Docker与k8s的恩怨情仇—用最简单的技术实现“容器”
Posted 葡萄城技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker与k8s的恩怨情仇—用最简单的技术实现“容器”相关的知识,希望对你有一定的参考价值。
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
上次我们说到PaaS的发展历史,从Cloud Foundry黯然退场,到Docker加冕,正是Docker“一点点”的改进,掀起了一场蝴蝶效应,煽动了整个PaaS开源项目市场风起云涌。
为了让大家更好的理解“容器”这个PaaS中最核心的技术,本篇将从一个进程开始,为大家讲述容器到底是什么,Cloud Foundry等PaaS“前浪”是如何实现容器的。
进程 vs 容器
以Linux操作系统为例,计算机里运行的进程是程序执行之后,从磁盘的二进制文件,到内存、寄存器、堆栈指令等等所用到的相关设备状态的一个集合,是数据和状态综合的动态表现。而容器技术的目标就是对一个进程的状态和数据进行的隔离和限制。可以说,容器的本质其实就是Linux中的一个特殊进程。这个特殊的进程,主要靠Linux系统提供的两个机制来实现,这里先回顾一下。
Namespace
Linux Namespace是Linux内核的一项功能,该功能对内核资源进行分区,以使一组进程看到一组资源,而另一组进程看到另一组资源。该功能通过为一组资源和进程具有相同的名称空间而起作用,但是这些名称空间引用了不同的资源。资源可能存在于多个空间中。此类资源的示例是进程ID,主机名,用户ID,文件名以及与网络访问和进程间通信相关的某些名称。其种类列举如下:
- Mount namespaces
- UTS namespaces
- IPC namespaces
- PID namespaces
- Network namespaces
- User namespaces
超级进程
在Linux操作系统中,PID==1的进程被称为超级进程,它是整个进程树的root,负责产生其他所有用户进程。所有的进程都会被挂在这个进程下,如果这个进程退出了,那么所有的进程都被 kill。
隔离 & 限制
刚才我们提到了隔离和限制,具体指的是什么呢?
隔离
以Docker为例(Cloud Foundry同理,我的机器上没有安装后者),我们可以执行下列的命令创建一个简单的镜像:
$ docker run -it busybox /bin/sh
这条语句执行的内容是:用docker运行一个容器,容器的镜像名称叫busybox,并且运行之后需要执行的命令是/bin/sh,而-it参数表示需要使用标准输入stdin和分配一个文本输入输出环境tty与外部交互。通过这个命令,我们就可以进入到一个容器内部了,分别在容器中和宿主机中执行top命令,可以看到以下结果:
(在容器内外执行top语句的返回结果)
从中可以发现,容器中的运行进程只剩下了两个。一个是主进程PID==1的/bin/sh超级进程,另一个是我们运行的top。而宿主机中的其余的所有进程在容器中都看不到了——这就是隔离。

(被隔离的top进程,图片来自网络)
原本,每当我们在宿主机上运行一个/bin/sh程序,操作系统都会给它分配一个进程编号,比如PID100。而现在,我们要通过Docker把这个/bin/sh程序运行在一个容器中,这时候,Docker就会在这个PID100创建时施加一个“障眼法”,让他永远看不到之前的99个进程,这样运行在容器中的程序就会当自己是PID==1的超级进程。
而这种机制,其实就是对被隔离的程序的进程空间做了手脚,虽然在容器中显示的PID1,但是在原本的宿主机中,它其实还是那个PID100的进程。所使用到的技术就是Linux中的Namespace机制。而这个机制,其实就是Linux在创建进程时的一个可选参数。在Linux中,创建一个线程的函数是(这里没写错就是线程,Linux中线程是用进程实现的,所以可以用来描述进程):
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
如果我们给这个方法添加一个参数比如CLONE_NEWPID:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
那么这个新的进程就会看到一个全新的进程空间,在这个空间里,因为该空间中仅有这一个进程,所以它自己的PID就等于1了。
这样一个过程就是Linux容器最基本的隔离实现了。
限制
光有namespace隔离的容器就和没有电脑的程序员一样,是残缺不全的。
如果我们只隔离不限制,笼子里面的程序照样占用系统资源,访问依旧自由。为了给有了隔离性的程序添加资源限制,就用到了第二个技术:cgroups
cgroups本来是google的工程师在2006年开发的一个程序,全称是Linux Control Group,是Linux操作系统中用来限制一个进程组能使用资源的上限,包括CPU、内存、磁盘、网络带宽等的功能。
通过Cgroups给用户暴露的API文件系统,用户可以通过修改文件的值来操作Cgroups功能。

(被cgroup限制的进程,图片来自网络)
在Linux系统(Ubuntu)中可以执行以下命令查看CgroupsAPI文件:
mount -t Cgroups
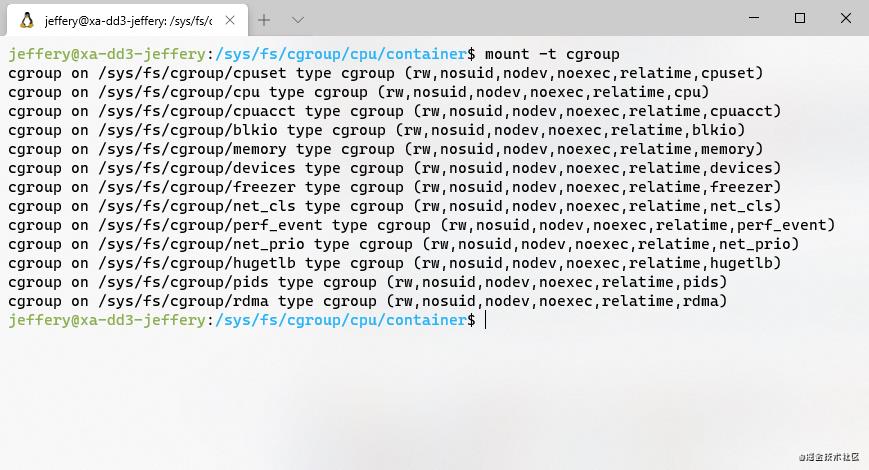
(cgroup文件系统)
从上图可以看到,系统中存在包括cpu、内存、IO等多个Cgroups配置文件。
我们以CPU为例来说明以下Cgroups这个功能。对CPU的限制需要引入两个参数cfs_period和cfs_quota,我们为了给活字格公有云Docker内的程序限制CPU时,会经常操作这两个参数。这两个参数是组合使用的,意思是在长度为cfs_period时间内,程序组只能分到总量为cfs_quota的CPU时间。也就是说cfs_quota / cfs_period == cpu使用上限。
要想限制某个进程的CPU使用,可以在/sys/fs/Cgroups/cpu目录下,执行以下命令创建一个文件夹container:
/sys/fs/Cgroups/cpu/ > mkdir container
此时,我们可以发现系统自动在container目录下生成的一系列CPU限制的参数文件,这是Linux系统自动生成的,表示我们成功为CPU创建了一个控制组container:
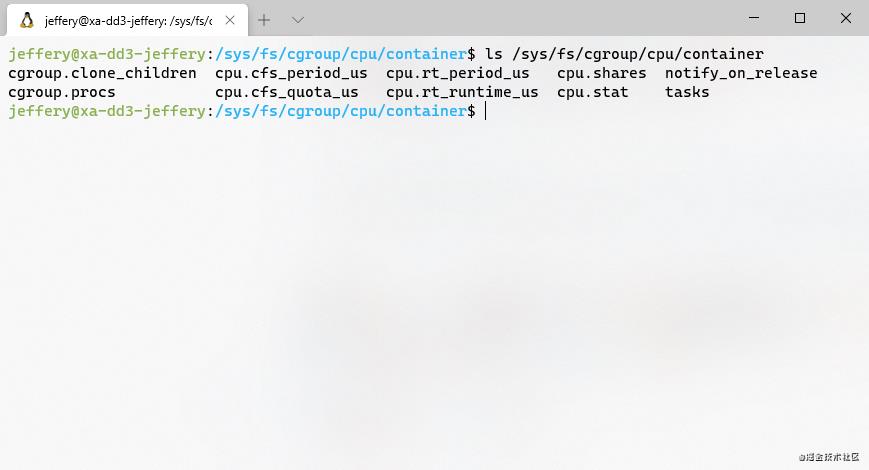
(默认的CPU资源文件列表)
为了展示CPU限制的实际效果,让我们执行一个用以下脚本创建的死循环:
while : ; do : ; done &
我们在top命令结果中会看到返回的进程为398,因为死循环,cpu占用率为100%:
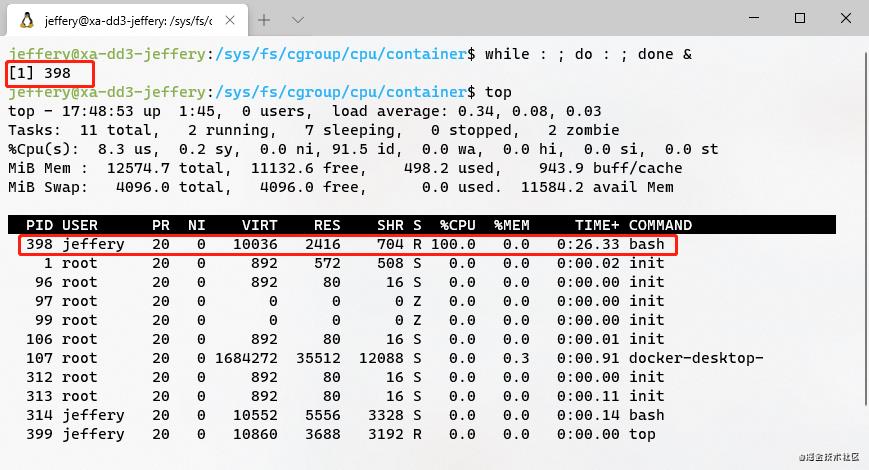
(死循环的进程占了100% CPU)
这时,我们再看下container目录下的cpu.cfs_quota_us和cpu.cfs_period_us:
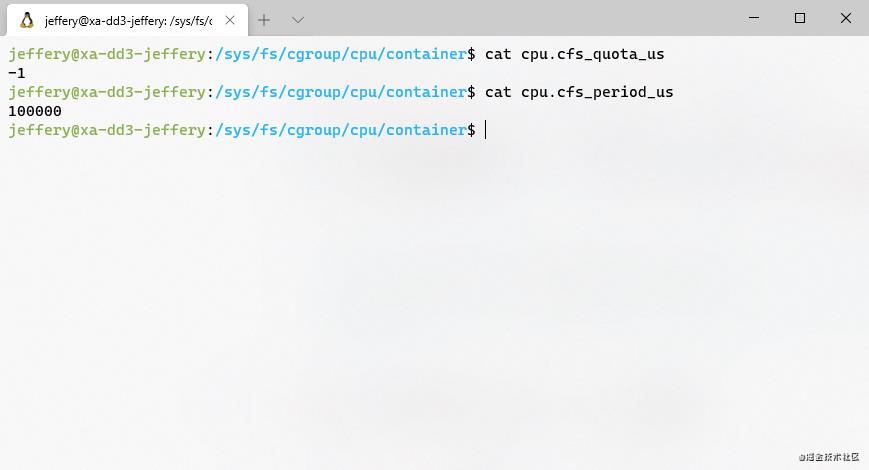
(默认情况下CPU的限制参数)
这里是没有做过限制时的样子。cfs_quota_us为-1说明并没有限制CPU的运行上限。现在我们改一下这个值:
echo 20000 > /sys/fs/Cgroups/cpu/container/cpu.cfs_quota_us
然后将之前的进程398写入这个控制组的tasks文件中:
echo 398 > /sys/fs/Cgroups/cpu/container/tasks
这时再top一下,发现刚才的死循环的CPU使用率变成20%了,CPU使用资源限制开始生效。
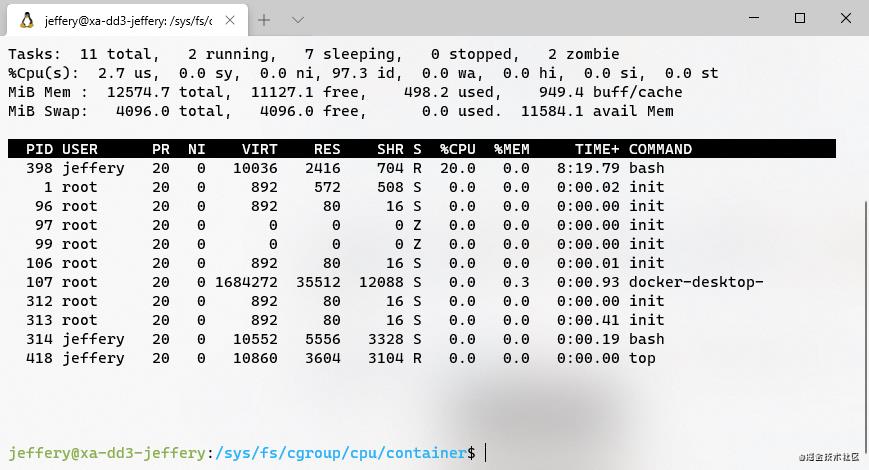
(使用cgroup限制CPU使用量的死循环进程)
以上,就是通过Cgroups功能对容器做限制的原理了。同理,我们可以用此方法,对一个进程的内存、带宽等做限制,如果这个进程是一个容器进程,一个资源受控的容器基本就可以展现在你面前了事实上,在云时代的早期,Cloud Foundry等“前浪”都是采用这种方式创建和管理容器。相比于后来者,Cloud Foundry等在容器的隔离和限制上,虽相对简单、易于理解,但在一些场景下难免会受到制约。
这里要做一个特别的说明,只有Linux中运行的容器是通过对进程进行限制模拟出来的结果,Windows和Mac下的容器,都是通过Docker Desktop等容器软件,操作虚拟机模拟出来的“真实”的虚拟容器。
小结
本节从容器的原理和Linux下实现容器隔离和限制的技术入手,介绍了在云时代早期Cloud Foundry等Paas平台的容器原理。下一节将继续为大家介绍Docker在Cloud Foundry容器基础之上又做了什么改动,是如何解决Cloud Foundry致命短板的。
如果您想了解Docker如何搅动风云,Docker的这个容器又和传统虚拟机有何区别?
敬请期待下篇,我们继续唠。
以上是关于Docker与k8s的恩怨情仇—用最简单的技术实现“容器”的主要内容,如果未能解决你的问题,请参考以下文章