大数据项目4(数据清洗与集成)
Posted 晨沉宸辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目4(数据清洗与集成)相关的知识,希望对你有一定的参考价值。
数据清洗与集成
一、概述
对数据进行清洗与集成。
具体的分为三步骤:
- 数据抽取、转换与装载
- 数据清洗
- 数据集成
二、数据抽取、转换与装载
面向数据服务(或OLAP)应用的数据库,一般不运行特别复杂的数据分析任务。为了对数据进行分析,我们从这些数据库里抽取、转换和装载(Extract, Transform and Load, ETL)数据到数据仓库中,进而在它之上运行复杂的分析负载,包括OLAP分析和数据挖掘,从数据里挖掘模式和知识,如下图:
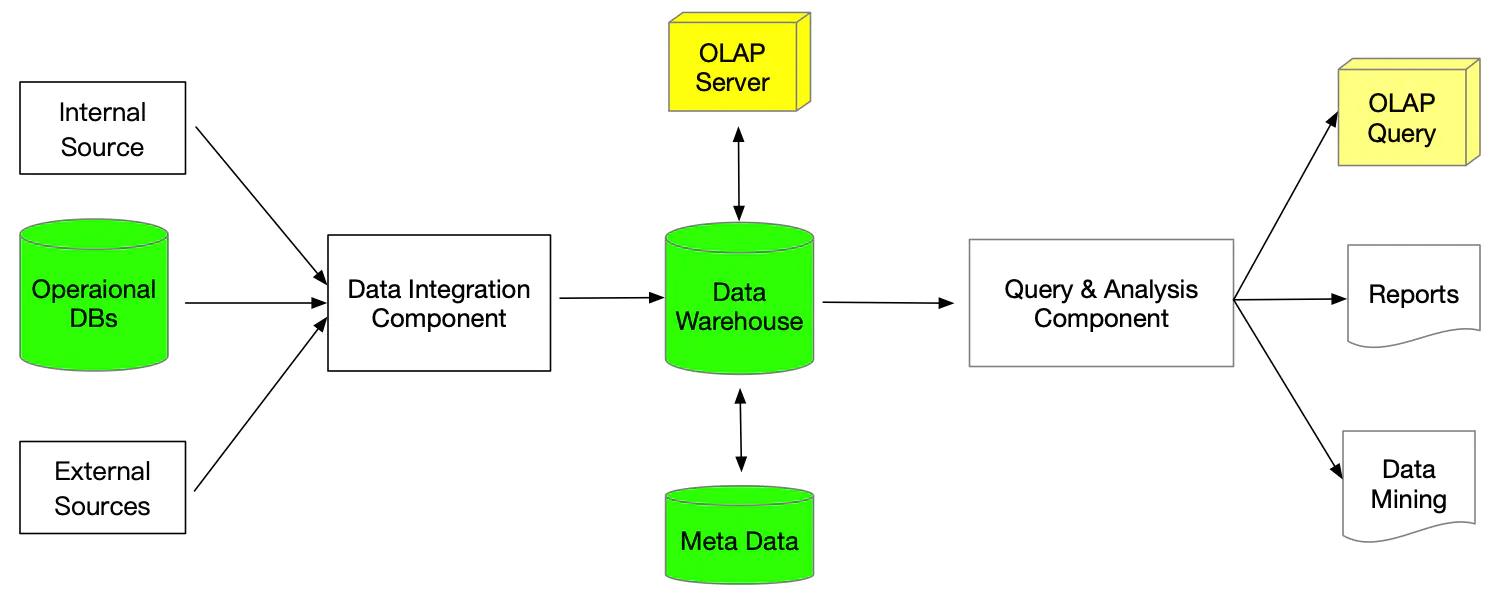
在这个过程中,如果从多个异构的数据源ETL数据到数据仓库中,而且这些数据源存在各种异构性及不致性,那么就需要对数据进行集成。所以,数据集成是从多个数据源建立统一的数据禝的一种技术。
在进行ETL操作时,如果数据源的数据质量较差,在进行数据转换时,需要利用数据清洗技术,解决数据质量问题。如果数据质量得到保证,则无须数据请洗,数据的转换操作就是比较简单的,比如进行简单的规范化处理。
三、数据清洗
1. 什么是数据清洗?
数据清洗是一种清除数据里面的错误,去掉重复数据的技术。它可以集成在ETL过程中,在从数据源建立数据仓库的过程中发挥作用,也可以直接运行在某个数据库上,数据经过清洗以后,最后还是保存到原来的数据库里。
2. 数据清洗的意义
基于准确的数据(高质量)进行分析,才有可能得到可信的分析结果,基于这些结果才有可能做出正确的决策,否则,在不准确的数据上进行分析,有可能导致错误的认识和决策。据估计,数据中的异常(Anomaly)和杂质(Impurity),一般占到数据总量的5%左右。
3. 数据质量的重要性
数据清洗往往和数据集成联系在一起,当从多个数据源进行数据集成时,通过数据清洗技术、剔除数据中的错误,以便获得高质量的数据。
四、数据异常的不同类型
数据清洗的目的是剔除数据中的异常。数据中的异常可分为三类:语法类异常(Syntactical),语义类异常(Semantic),覆盖类异常(Coverage Anomaly)
1. 语法类异常
指的是表示实体的具体的数据值和格式的错误。该类异常具体可分为三种:
- 词法错误(Lexical Error)
指的是实际数据的结构和指定的结构不一致。
比如:在一张人员表中,每个实体有四个属性,分别是姓名、年龄、性别和身高,而某些记录只有三个属性,这就是语法异常。
- 值域格式错误(Domain Format Error)
指的是实体的某个属性的取值不符合预期的值域中的某种格式。值域是数据的所有可能取值构成的集合。
比如:姓名是字符串类型,在名和姓之间有一个“,”,那么“John,Smith”是正确的值,“John Smith”则不是正确的值。
- 不规则的取值(Irregularity)
指的是对取值、单位和简称的使用不统一,不规范。
比如:员工的工资字段有的用“元”作为单位,有的用“万元”作为单位。
2. 语义类异常
指数据不能全面、无重复地表示客观世界的实体,该类异常具体可分为四种:
- 违反完整性约束规则(Integrity Constraint Violation)
指一个元组或几个元组不符合(实体完整性、参照完整性和用户自定义完整性)完整性约束规则。
比如:我们规定中工工资字段必须大于0,如果某个员工的工资小于0,就违反了完整性约束规则。 - 数据中出现矛盾(Contradiction)
指的是一个元组的各个属性取值,或者不同元组的各个属性的取值违反这些取值的依赖关系。
比如:我们的账单表里的账单金额为商品总金额减去折扣金额,但在数据库某个账单的实付金额不等于商品总金额减去折扣金额,这就矛盾了。 - 数据的重复值(Duplicate)
指的是两个或者两个以上的元组表示同一个实体。 - 无效的元组(Invalid Tuple)
指的是某些元组没有表示客观世界的有效实体。
比如:员工表中有一个员工,名称叫“王超”,但是公司里并没有这个人。
3. 覆盖类异常
值的缺失(Missing Value)。指的是在进行数据采集时就没有采集到相应的数据。
元组的缺失(Missing Tuple)。指的是在客观世界中,存在某些实体,但是并没有在数据库通过元组表示出来。
五、数据质量
数据质量是一个比较宽泛的概念,它包含很多方面;关于数据质量的评价标准,可以组织成一个层次结构,上层数据质量标准的得分是其子标准得分的一个综合加权得分。
- 正确性。指数据集里所有正确的取值相对于所有取值的比例
完整性(Integrity),可以再次分为:完备性和有效性; 一致性(Consistency),可以再次分为:模式符合性和统一性;
密度(Density),指的是所有元组里,各个属性上的缺失值占有应该存在的所有属性上的取值比例。
2. 唯一性。是指代表相同实体的重复元组占数据集里所有元组的比例。
六、数据清洗的任务和过程
数据清洗是剔除数据里的异常,使得数据集成为现实世界的准确、没有重复的表示过程。
1.步骤
数据清选的过程可以分为四个主要步骤:
- 数据审计;
- 定义数据清洗工作流;
- 执行数据清洗工作流;
- 后续处理和控制;
2. 数据清洗的具体方法
- 数据解析;
- 数据转换;
- 实施完整性约束条件;
- 重复数据清除;
- 一些统计方法;
七、 数据集成
1. 什么是数据集成?
在很多应用场合,人们需要整合不同来源的数据,才能获取有效的分析结果,否则,不完整的数据将导致分析结果不准确。
数据集成是指把数据从多个数据源整合在一起,提供一个观察这些数据的统一视图的过程。
2. 数据集成需要解决的问题
数据集成要解决的首要问题是各个数据源之间的异构性(Heterogeneity)即差异性。
数据源之间的异构性体现在以下各方面:
数据管理系统的异构性;
通信协议异构性;
数据模式的异构性;
数据类型的异构性;
取值的异构性;
语义异构性;
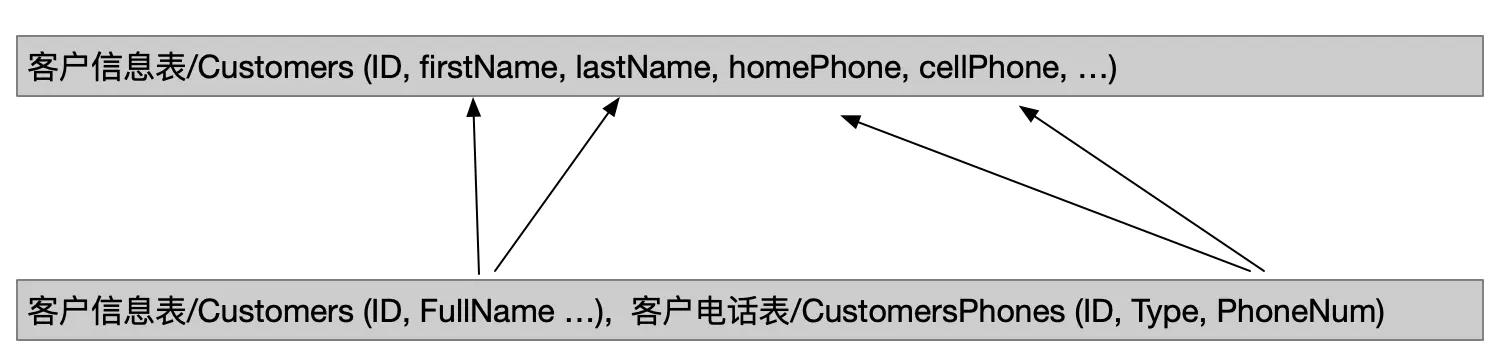
数据模式的异构性
3. 数据集成的模式
我们有三种基本的策略进行数据的集成,分别是联邦数据库(Federated Database)、数据仓库(Data Warehousing)、中介者(Mediation)。
(1). 联邦数据库模式
联邦数据库是最简单的数据集成模式,它需要在每对数据源之间创建映射(Mapping)和转换(Transform)的软件,该软件称为包装器(Wrapper)。当数据源X需要和数据源Y进行通信和数据集成时,才需要建立X和Y之间的包装器。
联邦数据库
优点:如果我们有很多的数据源,但是仅仅需要在少数几个数据源之间进行通信和集成,联邦数据库是最合算的一种模式;
缺点:如果我们需要在很多的数据源之间进行通信和数据交换,就需要建立大量的Wrapper;在n个数据源的情况下,最多需要建立(n(n-1))/2个Wrapper,这将是非常繁重的工作。如果有数据源变化,需要修改映射和转换机制,对大量的Wrapper进行更新,变得非常困难。
(2). 数据仓库模式
数据仓库是最通用的一种数据集成模式,在数据仓库模式中,数据从各个数据源拷贝过来,经过转换,然后存储到一个目标数据库中。如下图:
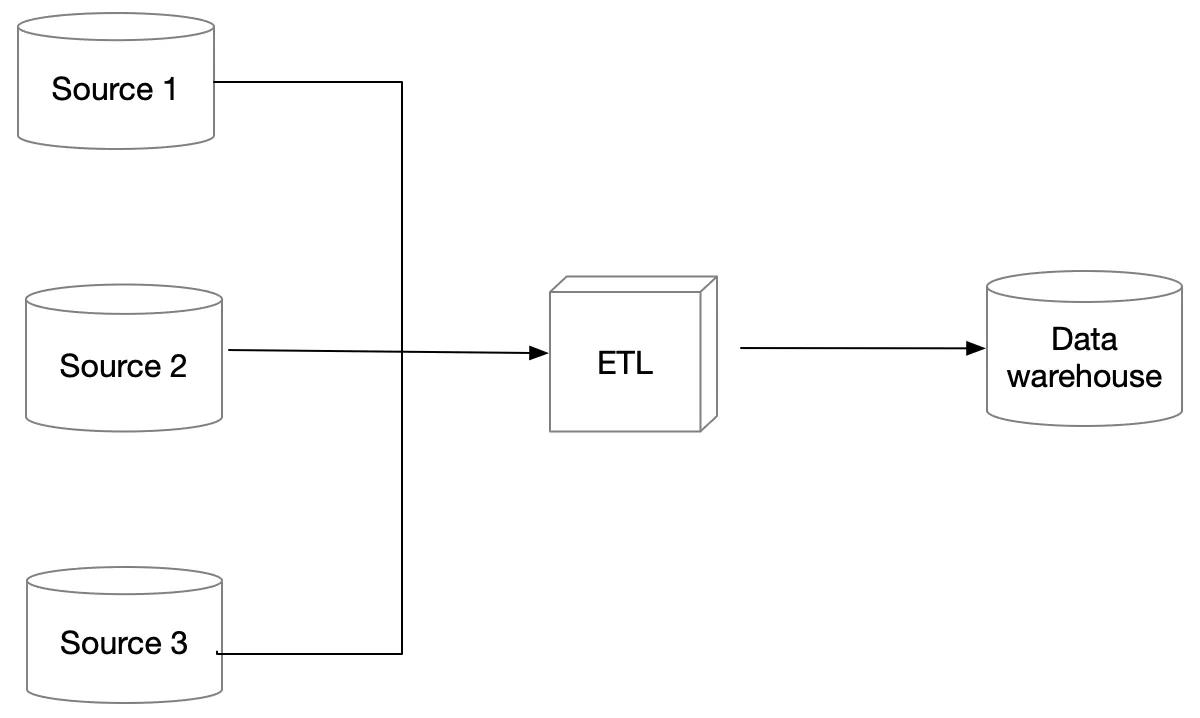
ETL:是 Extract, Transfrom, Load的缩写,ETL过程在数据仓库之外完成,数据仓库负责存储数据,以备查询。
- 数据仓库模式下,数据集成过程即是一个ETL过程,它需要解决各个数据源之间的异构性,不一致性。
数据仓库模式下,同样的数据被复制了两份:一份在数据源里;一份在数据仓库里。如何及时更新数据仓库里的数据将是需要我考虑的问题(全量更新、增量式更新)。
(3). 中介者模式
数据集成的中介者模式,如下图:
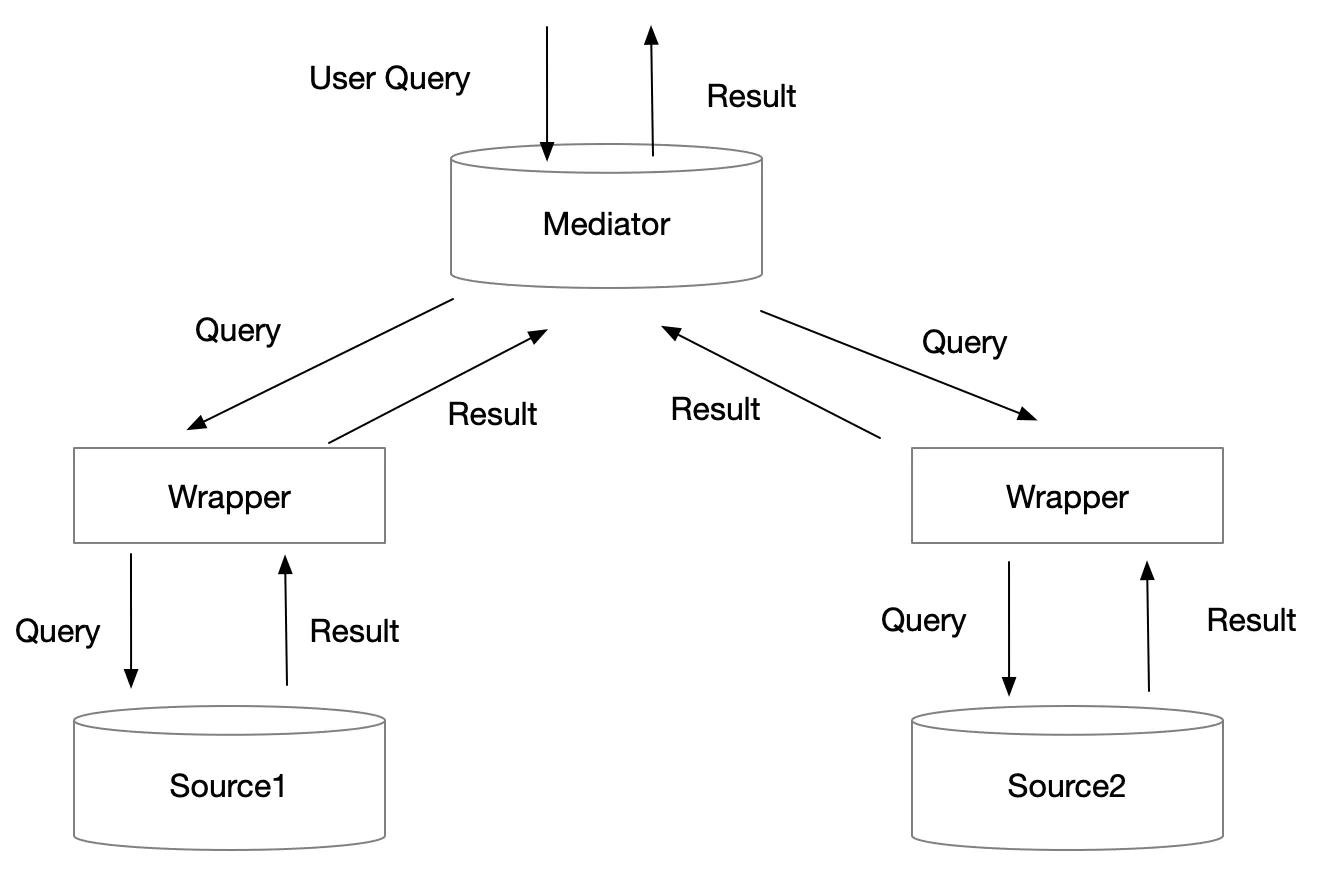
- 中介者(Mediator)扮演的是数据源的虚拟视图(Virtual
View)的角色,中介者本身不保存作保数据,数据仍然保存在数据源中。中介者维护一个虚拟的数据模式(Virtual
Schema),它把各个数据源的数据模式组合起来。 - 数据映射和传输在查询时刻(Query Time)才真正发生。
- 当用户提交查询时,查询被转换成对各个数据源的若干查询。这些查询分别发送到各个数据源,由各个数据源执行这些查询并返回结果。各个数据源返回的结果经合并(Merge)后,返回给最终用户。
以上是关于大数据项目4(数据清洗与集成)的主要内容,如果未能解决你的问题,请参考以下文章