大数据项目1(数据预处理问题)
Posted 晨沉宸辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目1(数据预处理问题)相关的知识,希望对你有一定的参考价值。
数据预处理
一、了解什么是预处理
数据预处理就是一种数据挖掘技术,本质就是为了将原始数据转换为可以理解的格式或者符合我们挖掘的格式。
二、为什么要进行预处理
在真实世界中,数据通常是不完整的(缺少某些感兴趣的属性值)、不一致的(包含代码或者名称的差异)、极易受到噪声(错误或异常值)的侵扰的。因为数据库太大,而且数据集经常来自多个异种数据源,低质量的数据将导致低质量的挖掘结果。
三、数据预处理基本方法
1、基础方法
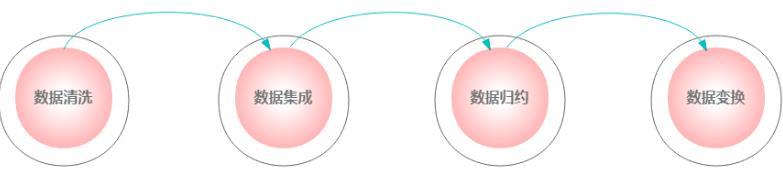
- 数据清洗: 填写缺失的值,光滑噪声数据,识别或删除离群点,并解决不一致性来“清理数据”;
- 数据集成:使用多个数据库,数据立方体或文件;
- 数据归约: 用替代的,较小的数据表示形式替换元数据,得到信息内容的损失最小化,方法包括维规约,数量规约和数据压缩;
- 数据变换:将数据变换成使用挖掘的形式。
形象化:

四、应用
用 Python 来处理,还需要用到两个库,分别是 Numpy、Pandas。
1.准备数据
有一个数据集,其中包括IT专业人员的信息,比如国家、工资、性别,如下:
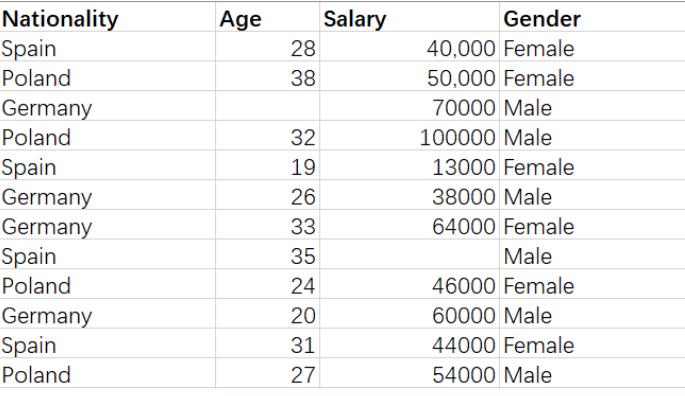
我们可以随意创建此数据集的副本。
我们可以观察到上面的数据集包含一些空值
2.导入库
Numpy 库包含数学工具,它可以用于在我们代码中的任何类型的数学;
Pandas 库用于导入和管理数据集。
导入库的方法:
import pandas as pd
import numpy as np
3.导入数据集
我将我的数据集文件命名为‘profess’,它的格式为.csv。
#读取数据(我的数据集文件跟我的python文件在同一目录下)
data = pd.read_csv("profess.csv")
导入数据集后,我们输出看下它的格式如何:
print(data)
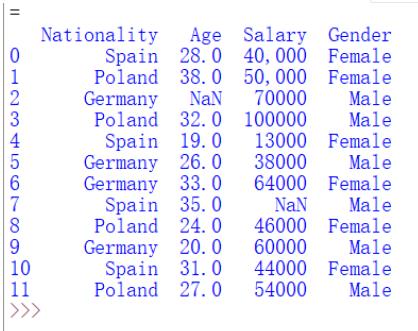
4. 数据清洗——查看缺失值
用 Pandas 库的 isnull 函数来看看。
print(data.isnull().sum())

Age,Salary 列都有缺失值(就是为空的值),缺失值数量都为1。处理缺失值有7种处理方法,我们这里说说比较常用的两种。
(1)处理普通空值
如果某行有特定特征d的空值,就删除此行。如果特定列具有超过75%的缺失值,就删除特定列。不过我们要在确保样本数据足够多的情况下,采用这个方法。因为我们要确保删除数据后,不会增加偏差。
data.dropna(inplace=True)
print(data.isnull().sum())

(2)处理年龄年份金额等数据
这个方法适用于具有年份或者年龄,金额等数字数据的功能。我们可以计算特征的均值,中值或众数,将其替换为缺失值。与第一种方法相比,这种可以抵消数据的缺失,产生更好的效果。
我们用来看一下操作:
# 将 Age 列中为空的值替换为 Age 的中位数。
# medain()是 pandas 库的求中位数的方法
data['Age'] = data['Age']
.replace(np.NaN,data['Age']
.median())
print(data['Age'])
5. 数据归约
为了满足挖掘需求,我们需要知道这些工程师们的薪水分布区间,但是我们只有‘Salary’ 薪水这一列,所以为了方便挖掘,我们给我们的数据集增加‘薪水等级’ level 这一列,通过 Salary 列进行区间归约,这种方法叫做“属性构造”。我们看看操作:
**#数据归约
def section(d):
if 50000 > d:
return "50000以下"
if 100000 > d >= 5000:
return "50000-100000"
if d > 100000:
return "100000以上"
data['level'] = data['Salary']
.apply(lambda x: section(x))
print(data['level'])**

我们定义一个‘数据变换’的函数给,根据 Salary 判断选择区间进行变换并赋值给 level。
6. 数据变换
我们可以看到 Salary 列也有空值,从业务上理解它应该是数字数值才是。但是我们发现我们的数据集中是货币格式,我们需要对它进行‘数据变换’,转换成我们所需的数字格式。来看下实际操作:
#数据变换
def convert_currency(d):
new_value = str(d).replace(",","")
.replace("$","")
return float(new_value)
data['Salary'] = data['Salary'].apply(convert_currency)
# mean()是 pandas 库的求平均值的方法
data['Salary'] = data['Salary']
.replace(np.NaN,data['Salary']
.mean())
print(data['Salary'])
变换成功:
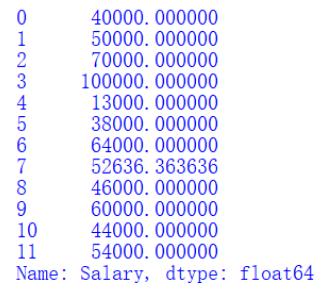
我们定义一个“数据变换”的函数,然后将它应用再 Salary 列上,最后同数据清洗那一步同样的替换操作,我们这里用平均值替换。
以上是关于大数据项目1(数据预处理问题)的主要内容,如果未能解决你的问题,请参考以下文章