java8 stream流操作
Posted gc65
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java8 stream流操作相关的知识,希望对你有一定的参考价值。
Stream
在对流进行处理时,不同的流操作以级联的方式形成处理流水线。一个流水线由一个源(source),0 到多个中间操作(intermediate operation)和一个终结操作(terminal operation)完成。
- 源:源是流中元素的来源。Java 提供了很多内置的源,包括数组、集合、生成函数和 I/O 通道等。
- 中间操作:中间操作在一个流上进行操作,返回结果是一个新的流。这些操作是延迟执行的。
- 终结操作:终结操作遍历流来产生一个结果或是副作用。在一个流上执行终结操作之后,该流被消费,无法再次被消费
源
Java 8 支持从不同的源中创建流。
中间操作
流中间操作在应用到流上,返回一个新的流。下面列出了常用的流中间操作:
- map:通过一个 Function 把一个元素类型为 T 的流转换成元素类型为 R 的流。
- flatMap:通过一个 Function 把一个元素类型为 T 的流中的每个元素转换成一个元素类型为 R 的流,再把这些转换之后的流合并。
- filter:过滤流中的元素,只保留满足由 Predicate 所指定的条件的元素。
- distinct:使用 equals 方法来删除流中的重复元素。
- limit:截断流使其最多只包含指定数量的元素。
- skip:返回一个新的流,并跳过原始流中的前 N 个元素。
- sorted:对流进行排序。
- peek:返回的流与原始流相同。当原始流中的元素被消费时,会首先调用 peek 方法中指定的 Consumer 实现对元素进行处理。
- dropWhile:从原始流起始位置开始删除满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
- takeWhile:从原始流起始位置开始保留满足指定 Predicate 的元素,直到遇到第一个不满足 Predicate 的元素。
终结操作
终结操作产生最终的结果。
1.forEach 和 forEachOrdered 对流中的每个元素执行由 Consumer 给定的实现。在使用 forEach 时,并没有确定的处理元素的顺序;forEachOrdered 则按照流的相遇顺序来处理元素,如果流有确定的相遇顺序的话。
2.reduce进行递归计算
3.collect生成新的数据结构
4.......
部分图解:(摘抄)

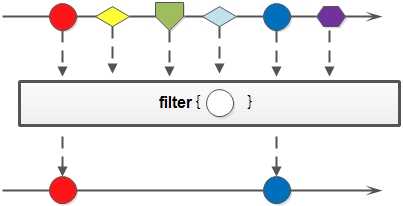
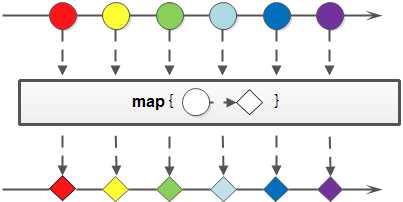
下面是示例代码
package com.gc.study.java8.stream; import java.util.ArrayList; import java.util.Arrays; import java.util.HashSet; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.Optional; import java.util.stream.Collectors; import java.util.stream.Stream; import org.junit.Test; import com.gc.study.java8.lambda.User; import com.gc.study.java8.lambda.User.Status; /** * @author gc * 一、Stream的三个操作步骤 (同一个流stream只能消费一次) * 1.创建stream * 2.中间操作 * 多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理 * 而在终止操作时一次性全部处理,称为惰性求值 * 3.终止操作 */ public class TestStream { //创建Stream @Test public void test() { List<String> list = new ArrayList<String>(); //1.可以通过Collection系列集合提供的stream() 或 parallelStream() Stream<String> stream1 = list.stream(); User[] users = new User[10]; //2.通过Arrays中的静态方法stream() 获取数组流 Stream<User> stream2 = Arrays.stream(users); //3.通过Stream类中的静态方法of() Stream<String> stream3 = Stream.of("aa","bb","cc"); //4.创建无限流 Stream<Integer> stream4 = Stream.iterate(0, (x) -> x + 2); stream3.forEach(System.out::println); stream4.limit(10).forEach(x -> System.out.println(x)); } List<User> users = Arrays.asList( new User("gc1", 24, 7500, Status.BUSY), new User("gc2", 25, 13000, Status.FREE), new User("gc3", 26, 20000, Status.VOCATION), new User("gc4", 23, 2000, Status.BUSY), new User("gc5", 22, 0, Status.FREE)); /* * 中间操作:(1.返回结果依然是流 2.中间操作是延迟的,遇到终结操作才会触发执行 3.中间操作是流水线形式的) * 筛选与切片 * filter:接收流中的元素,从流中排除某些元素 * limit:截断流,使元素不超过给定数量 * skip(n): 跳过前n个元素,返回剩余的元素,若流中元素不足n个,则返回空流 * distinct:筛选,通过流所生成元素的hashCode和equals去除重复元素 * 映射: * map:接收lambda,将元素转换成其它形式或提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素 * flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连城一个流 * 排序: * sorted():自然排序(Comparable) * sorted(Comparator com):定制排序(Comparator) */ //内部迭代:迭代操作部由Stream API完成 @Test public void testMid() { //中间操作filter的作用是过滤年龄大于24的User,返回新的流 Stream<User> s = users.stream().filter(u -> { //u.setName("test"); System.out.println("filter mid ge:"+u.getAge()); return u.getAge() > 24; }); //打印流,这里才会实际执行上面的filter函数 /* * 输出结果如下: * filter mid ge:24 filter mid ge:25 foreach end age:25 filter mid ge:26 foreach end age:26 filter mid ge:23 filter mid ge:22 */ s.forEach(x -> System.out.println("foreach end age:" + x.getAge())); //这里是去除list中的重复元素 users.stream().distinct().forEach(System.out::println); } //下面测试中间操作的作用关系 // 1.中间操作是流水线形式的,即不是中间操作完成才进行终结操作,而是执行完一条中间操作接着执行一条终结操作。以此循环。 @Test public void testMid2() { users.stream().limit(1).filter(u -> { System.out.println("age:" + u.getAge()); return (u.getAge() > 24); }).forEach(System.out::println); System.out.println("-------------------------"); /* 下面输出结果如下 * age:24 age:25 User [name=gc2, age=25, salary=13000, status=FREE] */ users.stream().filter(u -> { System.out.println("age:" + u.getAge()); return (u.getAge() > 24); }).limit(1).forEach(System.out::println); } @Test public void testMap() { List<String> list = Arrays.asList("aa","bb","cc"); //中间操作map传递的是函数式接口Function,其作用是进行数据转换。 //这里str -> str.toUpperCase()即为Function接口中apply方法的实现,所以其作用就是转为大写。 list.stream().map(str -> str.toUpperCase()).forEach(System.out::println); //这个同上,是lambda的简写 list.stream().map(String::toUpperCase).forEach(System.out::println); //使用Function接口的功能转换,提取User的用户名,执行完中间操作map后,相当于生成了一个List<String> userNames.(中间操作有延迟性,所以这里不是准确描述) users.stream().map(User::getName).forEach(System.out::println); users.stream().map(u -> u.getName()).forEach(System.out::println); System.out.println("----------------------map,类似于list.add(list2),保留list2的数据结构"); Stream<Stream<Character>> stream = list.stream().map(TestStream::filterCharacter); stream.forEach(sm -> { sm.forEach(System.out::println); }); System.out.println("----------------------flatmap, 类似于list.addall(),两个list合并为一个"); Stream<Character> stream2 = list.stream().flatMap(TestStream::filterCharacter); stream2.forEach(System.out::println); } public static Stream<Character> filterCharacter(String str) { List<Character> list = new ArrayList<Character>(); for(Character ch : str.toCharArray()) { list.add(ch); } return list.stream(); } @Test public void testSort() { System.out.println("------自然排序,依赖对象自身实现Comparable"); List<String> list = Arrays.asList("aa","bb","cc"); list.stream().sorted().forEach(System.out::println); System.out.println("-----定制排序,需要复写Comparator"); //sorted的入参是Comparator接口,所以(u1,u2) -> {return u1.getAge() - u2.getAge();}成了Comparator接口的匿名实现 users.stream().sorted((u1,u2) -> { return u1.getAge() - u2.getAge(); }).forEach(System.out::println);; } /* * 查找与匹配 * allMatch:检查是否匹配所有元素 * anyMatch:检查是否至少匹配一个元素 * noneMatch:检查是否没有任何元素匹配 * findFirst:返回第一个元素 * findAny:返回当前流中的任意元素 * count:返回流中元素的总个数 * max:返回流中最大值 * min:返回流中最小值 * */ @Test public void testMatch() { boolean b1 = users.stream().allMatch(u -> u.getStatus().equals(Status.BUSY)); System.out.println("all busy:"+b1); boolean b2 = users.stream().anyMatch(u -> u.getStatus().equals(Status.BUSY)); System.out.println("any busy:"+b2); boolean b3 = users.stream().noneMatch(u -> u.getStatus().equals(Status.BUSY)); System.out.println("none busy:"+b3); Optional<User> user1 = users.stream().findFirst(); System.out.println("findFirst:"+user1.get()); Optional<User> findAny = users.stream().filter(u -> u.getStatus().equals(Status.FREE)).findAny(); System.out.println("findAny:"+findAny.get()); long count = users.stream().count(); System.out.println("count:"+count); Optional<User> max = users.stream().max((u1, u2) -> { return u1.getAge()-u2.getAge(); }); System.out.println("max:"+max.get()); Optional<User> min = users.stream().min((u1, u2) -> { return u1.getAge()-u2.getAge(); }); System.out.println("min:"+min.get()); } /* * 归约:(可以理解为递归,也是终止操作) * reduce 进行反复计算,如求和 */ @Test public void testReduce() { List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9); //这里0是初始值,第一次执行规约应该是0+1,其中1是第一个值 Integer sum = list.stream().reduce(0, (x,y) -> x + y); System.out.println("sum:"+sum); Optional<Integer> reduce = users.stream().map(User::getSalary).reduce(Integer::sum); System.out.println("sum2:"+reduce.get()); } /* * 收集(stream的终止操作之一,forEach,reduce等也是) * collect:将流转换为其他形式,接收一个collection接口的实现,用于给stream元素做汇总的方法 */ @Test public void testCollect() { //map是数据转换,将List<User> 转换为String类型的Stream。 collect把新的Stream转化为List<String> List<String> list = users.stream().map(User::getName) .collect(Collectors.toList()); list.forEach(System.out::println); //这里是转换为set users.stream().map(User::getName).collect(Collectors.toSet()); //把list转为其它的数据结构,这里是hashset HashSet<String> hashSet = users.stream().map(User::getName). collect(Collectors.toCollection(HashSet::new)); Long count = users.stream().collect(Collectors.counting()); Double avgAge = users.stream().collect(Collectors.averagingInt(User::getAge)); //按条件分组 Map<Status, List<User>> map = users.stream().collect(Collectors.groupingBy(User::getStatus)); System.out.println("collectors分组功能, map:"+map); Map<Status, Map<String, List<User>>> collect = users.stream().collect(Collectors.groupingBy( User::getStatus, Collectors.groupingBy(u -> { if(((User)u).getAge() <= 24) { return "happy"; } else { return "very happy"; } }))); System.out.println("多级分组:"+collect); //按条件分区,true放在一组,false放在另一组 Map<Boolean, List<User>> collect2 = users.stream().collect(Collectors.partitioningBy((u) -> u.getAge() > 24)); System.out.println(collect2); } }
以上是关于java8 stream流操作的主要内容,如果未能解决你的问题,请参考以下文章