大数据项目之数仓相关知识
Posted DB架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目之数仓相关知识相关的知识,希望对你有一定的参考价值。
第1章 数据仓库概念
数据仓库(DW): 为企业指定决策,提供数据支持的,帮助企业,改进业务流程,提高产品质量等。
DW的输入数据通常包括:业务数据,用户行为数据和爬虫数据等
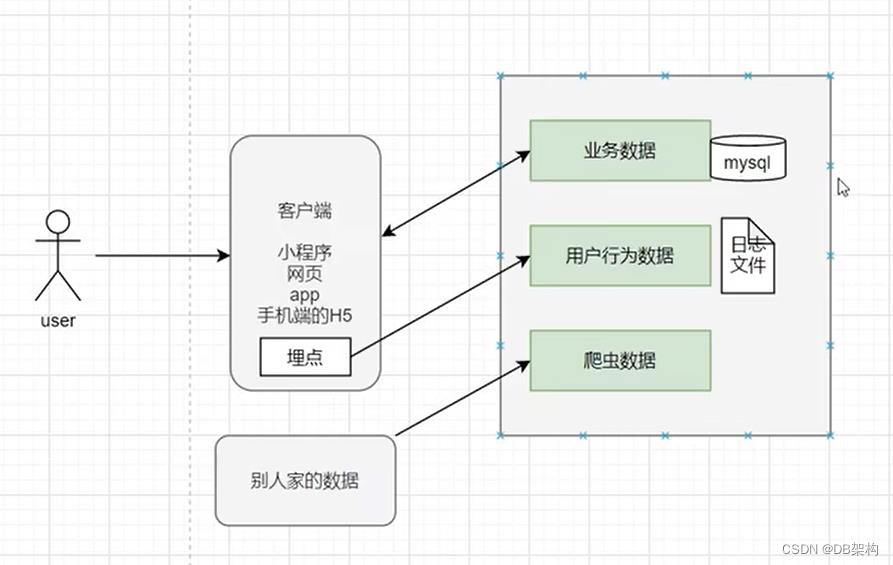
 ODS: 数据备份
ODS: 数据备份
DWD:数据清洗
DWS: 预先聚合
ADS: 统计数据

何为数仓DW
Data warehouse(可简写为DW或者DWH)数据仓库,是在数据库已经大量存在的情况下,它是一整套包括了etl、调度、建模在内的完整的理论体系。
数据仓库的方案建设的目的,是为前端查询和分析作为基础,主要应用于OLAP(on-line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。目前行业比较流行的有:AWS Redshift,Greenplum,Hive等。
数据仓库并不是数据的最终目的地,而是为数据最终的目的地做好准备,这些准备包含:清洗、转义、分类、重组、合并、拆分、统计等
主要特点
- 面向主题
- 操作型数据库组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。
- 主题是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通过与多个操作型信息系统相关。
- 集成
- 需要对源数据进行加工与融合,统一与综合
- 在加工的过程中必须消除源数据的不一致性,以保证数据仓库内的信息时关于整个企业的一致的全局信息。(关联关系)
- 不可修改
- DW中的数据并不是最新的,而是来源于其他数据源
- 数据仓库主要是为决策分析提供数据,涉及的操作主要是数据的查询
- 与时间相关
- 处于决策的需要数据仓库中的数据都需要标明时间属性
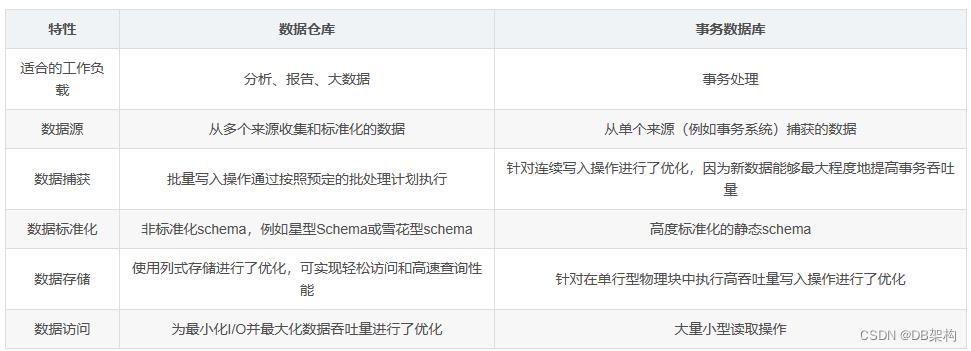
与数据库的对比
- DW:专门为数据分析设计的,涉及读取大量数据以了解数据之间的关系和趋势
- 数据库:用于捕获和存储数据
为何要分层
数据仓库中涉及到的问题:
- 为什么要做数据仓库?
- 为什么要做数据质量管理?
- 为什么要做元数据管理?
- 数仓分层中每个层的作用是什么?
在实际的工作中,我们都希望自己的数据能够有顺序地流转,设计者和使用者能够清晰地知道数据的整个声明周期,比如下面左图。
但是,实际情况下,我们所面临的数据状况很有可能是复杂性高、且层级混乱的,我们可能会做出一套表依赖结构混乱,且出现循环依赖的数据体系,比如下面的右图。
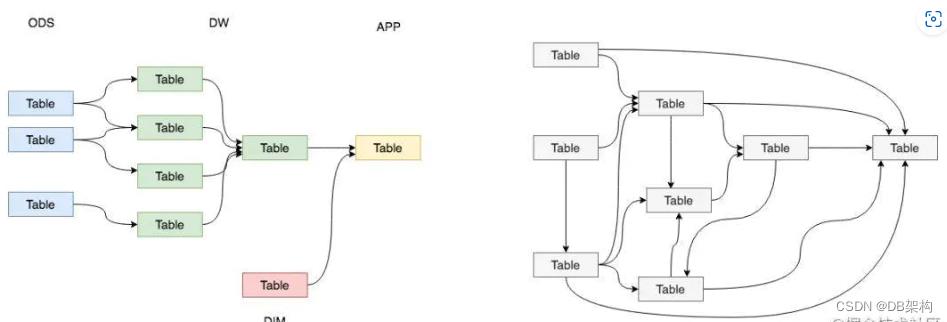
为了解决我们可能面临的问题,需要一套行之有效的数据组织、管理和处理方法,来让我们的数据体系更加有序,这就是数据分层。数据分层的好处:
- 清晰数据结构:让每个数据层都有自己的作用和职责,在使用和维护的时候能够更方便和理解
- 复杂问题简化:将一个复杂的任务拆解成多个步骤来分步骤完成,每个层只解决特定的问题
- 统一数据口径:通过数据分层,提供统一的数据出口,统一输出口径
- 减少重复开发:规范数据分层,开发通用的中间层,可以极大地减少重复计算的工作
数据分层
每个公司的业务都可以根据自己的业务需求分层不同的层次;目前比较成熟的数据分层:数据运营层ODS、数据仓库层DW、数据服务层ADS(APP)。
数据运营层ODS
数据运营层:Operation Data Store 数据准备区,也称为贴源层。数据源中的数据,经过抽取、洗净、传输,也就是ETL过程之后进入本层。该层的主要功能:
- ODS是后面数据仓库层的准备区
- 为DWD层提供原始数据
- 减少对业务系统的影响
在源数据装入这一层时,要进行诸如去噪(例如有一条数据中人的年龄是 300 岁,这种属于异常数据,就需要提前做一些处理)、去重(例如在个人资料表中,同一 ID 却有两条重复数据,在接入的时候需要做一步去重)、字段命名规范等一系列操作。
但是为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据也可以,根据业务具体分层的需求来做。
这层的数据是后续数据仓库加工数据的来源。数据来源的方式:
- 业务库
- 经常会使用sqoop来抽取,例如每天定时抽取一次。
- 实时方面,可以考虑用canal监听mysql的binlog,实时接入即可。
- 埋点日志
- 日志一般以文件的形式保存,可以选择用flume定时同步
- 可以用spark streaming或者Flink来实时接入
- kafka也OK
- 消息队列:即来自ActiveMQ、Kafka的数据等。
数据仓库层
数据仓库层从上到下,又可以分为3个层:数据细节层DWD、数据中间层DWM、数据服务层DWS。
数据细节层DWD
数据细节层:data warehouse details,DWD(数据清洗/DWI)
该层是业务层和数据仓库的隔离层,保持和ODS层一样的数据颗粒度;主要是对ODS数据层做一些数据的清洗和规范化的操作,比如去除空数据、脏数据、离群值等。
为了提高数据明细层的易用性,该层通常会才采用一些维度退化方法,将维度退化至事实表中,减少事实表和维表的关联。
数据中间层DWM
数据中间层:Data Warehouse Middle,DWM
该层是在DWD层的数据基础上,对数据做一些轻微的聚合操作,生成一些列的中间结果表,提升公共指标的复用性,减少重复加工的工作。
简答来说,对通用的核心维度进行聚合操作,算出相应的统计指标
数据服务层DWS
数据服务层:Data Warehouse Service,DWS(宽表-用户行为,轻度聚合)
该层是基于DWM上的基础数据,整合汇总成分析某一个主题域的数据服务层,一般是宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来说,该层的数据表会相对较少;一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
- 用户行为,轻度聚合对DWD
- 主要对ODS/DWD层数据做一些轻度的汇总。
数据应用层ADS
数据应用层:Application Data Service,ADS(APP/DAL/DF)-出报表结果
该层主要是提供给数据产品和数据分析使用的数据,一般会存放在ES、Redis、PostgreSql等系统中供线上系统使用;也可能存放在hive或者Druid中,供数据分析和数据挖掘使用,比如常用的数据报表就是存在这里的。
事实表 Fact Table
事实表是指存储有事实记录的表,比如系统日志、销售记录等。事实表的记录在不断地增长,比如电商的商品订单表,就是类似的情况,所以事实表的体积通常是远大于其他表。
维表层Dimension(DIM)
维度表(Dimension Table)或维表,有时也称查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联,相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。维度表主要是包含两个部分:
- 高基数维度数据:一般是用户资料表、商品资料表类似的资料表,数据量可能是千万级或者上亿级别
- 低基数维度数据:一般是配置表,比如枚举字段对应的中文含义,或者日期维表等;数据量可能就是个位数或者几千几万。
临时表TMP
每一层的计算都会有很多临时表,专设一个DWTMP层来存储我们数据仓库的临时表
数据集市
狭义ADS层; 广义上指hadoop从DWD DWS ADS 同步到RDS的数据
数据集市(Data Mart),也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
从范围上来说,数据是从企业范围的数据库、数据仓库,或者是更加专业的数据仓库中抽取出来的。数据中心的重点就在于它迎合了专业用户群体的特殊需求,在分析、内容、表现,以及易用方面。数据中心的用户希望数据是由他们熟悉的术语表现的。
带有数据集市的数据仓储结构
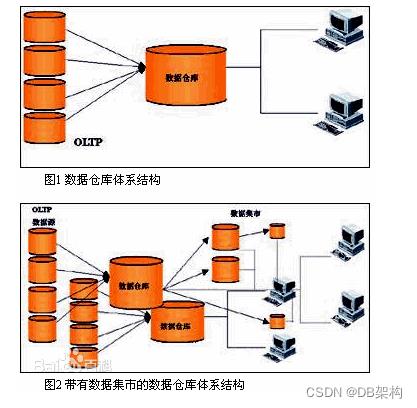
区别数据仓库
数据集市就是企业级数据仓库的一个子集,它主要面向部门级业务,并且只面向某个特定的主题。为了解决灵活性与性能之间的矛盾,数据集市就是数据仓库体系结构中增加的一种小型的部门或工作组级别的数据仓库。数据集市存储为特定用户预先计算好的数据,从而满足用户对性能的需求。数据集市可以在一定程度上缓解访问数据仓库的瓶颈。
理论上讲,应该有一个总的数据仓库的概念,然后才有数据集市。实际建设数据集市的时候,国内很少这么做。国内一般会先从数据集市入手,就某一个特定的主题(比如企业的客户信息)先做数据集市,再建设数据仓库。数据仓库和数据集市建立的先后次序之分,是和设计方法紧密相关的。而数据仓库作为工程学科,并没有对错之分。
在数据结构上,数据仓库是面向主题的、集成的数据的集合。而数据集市通常被定义为星型结构或者雪花型数据结构,数据集市一般是由一张事实表和几张维表组成的。

ETL
ETL :Extract-Transform-Load,用于描述将数据从来源端经过抽取、转换、加载到目的端的过程。
宽表
含义:指字段比较多的数据库表。通常是指业务主体相关的指标、纬度、属性关联在一起的一张数据库表。
特点:
宽表由于把不同的内容都放在同一张表,宽表已经不符合三范式的模型设计规范:
- 坏处:数据有大量冗余
- 好处:查询性能的提高和便捷
宽表的设计广泛应用于数据挖掘模型训练前的数据准备,通过把相关字段放在同一张表中,可以大大提供数据挖掘模型训练过程中迭代计算的消息问题。
主题(Subject)
是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。
第2章 项目需求及架构设计
2.1 项目需求分析
1)采集平台
(1) 用户行为数据采集平台搭建。
(2)业务数据采集平台搭建
2)离线需求
电商离线指标体系.xlsx

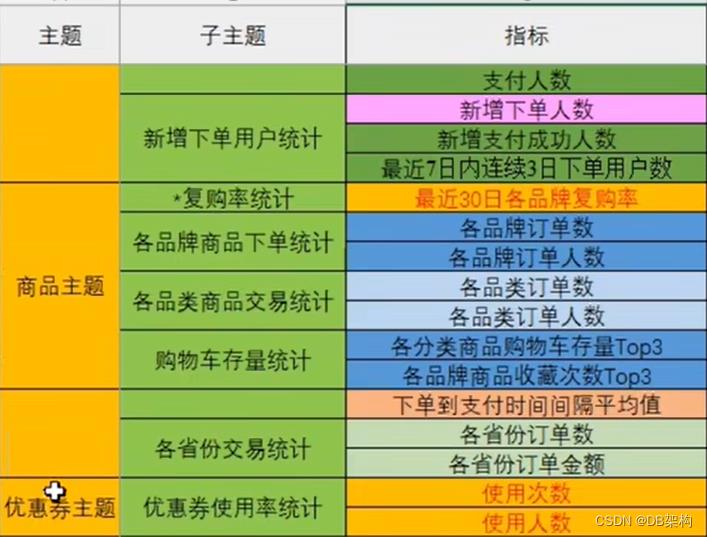
3) 实时需求
电商实时指标体系.xlsx




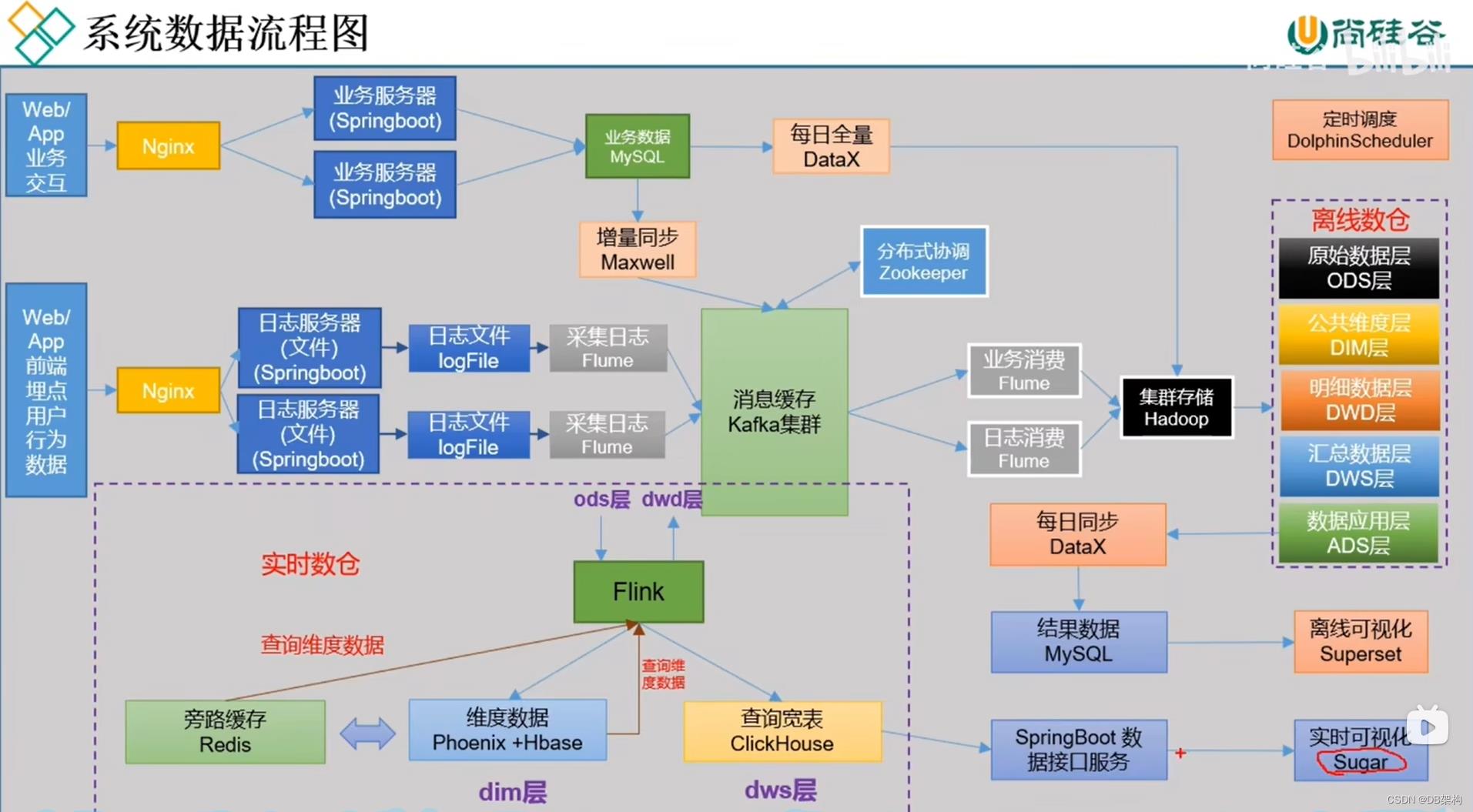
技术选型
技术选型主要考虑因素: 数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算。

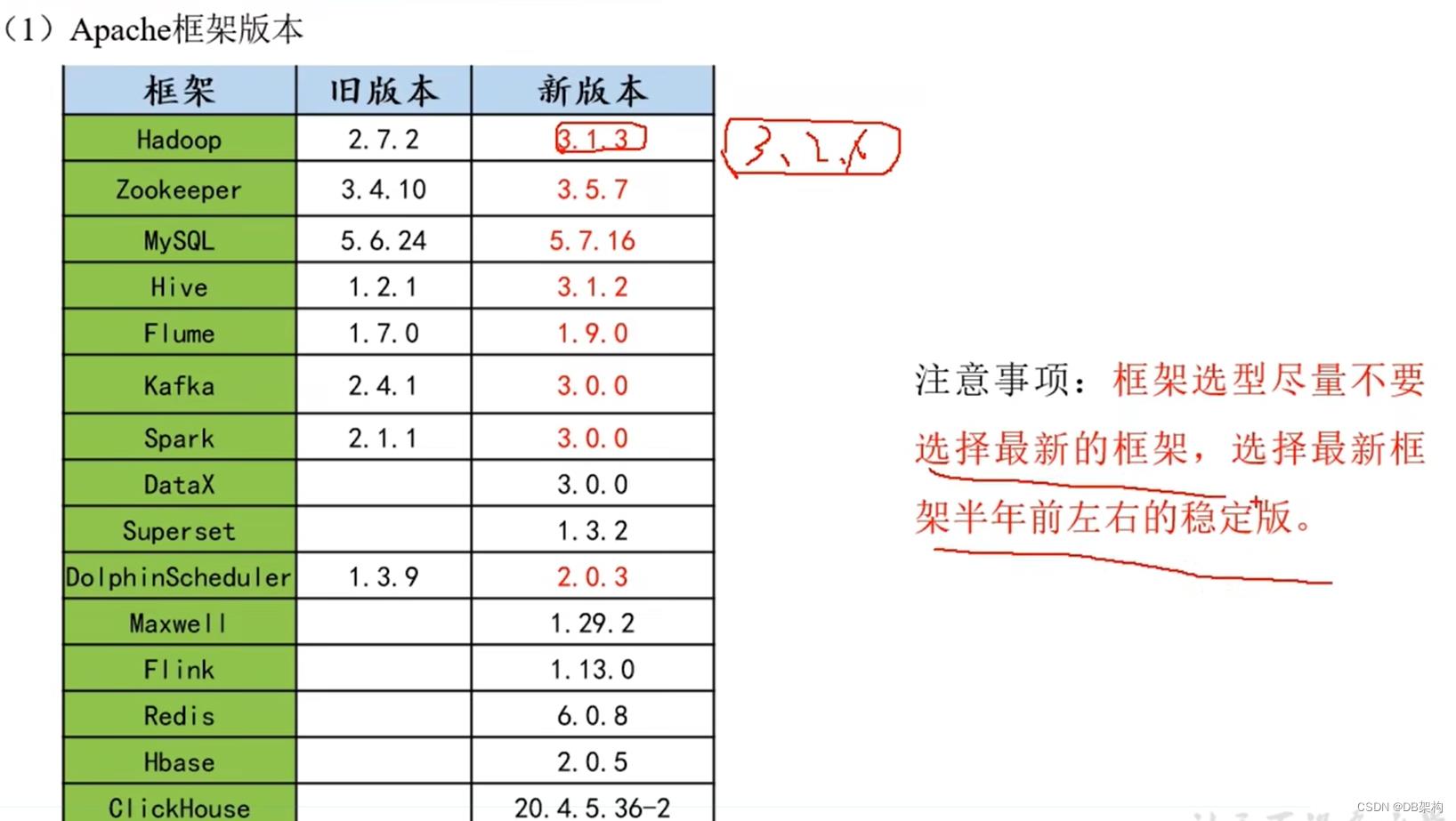
2.2.3框架版本的选型
框架发行版本选型






第3章 用户行为日志
3.1 用户行为日志概述

3.2 用户行为日志内容
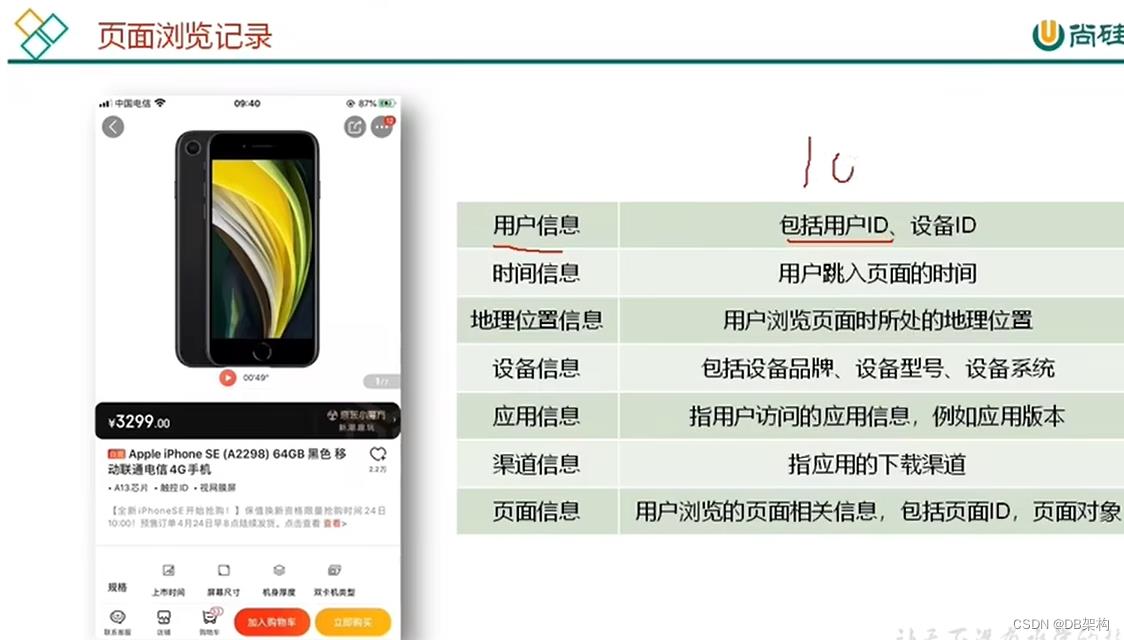
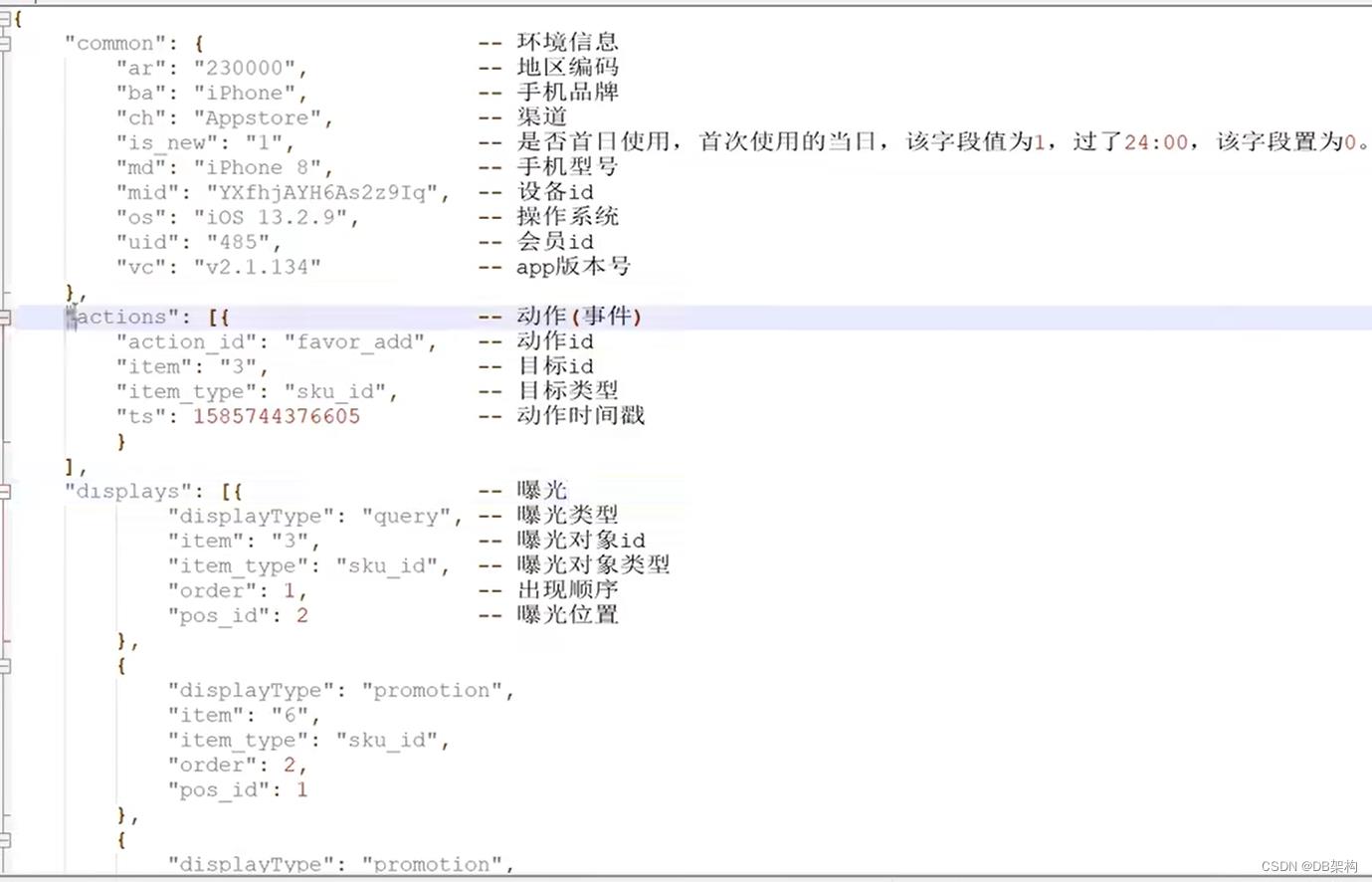
本项目收集和分析的用户行为信息主要有页面浏览记录、动作记录、曝光记录、启动记录和错误记录。

页面浏览记录
动作记录
曝光记录
启动记录

错误记录

3.3 用户行为日志格式
日志结构 : 页面日志 + 启动日志
3.3.1 页面日志


3.3.2 启动日志



此博文为学习汇总,多为学习课程视频以及相关博客中的资料汇集而成。若有不妥,请及时联系。
以上是关于大数据项目之数仓相关知识的主要内容,如果未能解决你的问题,请参考以下文章