操作手册 : Stream 流处理手册 (赶紧收藏)
Posted JAVA炭烧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作手册 : Stream 流处理手册 (赶紧收藏)相关的知识,希望对你有一定的参考价值。
一 .前言
Java 流这个特性已经出来很久了 , 可以大大的减少我们的代码 , 而且并行处理可以在某些场景下使用多个处理器核心可以大大的提高性能.
不过 Stream 语法新手使用起来还是会有一定的难度 , 这一篇文档由浅到深看一下这个特性.
这是开篇 , 只记录之前梳理的用法 , 下一篇来看源码 , 记得收藏!!!
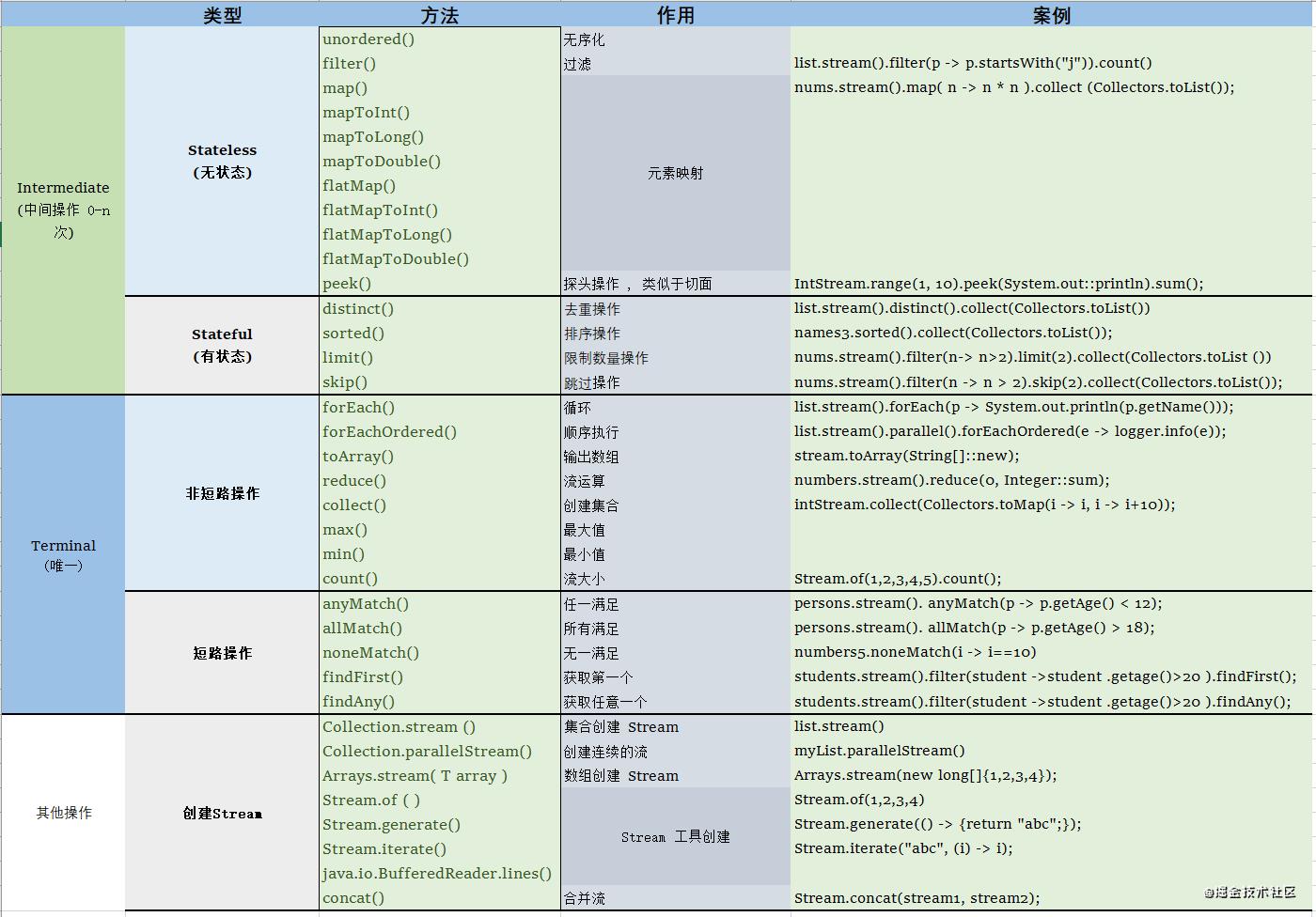
Stream 的特点
- Stream 不是集合 , 也不是数据结构 , 不可以保存数据
- Stream 有点类似于高级 的 Iterator , 可以用于算法和计算
- 不同于迭代器 , Stream 可以并行化操作 , 数据被分为很多段 , 在不同的线程中进行处理
- 数据源、零个或多个中间操作 ( intermediate ) 以及零个或一个终端操作 (terminal )
- 所有中间操作都是惰性的 , 在管道开始工作之前,任何操作都不会产生任何效果
- 终端操作有点像水龙头 , 开启了水龙头后 , 水才会流动 , 中间操作才会执行
二. 基础知识
2.1 结构运算
2.1.1 双冒号运算
双冒号运算就是将方法当成参数传递给需要的方法 ( Stream ) , 即为方法引用
案例一 : 基础用法
x -> System.out.println(x)
// ------------
System.out::println
案例二 : 复杂用法
for (String item: list) {
AcceptMethod.printValur(item);
}
//------------------
list.faorEach(AcceptMethod::printValur);
2.2 流的创建
2.2.1 集合和数组工具
基础案例
// Collection 工具
Collection.stream () : list.stream();
Stream.<String>builder().add("a").add("b").add("c").build();
Stream.of("a", "b", "c")
Stream.generate(() -> "element").limit(10);
Stream.iterate(40, n -> n + 2).limit(20);
创建一个整数流
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum);
IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum);
// 其他的基本类型案例
LongStream.rangeClosed(1, 3);
创建一个并行流
// API :
Stream<E> parallelStream()
// 案例 :
Collection.parallelStream ()
listOfNumbers.parallelStream().reduce(5, Integer::sum);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);
数组创建流
Arrays.stream(intArray).reduce(0, Integer::sum);
Arrays.stream(intArray).parallel().reduce(0, Integer::sum);
Arrays.stream(integerArray).reduce(0, Integer::sum);
Arrays.stream(integerArray).parallel().reduce(0, Integer::sum);
合并流
// API : 组合2个 Streams
<T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
// 案例
Stream<Integer> stream1 = Stream.of(1, 3, 5);
Stream<Integer> stream2 = Stream.of(2, 4, 6);
Stream<Integer> resultingStream = Stream.concat(stream1, stream2);
// 案例 : 合并三个
Stream.concat(Stream.concat(stream1, stream2), stream3);
// 案例 : stream of 合并流
Stream.of(stream1, stream2, stream3, stream4)
其他的案例
// 静态工厂
1. Java.util.stream.IntStream.range ( )
2. Java.nio.file.Files.walk ( )
// 手动创建
1. java.util.Spliterator
2. Random.ints()
3. BitSet.stream()
4. Pattern.splitAsStream(java.lang.CharSequence)
5. JarFile.stream()
// java.io.BufferedReader.lines()
Files.lines(path, Charset.forName("UTF-8"));
Files.lines(path);
补充
分割流案例
2.3 流的操作
一个流可以有多个 intermediate 操作 , 和一个 Terminal 操作 , 当 Terminal 执行完成后, 流就结束了
2.3.1 流的 Intermediate 操作
map : 元素映射
// API :
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
// Map 传入方法函数 , Map 返回的是一个 object
books.stream().filter(e -> "Effective Java".equals(e.getValue())).map(Map.Entry::getKey).findFirst();
wordList.stream().map(String::toUpperCase).collect(Collectors.toList());
Stream.of(1, 2, 3).map(n -> n + 1).collect(Collectors.toList());
nums.stream().map( n -> n * n ).collect (Collectors.toList());
flatMap
// flatMap 返回的是一个 Stream
Stream<List<String>> namesOriginalList = Stream.of(
Arrays.asList("Pankaj"),
Arrays.asList("David", "Lisa"),
Arrays.asList("Amit"));
//flat the stream from List<String> to String stream
Stream<String> flatStream = namesOriginalList
.flatMap(strList -> strList.stream());
flatStream.forEach(System.out::println);
mapToXXX
// API :
IntStream mapToInt(ToIntFunction<? super T> mapper)
// 作用 : mapToXXX 主要用于转换为
doubleNumbers.stream().mapToDouble(Double::doubleValue).sum();
customers.stream().mapToInt(Customer::getAge).filter(c -> c > 65).count();
intStream1.mapToObj(c -> (char) c);
filter : 过滤 ,通过过滤的元素被流下来生成新的 stream
// Predicate 是一个函数式接口
Stream<T> filter(Predicate<? super T> predicate)
// filter 中使用箭头表达式
- tream<Integer> oddIntegers = ints.stream().filter(i -> i.intValue() % 2 != 0);
- list.stream().filter(p -> p.startsWith("j")).count()
// Filter 中使用 :: 双冒号
customers.stream().filter(Customer::hasOverHundredPoints).collect(Collectors.toList());
// Filter 中使用代码块
customers.stream().filter(c -> {
try {
return c.hasValidProfilePhoto();
} catch (IOException e) {
//handle exception
}
return false;
}).collect(Collectors.toList());
distinct : 去重
nums.stream().filter(num -> num % 2 == 0).distinct().collect(Collectors.toList());
list.stream().distinct().collect(Collectors.toList())
sorted : 排序
// 自定义排序方式
persons.stream().limit(2).sorted((p1, p2) -> p1.getName().compareTo(p2.getName())).collect(Collectors.toList());
// 使用指定 Comparator 提供的排序器
List<String> reverseSorted = names2.sorted(Comparator.reverseOrder()).collect(Collectors.toList());
// 不传入参数使用默认排序方式
List<String> naturalSorted = names3.sorted().collect(Collectors.toList());
peek
// API : 可以用于调试 ,主要在流通过管道中的某个点时进行拦截
Stream<T> peek(Consumer<? super T> action)
// 案例 :
IntStream.range(1, 10).peek(System.out::println).sum();
// 在多个拦截点拦截
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
limit : 限制
// API : 截断流的数量 , 可以看到还是返回一个流
Stream<T> limit(long maxSize);
// 案例 :
nums.stream().filter(n-> n>2).limit(2).collect(Collectors.toList ())
skip : 跳过
// API :
Stream<T> skip(long n);
// 案例 :
nums. stream() .filter(n-> n>2 ).skip (2) . collect( Collectors . toList () );
parallel 并行流
// API : 返回一个并行的等效流 , 如果已经是并行 ,返回自身
S parallel()
boolean isParallel()
// 案例 :
Object[] listOutput = list.stream().parallel().toArray();
sequential : 串行流
// API :
S sequential();
// 案例 :
Arrays.asList(1, 2, 3, 4).stream().sequential();
unordered : 无序化
// 消除相遇顺序 , 可以提交并行性能
IntStream.range(1, 1_000_000).unordered().parallel().distinct().toArray();
2.3.2 流的 Terminal 操作之聚合
foreach : 循环遍历
// API : 可以看到 , 这里接受到的是一个 Consumer 函数
void forEach(Consumer<? super T> action);
// foreach 中使用箭头函数
roster.stream().forEach(p -> System.out.println(p.getName()));
forEachOrdered : 有序的循环流
list.stream().parallel().forEachOrdered(e -> logger.info(e));
Array
stream.toArray(String[]::new);
//reduce : 把 Stream 元素组合起来
Stream.of("A", "B", "C", "D").reduce("", String::concat);
// reduce 求和
Stream.of(5, 6, 7, 8).reduce(0, (accumulator, element) -> accumulator + element);
?--- reduce 后面的参数 : 第一个默认值 , 后面是传入的方法
// min : 将字符串数组求最大值
Stream.of(testStrings).max((p1, p2) -> Integer.compare(p1.length(), p2.length()));
// max : 获得最大长度
br.lines().mapToInt(String::length).max().getAsInt();
collection
- stream.collect(Collectors.toList()) : toList把流中所有的元素收集到List 中
- stream.collect(Collectors.toCollection(ArrayList::new)): 把流中的元素收集到给定的供应源创建的集合中
- stream.collect(Collectors.toSet()) : 把流中所有的元素保存到Set集合中,删除重复锁
- stream.collect(Collectors.toCollection(Stack::new))
// API
<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
Map<String, Integer> hashMap = list.stream().collect(Collectors
.toMap(Function.identity(), String::length));
Map<String, Integer> linkedHashMap = list.stream().collect(Collectors.toMap(
Function.identity(),
String::length,
(u, v) -> u,
LinkedHashMap::new
));
// 创建 Collection 对象
Stream<Integer> intStream = Stream.of(1,2,3,4);
List<Integer> intList = intStream.collect(Collectors.toList());
System.out.println(intList); //prints [1, 2, 3, 4]
intStream = Stream.of(1,2,3,4); //stream is closed, so we need to create it again
Map<Integer,Integer> intMap = intStream.collect(Collectors.toMap(i -> i, i -> i+10));
System.out.println(intMap); //prints {1=11, 2=12, 3=13, 4=14}
// 创建 Array 对象
Stream<Integer> intStream = Stream.of(1,2,3,4);
Integer[] intArray = intStream.toArray(Integer[]::new);
System.out.println(Arrays.toString(intArray)); //prints [1, 2, 3, 4]
// String 操作
stream.collect(Collectors.joining()).toString();
list.stream().collect(Collectors.joining(" | ")) : 连接符中间穿插
list.stream().collect(Collectors.joining(" || ", "Start--", "--End")) : 连接符中间及前后
// 创建为 Map
books.stream().collect(Collectors.toMap(Book::getIsbn, Book::getName));
// ps : Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,Function<? super T, ? extends U> valueMapper)
2.3.3 流的 Terminal 操作之运算
min : 返回此流的最小元素
// API
Optional<T> min(Comparator<? super T> comparator)
Collector<T, ?, Optional<T>> minBy(Comparator<? super T> comparator)
// 案例 :
list.stream().min(Comparator.comparing(String::valueOf)).ifPresent(e -> System.out.println("Min: " + e));
max : 返回此流的最大元素
// API
Optional<T> max(Comparator<? super T> comparator);
Collector<T, ?, Optional<T>> maxBy(Comparator<? super T> comparator)
// 案例 :
list.stream().max(Comparator.comparing(String::valueOf)).ifPresent(e -> System.out.println("Max: " + e));
count : 计算流中的项目数
// API :
<T> Collector<T, ?, Long>javacounting()
// 案例 :
Stream.of(1,2,3,4,5).count();
reduce
// API : reduce 用于 Stream 中进行计算处理
Optional<T> reduce(BinaryOperator<T> accumulator);
Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op)
U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
Collector<T, ?, U> reducing(U identity,Function<? super T, ? extends U> mapper,BinaryOperator<U> op)
// 参数含义 :
identity : 缩减的标识值(也是没有输入元素时返回的值)
accumulator : 执行的操作
// 使用案例
numbers.reduce((i,j) -> {return i*j;});
numbers.stream().reduce(0, (subtotal, element) -> subtotal + element);
numbers.stream().reduce(0, Integer::sum);
// 关联字符串
letters.stream().reduce("", (partialString, element) -> partialString + element);
// 关联大小写
letters.stream().reduce("", (partialString, element) -> partialString.toUpperCase() + element.toUpperCase());
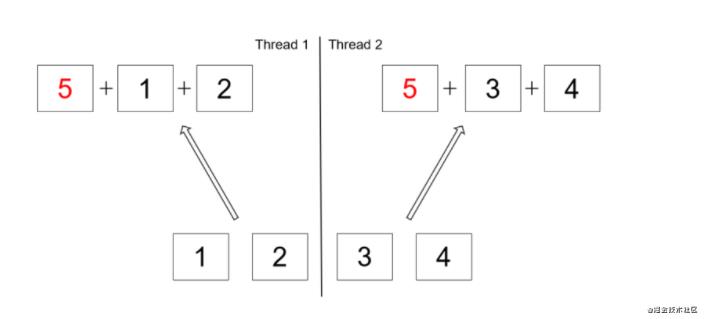
ages.parallelStream().reduce(0, a, b -> a + b, Integer::sum);
// 并行操作要点 : 并行处理运算必须要符合如下操作
1. 结果不受操作数顺序的影响
2. 互不干扰: 操作不影响数据源
3. 无状态和确定性: 操作没有状态,并且为给定的输入生成相同的输出
userList.parallelStream().reduce(0, (partialAgeResult, user) -> partialAgeResult + user.getAge(), Integer::sum);
2.4 流的 Terminal 操作之搜索
anyMatch:任一元素满足匹配条件
// API : Stream 中只要有一个元素符合传入的 predicate,返回 true
boolean anyMatch(Predicate<? super T> predicate);
// 案例 :
persons.stream(). anyMatch(p -> p.getAge() < 12);
allMatch:所有元素都满足匹配条件
// API : Stream 中全部元素符合传入的 predicate,返回 true
boolean allMatch(Predicate<? super T> predicate);
// 案例 :
persons.stream(). allMatch(p -> p.getAge() > 18);
findFirst:返回Stream中的第一个元素
// API : 返回一个 Optional 标识第一个元素
Optional<T> findFirst();
// 案例 :
students.stream().filter(student ->student .getage()>20 ).findFirst();
findAny:返回Stream中的任意个元素
// API : findAny不一定返回第一个,而是返回任意一个 , 如果流为空则返回一个空的Optional
Optional<T> findAny();
noneMatch:所有元素都不满足匹配条件
// API : 当Stream 中没有一个元素符合传入的 predicate,返回 true
boolean noneMatch(Predicate<? super T> predicate);
// 案例 :
numbers5.noneMatch(i -> i==10)
2.5 流的规约
// reduce : 对参数化操作后的集合进行进一步操作
students.stream().filter(student -> "计算机科学".equals(student.getMajor())).map(Student::getAge).reduce(0, (a, b) -> a + b);
students.stream().filter(student -> "计算机科学".equals(student.getMajor())).map(Student::getAge).reduce(0, Integer::sum);
students.stream().filter(student -> "计算机科学".equals(student.getMajor())).map(Student::getAge).reduce(Integer::sum);
2.6 流的分组 (Group By)
单级分组
// API :
public static <T, K> Collector<T, ?, Map<K, List<T>>>groupingBy(Function<? super T, ? extends K> classifier)
students.stream().collect(Collectors.groupingBy(Student::getSchool))
多级分组
// 作用 :
// 案例 :
students.stream().collect(
Collectors.groupingBy(Student::getSchool,
Collectors.groupingBy(Student::getMajor)));
partitioningBy : 分区 ,区别于groupBy ,分区中只有true , false .
// API : 可以看到 , 这里主要是 Predicate 函数
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,Collector<? super T, A, D> downstream)
// 案例 :
students.stream().collect(Collectors.partitioningBy(student -> "武汉大学".equals(student.getSchool())));
三 . 使用深入
3.1 扩展线程池
// 全局设置线程池
-D java.util.concurrent.ForkJoinPool.common.parallelism=4
// 手动设置线程此
ForkJoinPool customThreadPool = new ForkJoinPool(4);
int sum = customThreadPool.submit(
() -> listOfNumbers.parallelStream().reduce(0, Integer::sum)).get();
customThreadPool.shutdown();
3.2 Debug 处理
四 . 常见案例
案例 一 : 对 List AList 中 每个 元素进行操作转换后生成 另外的类型 C 放入 List BList
List<JSONObject> itemjson = new LinkedList<JSONObject>();
List<A> aList = ...
itemCW.stream().map(c -> {
JSONObject nodeitem = new JSONObject();
nodeitem.put("whtype", 0);
return nodeitem;
}).forEach(c -> itemjson.add(c));
案例二 : 对 Map 进行循环操作
realmTO.getTemplates().forEach((key, template) -> {
AnyType type = anyTypeDAO.find(key);
anyTemplate.set(template);
});
// for-each 的时候 , 可以传入 key 和 对象 ,后续可以使用
案例三 : 从大集合中获取小集合
// 获取id的集合
List<Long> idList = stockList.stream().map(Stock::getId).collect(Collectors.toList());
// 获取skuid集合并去重
List<Long> skuIdList = stockList.stream().map(Stock::getSkuId).distinct().collect(Collectors.toList());
// 获取supplierId集合(supplierId的类型为int,返回List<Integer>,使用boxed方法装箱)
Set<Integer> supplierIdSet = stockList.stream().mapToInt(Stock::getSupplierId).boxed().collect(Collectors.toSet());
案例四 : 分组与分片
// 按skuid分组
Map<Long, List<Stock>> skuIdStockMap = stockList.stream().collect(Collectors.groupingBy(Stock::getSkuId));
// 过滤supplierId=1然后按skuId分组
Map<Long, List<Stock>> filterSkuIdStockMap = stockList.stream().filter(s -> s.getSupplierId() == 1).collect(Collectors.groupingBy(Stock::getSkuId));
// 按状态分为不可用和其他两个分片
Map<Boolean, List<Stock>> partitionStockMap = stockList.stream().collect(Collectors.partitioningBy(s -> s.getStatus() == 0));
案例五 : 计数与求和
// 统计skuId=1的记录数
long skuIdRecordNum = stockList.stream().filter(s -> s.getSkuId() == 1).count();
// 统计skuId=1的总库存量
BigDecimal skuIdAmountSum = stockList.stream().filter(s -> s.getSkuId() == 1).map(Stock::getAmount).reduce(BigDecimal.ZERO, BigDecimal::add);
案例 六 :特定用法
// 多重分组并排序,先按supplierId分组,再按skuId分组,排序规则,先supplierId后skuId
Map<Integer, Map<Long, List<Stock>>> supplierSkuStockMap = stockList.stream().collect(Collectors.groupingBy(Stock::getSupplierId, TreeMap::new,
Collectors.groupingBy(Stock::getSkuId, TreeMap::new, Collectors.toList())));
// 多条件排序,先按supplierId正序排,再按skuId倒序排
// (非stream方法,而是集合的sort方法,直接改变原集合元素,使用Function参数)
stockList.sort(Comparator.comparing(Stock::getSupplierId)
.thenComparing(Stock::getSkuId, Comparator.reverseOrder()));
案例 七 : 对流进行排序
Collections.sort(literals, (final String t, final String t1) -> {
if (t == null && t1 == null) {
return 0;
} else if (t != null && t1 == null) {
return -1;
}
});
// t1 t2 是其中进行比较的了 2个对象 ,在里面定义相关的排序方法,通过返回 true / false 返回排序规则
案例 八 : 对流进行 filter 后 ,获取第一个
correlationRules.stream().filter(rule -> anyType != null && anyType.equals(rule.getAnyType())).findFirst()
// 关键在于 filter 和 findFirst
案例 九 :一种类型集合转换为另外一种类型集合
List<String> strings = Lists.transform(list, new Function<Integer, String>() {
@Override
public String apply(@Nullable Integer integer) {
return integer.toString();
}
});
案例 十 : 遍历集合并且返回集合
return Stream.of(resources).map(resource -> preserveSubpackageName(baseUrlString, resource, path)).collect(Collectors.toList());
private String preserveSubpackageName(final String baseUrlString, final Resource resource, final String rootPath) {
try {
return rootPath + (rootPath.endsWith("/") ? "" : "/")
+ resource.getURL().toString().substring(baseUrlString.length());
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
// 注意 ,其中调用了下面的方法 ,直接的匿名方法暂时不会写
案例十一 :简单拼接
// 拼接成 [x, y, z] 形式
String result1 = stream1.collect(Collectors.joining(", ", "[", "]"));
// 拼接成 x | y | z 形式
String result2 = stream2.collect(Collectors.joining(" | ", "", ""));
// 拼接成 x -> y -> z] 形式
String result3 = stream3.collect(Collectors.joining(" -> ", "", ""));
(String)value.stream().map((i) -> {
return this.formatSql("{0}", i);
}).collect(Collectors.joining(",", "(", ")"));
案例十二 : 复杂使用
buzChanlList.stream()
.map(item -> {
return null;
})
.filter(item -> {
return isok;
})
.forEach(c -> contentsList.add(c));
案例十三 : 切分集合
List<List<Integer>> splitList = Stream.iterate(0, n -> n + 1).limit(limit).parallel().map(a -> list.stream().skip(a * MAX_NUMBER).limit(MAX_NUMBER).parallel().collect(Collectors.toList())).collect(Collectors.toList());
案例十四 : filter 操作
collection.stream().filter(person -> "1".equals(person.getGender())).collect(Collectors.toList())
总结
流的并行特性在使用得当的情况下可以大大增加效率
前段时间,在和群友聊天时,把今年他们见到的一些不同类别的面试题整理了一番,于是有了以下面试题集,也一起分享给大家~
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料

基础篇


JVM 篇

mysql 篇



Redis 篇




由于篇幅限制,详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料
以上是关于操作手册 : Stream 流处理手册 (赶紧收藏)的主要内容,如果未能解决你的问题,请参考以下文章
❤️❤️HarmonyOS(鸿蒙)全网最全资源汇总,吐血整理,赶紧收藏!❤️❤️
c++IO库之string流超详细整理,建议赶紧收藏! ! !