己本身的问题。以上述的例子为基础,如果三个模块分别都需要1GB的内存运行,如果Docker Swarm运行的集群中有两个node,node-1剩余2.5GB,node-2剩余3GB。这种情况下分别使用docker run 模块运行上述三个容器,基于Swarm的affinity=main约束,他们三个都必须要调度到同一台机器上,但是Swarm却很有可能先分配两个去node-1,然后剩余的一个由于还剩0.5GB不满足调度而使这次调度失败。这种典型的成组调度(gang scheduling)没有被妥善处理的例子在Docker Swarm中经常存在。
基于上述的需求,Kubernetes有了Pod这个概念来处理这种紧密关系。在一个Pod中的容器共享相同的Cgroups和Namespace,因此它们之间并不存在边界和隔离环境,它们可以共享同一个网络IP,使用相同的Volume处理数据等等。其中的原理就是在多个容器之间创建其共享资源的链接。但是为了解决到底是A共享B,还是B共享A,以及A和B谁先启动这种拓扑性的问题,一个Pod其实是由一个Infra容器联合AB两个容器共同组成的,其中Infra容器是第一个启动的:
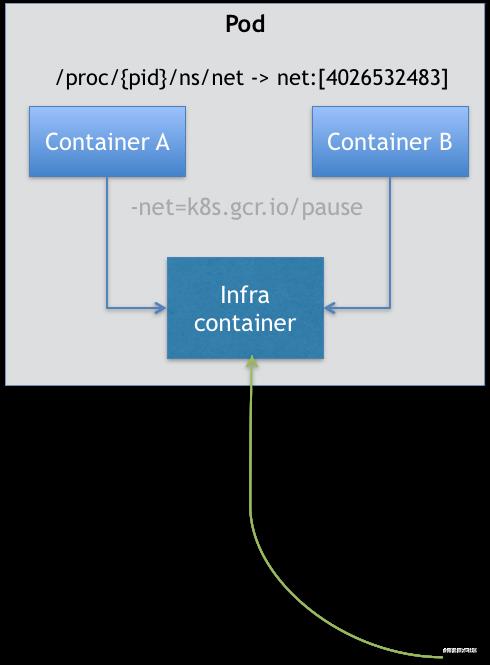
Infra容器是一个用汇编语言编写的、主进程是一个永远处于“暂停”状态的容器,其仅占用极少的资源,解压之后也仅有100KB左右。
实例演示在Kubernetes中的Pod
介绍了一通,接下来我们在实例中为大家演示Pod长什么样子。
我们在任意一个装有Kubernetes的集群中通过以下的yaml文件和shell命令运行处一个Pod,这个YAML文件具体是什么意思暂时不用理会,之后我会对这个YAML做一说明,我们目前只需要明白:Kubernetes中的所有资源都可以通过以下这种YAML文件或者json文件描述的,现在我们只需要知道这是一个运行着busybox和nginx的Pod即可:

创建这个hello-pod.yaml文件之后运行以下命令:

通过上述命令,我们就成功创建了一个pod,我们可以从执行结果看到infra容器的主进程成为了此Pod的PID==1的超级进程,说明了Pod是组合而成的:

至此,我们应该要理解Pod是Kubernetes的最小调度单位这个概念了,并且也应该把Pod作为一个整体而不是多个容器的集合来看待。
我们再看看描述这个Pod的文件类型YAML。
YAML的语法定义:
YAML是一种专门编写配置文件的语言,其简洁且强大,在描述配置文件方面远胜于JSON,因此在很多新兴的项目比如Kubernetes和Docker Compose等都通过YAML来作为配置文件的描述语言。与html相同,YAML也是一个英文的缩写:YAML Ain’t Markup Language,聪明的同学已经看出来了,这是一个递归写法,突出了满满的程序员气息。其语法有如下特征:
- 大小写敏感
- 使用缩进表示层级关系,类似Python
- 缩进不允许使用Tab,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对其即可
- 数组用短横线-表示
- NULL用波浪线~表示
明确了以上概念,我们把YAML改写成一个JSON,看看这之间的区别:

这两种写法在Kubernetes中是等效的,上述的JSON可以正常运行,但是Kubernetes还是更推荐使用YAML。从上面的对比中我们也能发现,在之前的使用中一直很好用的JSON现在也略显笨拙,需要些大量的字符串标志。
看完语法,我们再来说说上述YAML中的各个节点在Kubernetes所表示的意思。Kubernetes中的有一种类似于Java语法万物皆对象的概念,所有内部的资源,包括服务器node、服务service以及运行组Pod在kubernetes中皆是以对象的形式存储的,其所有对象都由一下固定的部分组成:

- apiVersion:在官方文档中并没有给出相应的解释,但是从名字可以看出这是一个规定API版本的字段,但是此字段不能自定义,必须符合Kubernetes的官方约束,目前我们用到的基本都是v1稳定版
- kind:指明当前的配置是什么类型,比如Pod、Service、Ingress、Node等,注意这个首字母是大写的
- metadata:用于描述当前配置的meta信息,比如name,label等
- spec:指明当前配置的具体实现
所有的Kubernetes对象基本都满足以上的格式,因此最开始Pod的YAML文件的意思是“使用v1稳定版本的API信息,类型是Pod,名称是hello-pod,具体实现是开启ProcessNamespace,有两个容器。
知道了YAML的概念,让我们在回归主题。为了解决容器单一进程问题,只创建Pod的原因之一是Google通过Pod实现了自己的容器设计模式,而Google则为Kubernetes编写了最适合的容器设计模式。
举个最常用的例子:
Java项目并不能像.Net Core项目那样编译完成后直接自宿主运行,必须要把编译生成的war包拷贝到服务宿主程序比如Tomcat的运行目录下才可以正常使用。但是在实际情况中越大的公司分工越明确,很大概率负责Java项目开发和服务宿主程序开发的团队并不是同一团队。
为了让上述情况中的两个团队可以各自独立开发并且还可以紧密合作,我们可以使用Pod解决这个问题。
下面这个yaml文件就定义了一个满足上述需求的Pod:

在这个yaml文件中,我们定义了一个java程序和tomcat程序的容器,并且对这两个容器之间的容器进行了一次挂载操作:将java程序的/app路径以及tomcat程序的/root/apache-tomcat/webapps同时挂载到了sample-volume这个挂载卷上,并且最后定了这个挂载卷就是一个内存数据卷。并且定义了java程序所在的容器是一个initContainer,说明此容器是在tomcat容器之前启动的,并且启动之后执行了一个cp的命令。
在上述Pod描述了这样一个场景:程序运行开始运行时,Java容器启动,把自己的war包sample.war拷贝到了自己的/app目录下;之后tomcat容器启动,执行启动脚本,执行的war包从自己的/root/apache-tomcat/webapps路径下获得。
可以看到通过上述的配置描述,我们既没有改动Java程序,也没有改动tomcat程序,却让它们完美的配合工作了,完成了解耦操作。这个例子就是容器设计模式中的Sidecar模式,还有很多设计模式,感兴趣的同学可以去进一步自行学习。
总结
以上介绍的就是Kubernetes为了解决紧密关系而抽象出来的概念Pod的基础内容了,需要注意的是,Pod提供的只是一种编排的思想,而不是具体的技术方案,在我们使用的Kubernetes框架中,Pod只不过是以Docker作为载体实现了而已,如果你使用的底层容器是虚拟机,比如virtlet,那这个Pod创建时就根本不需要Infra Container,因为虚拟机天生就支持多进程协同。
在说完了Pod的基础的内容,在下一节中我们将会为大家介绍在接下来的容器编排战争之中,Kubernetes又是如何脱颖而出。
以上是关于Docker与k8s的恩怨情仇——Kubernetes的创新的主要内容,如果未能解决你的问题,请参考以下文章
Docker与k8s的恩怨情仇——蓦然回首总览Kubernetes
Docker与k8s的恩怨情仇——Kubernetes的创新