Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB相关的知识,希望对你有一定的参考价值。
背景介绍
本文将介绍如何将 mysql 中的数据,通过 Binlog + Canal 的形式导入到 Kafka 中,继而被 Flink 消费的案例。
为了能够快速的验证整套流程的功能性,所有的组件都以单机的形式部署。如果手上的物理资源不足,可以将本文中的所有组件搭建在一台 4G 1U 的虚拟机环境中。
如果需要在生产环境中部署,建议将每一个组件替换成高可用的集群部署方案。
其中,我们单独创建了一套 Zookeeper 单节点环境,Flink、Kafka、Canal 等组件共用这个 Zookeeper 环境。
针对于所有需要 JRE 的组件,如 Flink,Kafka,Canal,Zookeeper,考虑到升级 JRE 可能会影响到其他的应用,我们选择每个组件独立使用自己的 JRE 环境。
本文分为两个部分,其中,前七小节主要介绍基础环境的搭建,最后一个小节介绍了数据是如何在各个组件中流通的。
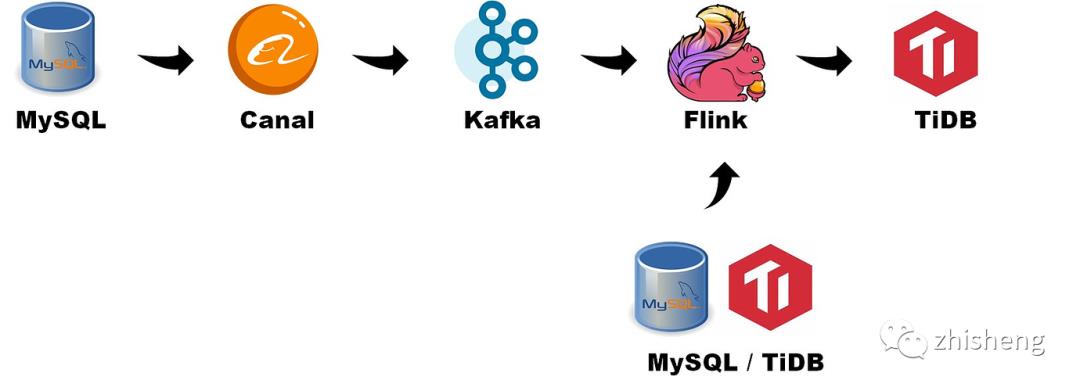
数据的流动经过以下的组件:
MySQL 数据源生成 Binlog
Canal 读取 Binlog,生成 Canal json,推送到 Kafka 指定的 Topic 中
Flink 使用 flink-sql-connector-kafka API,消费 Kafka Topic 中的数据
Flink 在通过 flink-connector-jdbc,将数据写入到 TiDB 中
TiDB + Flink 的结构,支持开发与运行多种不同种类的应用程序。
目前主要的特性主要包括:
批流一体化
精密的状态管理
事件时间支持
精确的一次状态一致性保障
Flink 可以运行在包括 YARN、Mesos、Kubernetes 在内的多种资源管理框架上,还支持裸机集群上独立部署。TiDB 可以部署 AWS、Kubernetes、GCP GKE 上,同时也支持使用 TiUP 在裸机集群上独立部署。
TiDB + Flink 结构常见的几类应用如下:
事件驱动型应用
反欺诈
异常检测
基于规则的报警
业务流程监控
数据分析应用
网络质量监控
产品更新及试验评估分析
事实数据即席分析
大规模图分析
数据管道应用
电商实时查询索引构建
电商持续 ETL
环境介绍
操作系统环境
[root@r20 topology]# cat /etc/redhat-release
CentOS Stream release 8
软件环境

机器分配

部署 TiDB Cluster
与传统的单机数据库相比,TiDB 具有以下优势:
纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:

在本文中,我们只做最简单的功能测试,所以部署了一套单节点但副本的 TiDB,涉及到了以下的三个模块:
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。
TiUP 部署模板文件
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/opt/tidb-c1/"
data_dir: "/opt/tidb-c1/data/"
# # Monitored variables are applied to all the machines.
#monitored:
# node_exporter_port: 19100
# blackbox_exporter_port: 39115
# deploy_dir: "/opt/tidb-c3/monitored"
# data_dir: "/opt/tidb-c3/data/monitored"
# log_dir: "/opt/tidb-c3/log/monitored"
# # Server configs are used to specify the runtime configuration of TiDB components.
# # All configuration items can be found in TiDB docs:
# # - TiDB: https://pingcap.com/docs/stable/reference/configuration/tidb-server/configuration-file/
# # - TiKV: https://pingcap.com/docs/stable/reference/configuration/tikv-server/configuration-file/
# # - PD: https://pingcap.com/docs/stable/reference/configuration/pd-server/configuration-file/
# # All configuration items use points to represent the hierarchy, e.g:
# # readpool.storage.use-unified-pool
# #
# # You can overwrite this configuration via the instance-level `config` field.
server_configs:
tidb:
log.slow-threshold: 300
binlog.enable: false
binlog.ignore-error: false
tikv-client.copr-cache.enable: true
tikv:
server.grpc-concurrency: 4
raftstore.apply-pool-size: 2
raftstore.store-pool-size: 2
rocksdb.max-sub-compactions: 1
storage.block-cache.capacity: "16GB"
readpool.unified.max-thread-count: 12
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
raftdb.rate-bytes-per-sec: 0
pd:
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
pd_servers:
- host: 192.168.12.21
ssh_port: 22
name: "pd-2"
client_port: 12379
peer_port: 12380
deploy_dir: "/opt/tidb-c1/pd-12379"
data_dir: "/opt/tidb-c1/data/pd-12379"
log_dir: "/opt/tidb-c1/log/pd-12379"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.pd` values.
config:
schedule.max-merge-region-size: 20
schedule.max-merge-region-keys: 200000
tidb_servers:
- host: 192.168.12.21
ssh_port: 22
port: 14000
status_port: 12080
deploy_dir: "/opt/tidb-c1/tidb-14000"
log_dir: "/opt/tidb-c1/log/tidb-14000"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tidb` values.
config:
log.slow-query-file: tidb-slow-overwrited.log
tikv-client.copr-cache.enable: true
tikv_servers:
- host: 192.168.12.21
ssh_port: 22
port: 12160
status_port: 12180
deploy_dir: "/opt/tidb-c1/tikv-12160"
data_dir: "/opt/tidb-c1/data/tikv-12160"
log_dir: "/opt/tidb-c1/log/tikv-12160"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tikv` values.
config:
server.grpc-concurrency: 4
#server.labels: { zone: "zone1", dc: "dc1", host: "host1" }
#monitoring_servers:
# - host: 192.168.12.21
# ssh_port: 22
# port: 19090
# deploy_dir: "/opt/tidb-c1/prometheus-19090"
# data_dir: "/opt/tidb-c1/data/prometheus-19090"
# log_dir: "/opt/tidb-c1/log/prometheus-19090"
#grafana_servers:
# - host: 192.168.12.21
# port: 13000
# deploy_dir: "/opt/tidb-c1/grafana-13000"
#alertmanager_servers:
# - host: 192.168.12.21
# ssh_port: 22
# web_port: 19093
# cluster_port: 19094
# deploy_dir: "/opt/tidb-c1/alertmanager-19093"
# data_dir: "/opt/tidb-c1/data/alertmanager-19093"
# log_dir: "/opt/tidb-c1/log/alertmanager-19093"
TiDB Cluster 环境
本文重点并非部署 TiDB Cluster,作为快速实验环境,只在一台机器上部署单副本的 TiDB Cluster 集群。不需要部署监控环境。
[root@r20 topology]# tiup cluster display tidb-c1-v409
Starting component `cluster`: /root/.tiup/components/cluster/v1.3.2/tiup-cluster display tidb-c1-v409
Cluster type: tidb
Cluster name: tidb-c1-v409
Cluster version: v4.0.9
SSH type: builtin
Dashboard URL: http://192.168.12.21:12379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
192.168.12.21:12379 pd 192.168.12.21 12379/12380 linux/x86_64 Up|L|UI /opt/tidb-c1/data/pd-12379 /opt/tidb-c1/pd-12379
192.168.12.21:14000 tidb 192.168.12.21 14000/12080 linux/x86_64 Up - /opt/tidb-c1/tidb-14000
192.168.12.21:12160 tikv 192.168.12.21 12160/12180 linux/x86_64 Up /opt/tidb-c1/data/tikv-12160 /opt/tidb-c1/tikv-12160
Total nodes: 4
创建用于测试的表
mysql> show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin |
+-------+-------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
部署 Zookeeper 环境
在本实验中单独配置 Zookeeper 环境,为 Kafka 和 Flink 环境提供服务。
作为实验演示方案,只部署单机环境。
解压 Zookeeper 包
[root@r24 soft]# tar vxzf apache-zookeeper-3.6.2-bin.tar.gz
[root@r24 soft]# mv apache-zookeeper-3.6.2-bin /opt/zookeeper
部署用于 Zookeeper 的 jre
[root@r24 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r24 soft]# mv jre1.8.0_281 /opt/zookeeper/jre
修改 /opt/zookeeper/bin/zkEnv.sh 文件,增加 JAVA_HOME 环境变量
## add bellowing env var in the head of zkEnv.sh
JAVA_HOME=/opt/zookeeper/jre
创建 Zookeeper 的配置文件
[root@r24 conf]# cat zoo.cfg | grep -v "#"
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
clientPort=2181
启动 Zookeeper
[root@r24 bin]# /opt/zookeeper/bin/zkServer.sh start
检查 Zookeeper 的状态
## check zk status
[root@r24 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
## check OS port status
[root@r24 bin]# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 942/sshd
tcp6 0 0 :::2181 :::* LISTEN 15062/java
tcp6 0 0 :::8080 :::* LISTEN 15062/java
tcp6 0 0 :::22 :::* LISTEN 942/sshd
tcp6 0 0 :::44505 :::* LISTEN 15062/java
## use zkCli tool to check zk connection
[root@r24 bin]# ./zkCli.sh -server 192.168.12.24:2181
关于 Zookeeper 的建议
我个人有一个关于 Zookeeper 的不成熟的小建议:
Zookeeper 集群版本一定要开启网络监控。
特别是要关注 system metrics 里面的 network bandwidth。
部署 Kafka
Kafka 是一个分布式流处理平台,主要应用于两大类的应用中:
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。(相当于message queue)
构建实时流式应用程序,对这些流数据进行转换或者影响。(就是流处理,通过kafka stream topic和topic之间内部进行变化)
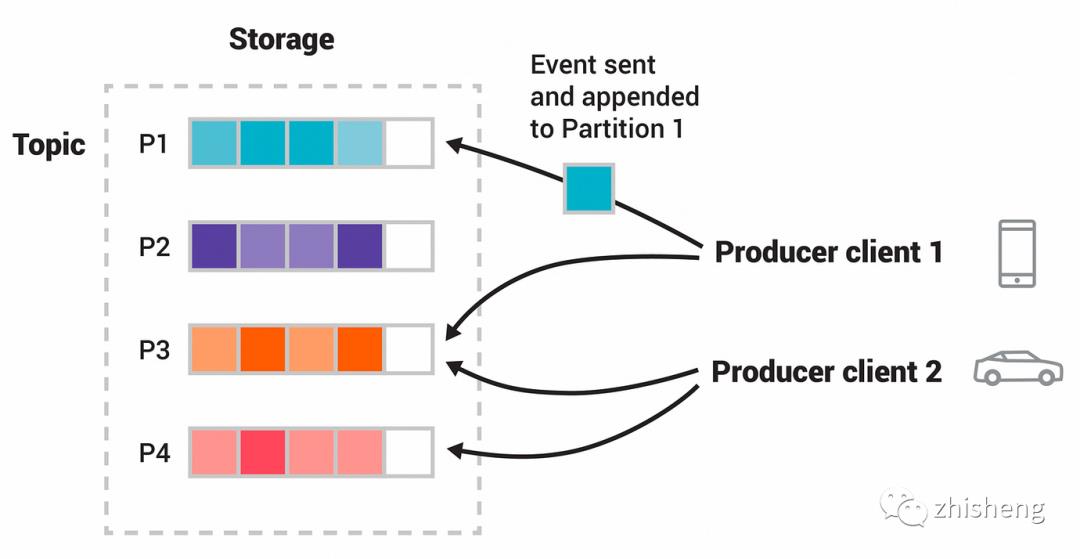
Kafka 有四个核心的 API:
The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
在本实验中只做功能性验证,只搭建一个单机版的 Kafka 环境。
下载并解压 Kafka
[root@r22 soft]# tar vxzf kafka_2.13-2.7.0.tgz
[root@r22 soft]# mv kafka_2.13-2.7.0 /opt/kafka
部署用于 Kafka 的 jre
[root@r22 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r22 soft]# mv jre1.8.0_281 /opt/kafka/jre
修改 Kafka 的 jre 环境变量
[root@r22 bin]# vim /opt/kafka/bin/kafka-run-class.sh
## add bellowing line in the head of kafka-run-class.sh
JAVA_HOME=/opt/kafka/jre
修改 Kafka 配置文件
修改 Kafka 配置文件 /opt/kafka/config/server.properties
## change bellowing variable in /opt/kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.12.22:9092
log.dirs=/opt/kafka/logs
zookeeper.connect=i192.168.12.24:2181
启动 Kafka
[root@r22 bin]# /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
查看 Kafka 的版本信息
Kafka 并没有提供 --version 的 optional 来查看 Kafka 的版本信息。
[root@r22 ~]# ll /opt/kafka/libs/ | grep kafka
-rw-r--r-- 1 root root 4929521 Dec 16 09:02 kafka_2.13-2.7.0.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0.jar.asc
-rw-r--r-- 1 root root 41793 Dec 16 09:02 kafka_2.13-2.7.0-javadoc.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-javadoc.jar.asc
-rw-r--r-- 1 root root 892036 Dec 16 09:02 kafka_2.13-2.7.0-sources.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-sources.jar.asc
... ...
其中 2.13 是 scale 的版本信息,2.7.0 是 Kafka 的版本信息。
部署 Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
支持高吞吐、低延迟、高性能的分布式处理框架Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。

本实验只做功能性测试,仅部署单机 Flink 环境。
下载并分发 Flink
[root@r23 soft]# tar vxzf flink-1.12.1-bin-scala_2.11.tgz
[root@r23 soft]# mv flink-1.12.1 /opt/flink
部署 Flink 的 jre
[root@r23 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r23 soft]# mv jre1.8.0_281 /opt/flink/jre
添加 Flink 需要的 lib
Flink 消费 Kafka 数据,需要 flink-sql-connector-kafka 包
Flink 链接 MySQL/TiDB,需要 flink-connector-jdbc 包
[root@r23 soft]# mv flink-sql-connector-kafka_2.12-1.12.0.jar /opt/flink/lib/
[root@r23 soft]# mv flink-connector-jdbc_2.12-1.12.0.jar /opt/flink/lib/
修改 Flink 配置文件
## add or modify bellowing lines in /opt/flink/conf/flink-conf.yaml
jobmanager.rpc.address: 192.168.12.23
env.java.home: /opt/flink/jre
启动 Flink
[root@r23 ~]# /opt/flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host r23.
Starting taskexecutor daemon on host r23.
查看 Flink GUI
部署 MySQL
解压 MySQL package
[root@r25 soft]# tar vxf mysql-8.0.23-linux-glibc2.12-x86_64.tar.xz
[root@r25 soft]# mv mysql-8.0.23-linux-glibc2.12-x86_64 /opt/mysql/
创建 MySQL Service 文件
[root@r25 ~]# touch /opt/mysql/support-files/mysqld.service
[root@r25 support-files]# cat mysqld.service
[Unit]
Description=MySQL 8.0 database server
After=syslog.target
After=network.target
[Service]
Type=simple
User=mysql
Group=mysql
#ExecStartPre=/usr/libexec/mysql-check-socket
#ExecStartPre=/usr/libexec/mysql-prepare-db-dir %n
# Note: we set --basedir to prevent probes that might trigger SELinux alarms,
# per bug #547485
ExecStart=/opt/mysql/bin/mysqld_safe
#ExecStartPost=/opt/mysql/bin/mysql-check-upgrade
#ExecStopPost=/opt/mysql/bin/mysql-wait-stop
# Give a reasonable amount of time for the server to start up/shut down
TimeoutSec=300
# Place temp files in a secure directory, not /tmp
PrivateTmp=true
Restart=on-failure
RestartPreventExitStatus=1
# Sets open_files_limit
LimitNOFILE = 10000
# Set enviroment variable MYSQLD_PARENT_PID. This is required for SQL restart command.
Environment=MYSQLD_PARENT_PID=1
[Install]
WantedBy=multi-user.target
## copy mysqld.service to /usr/lib/systemd/system/
[root@r25 support-files]# cp mysqld.service /usr/lib/systemd/system/
创建 my.cnf 文件
[root@r34 opt]# cat /etc/my.cnf
[mysqld]
port=3306
basedir=/opt/mysql
datadir=/opt/mysql/data
socket=/opt/mysql/data/mysql.socket
max_connections = 100
default-storage-engine = InnoDB
character-set-server=utf8
log-error = /opt/mysql/log/error.log
slow_query_log = 1
long-query-time = 30
slow_query_log_file = /opt/mysql/log/show.log
min_examined_row_limit = 1000
log-slow-slave-statements
log-queries-not-using-indexes
#skip-grant-tables
初始化并启动 MySQL
[root@r25 ~]# /opt/mysql/bin/mysqld --initialize --user=mysql --console
[root@r25 ~]# chown -R mysql:mysql /opt/mysql
[root@r25 ~]# systemctl start mysqld
## check mysql temp passord from /opt/mysql/log/error.log
2021-02-24T02:45:47.316406Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: I?nDjijxa3>-
创建一个新的 MySQL 用户用以连接 Canal
## change mysql temp password firstly
mysql> alter user 'root'@'localhost' identified by 'mysql';
Query OK, 0 rows affected (0.00 sec)
## create a management user 'root'@'%'
mysql> create user 'root'@'%' identified by 'mysql';
Query OK, 0 rows affected (0.01 sec)
mysql> grant all privileges on *.* to 'root'@'%';
Query OK, 0 rows affected (0.00 sec)
## create a canal replication user 'canal'@'%'
mysql> create user 'canal'@'%' identified by 'canal';
Query OK, 0 rows affected (0.01 sec)
mysql> grant select, replication slave, replication client on *.* to 'canal'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
在 MySQL 中创建用于测试的表
mysql> show create table test.t2;
+-------+----------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------+
| t2 | CREATE TABLE `t2` (
`id` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+----------------------------------------------------------------------------------+
1 row in set (0.00 sec)
部署 Canal
Canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。
从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。

基于日志增量订阅和消费的业务包括:
数据库镜像
数据库实时备份
索引构建和实时维护(拆分异构索引、倒排索引等)
业务 cache 刷新
带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
解压 Canal 包
[root@r26 soft]# mkdir /opt/canal && tar vxzf canal.deployer-1.1.4.tar.gz -C /opt/canal
部署 Canal 的 jre
[root@r26 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r26 soft]# mv jre1.8.0_281 /opt/canal/jre
## configue jre, add bellowing line in the head of /opt/canal/bin/startup.sh
JAVA=/opt/canal/jre/bin/java
修改 Canal 的配置文件
修改 /opt/canal/conf/canal.properties 配置文件
## modify bellowing configuration
canal.zkServers =192.168.12.24:2181
canal.serverMode = kafka
canal.destinations = example ## 需要在 /opt/canal/conf 目录下创建一个 example 文件夹,用于存放 destination 的配置
canal.mq.servers = 192.168.12.22:9092
修改 /opt/canal/conf/example/instance.properties 配置文件
## modify bellowing configuration
canal.instance.master.address=192.168.12.25:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.filter.regex=.*\\\\..* ## 过滤数据库的表
canal.mq.topic=canal-kafka
配置数据流向
MySQL Binlog -> Canal -> Kafka 通路
查看 MySQL Binlog 信息
查看 MySQL Binlog 信息,确保 Binlog 是正常的
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000001 | 2888 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
在 Kafka 中创建一个 Topic
在 Kafka 中创建一个 Topic canal-kafka,这个Topic 的名字要与 Canal 配置文件 /opt/canal/conf/example/instance.properties 中的 canal.mq.topic=canal-kafka 对应:
[root@r22 kafka]# /opt/kafka/bin/kafka-topics.sh --create \\
> --zookeeper 192.168.12.24:2181 \\
> --config max.message.bytes=12800000 \\
> --config flush.messages=1 \\
> --replication-factor 1 \\
> --partitions 1 \\
> --topic canal-kafka
Created topic canal-kafka.
[2021-02-24 01:51:55,050] INFO [ReplicaFetcherManager on broker 0] Removed fetcher for partitions Set(canal-kafka-0) (kafka.server.ReplicaFetcherManager)
[2021-02-24 01:51:55,052] INFO [Log partition=canal-kafka-0, dir=/opt/kafka/logs] Loading producer state till offset 0 with message format version 2 (kafka.log.Log)
[2021-02-24 01:51:55,053] INFO Created log for partition canal-kafka-0 in /opt/kafka/logs/canal-kafka-0 with properties {compression.type -> producer, message.downconversion.enable -> true, min.insync.replicas -> 1, segment.jitter.ms -> 0, cleanup.policy -> [delete], flush.ms -> 9223372036854775807, segment.bytes -> 1073741824, retention.ms -> 604800000, flush.messages -> 1, message.format.version -> 2.7-IV2, file.delete.delay.ms -> 60000, max.compaction.lag.ms -> 9223372036854775807, max.message.bytes -> 12800000, min.compaction.lag.ms -> 0, message.timestamp.type -> CreateTime, preallocate -> false, min.cleanable.dirty.ratio -> 0.5, index.interval.bytes -> 4096, unclean.leader.election.enable -> false, retention.bytes -> -1, delete.retention.ms -> 86400000, segment.ms -> 604800000, message.timestamp.difference.max.ms -> 9223372036854775807, segment.index.bytes -> 10485760}. (kafka.log.LogManager)
[2021-02-24 01:51:55,053] INFO [Partition canal-kafka-0 broker=0] No checkpointed highwatermark is found for partition canal-kafka-0 (kafka.cluster.Partition)
[2021-02-24 01:51:55,053] INFO [Partition canal-kafka-0 broker=0] Log loaded for partition canal-kafka-0 with initial high watermark 0 (kafka.cluster.Partition)
查看 Kafka 中所有的 Topic:
[root@r22 kafka]# /opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.12.24:2181
__consumer_offsets
canal-kafka
ticdc-test
查看 Kafka 中 Topic ticdc-test 的信息:
[root@r22 ~]# /opt/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.12.24:2181 --topic canal-kafka
Topic: ticdc-test PartitionCount: 1 ReplicationFactor: 1 Configs: max.message.bytes=12800000,flush.messages=1
Topic: ticdc-test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
8.1.3 启动 Canal
在启动 Canal 之前,需要在 Canal 节点上查看一下端口的情况:
## check MySQL 3306 port
## canal.instance.master.address=192.168.12.25:3306
[root@r26 bin]# telnet 192.168.12.25 3306
## check Kafka 9092 port
## canal.mq.servers = 192.168.12.22:9092
[root@r26 bin]# telnet 192.168.12.22 9092
## check zookeeper 2181 port
## canal.zkServers = 192.168.12.24:2181
[root@r26 bin]# telnet 192.168.12.24 2181
启动 Canal:
[root@r26 bin]# /opt/canal/bin/startup.sh
cd to /opt/canal/bin for workaround relative path
LOG CONFIGURATION : /opt/canal/bin/../conf/logback.xml
canal conf : /opt/canal/bin/../conf/canal.properties
CLASSPATH :/opt/canal/bin/../conf:/opt/canal/bin/../lib/zookeeper-3.4.5.jar:/opt/canal/bin/../lib/zkclient-0.10.jar:/opt/canal/bin/../lib/spring-tx-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-orm-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-jdbc-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-expression-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-core-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-context-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-beans-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/spring-aop-3.2.18.RELEASE.jar:/opt/canal/bin/../lib/snappy-java-1.1.7.1.jar:/opt/canal/bin/../lib/snakeyaml-1.19.jar:/opt/canal/bin/../lib/slf4j-api-1.7.12.jar:/opt/canal/bin/../lib/simpleclient_pushgateway-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_httpserver-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_hotspot-0.4.0.jar:/opt/canal/bin/../lib/simpleclient_common-0.4.0.jar:/opt/canal/bin/../lib/simpleclient-0.4.0.jar:/opt/canal/bin/../lib/scala-reflect-2.11.12.jar:/opt/canal/bin/../lib/scala-logging_2.11-3.8.0.jar:/opt/canal/bin/../lib/scala-library-2.11.12.jar:/opt/canal/bin/../lib/rocketmq-srvutil-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-remoting-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-logging-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-common-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-client-4.5.2.jar:/opt/canal/bin/../lib/rocketmq-acl-4.5.2.jar:/opt/canal/bin/../lib/protobuf-java-3.6.1.jar:/opt/canal/bin/../lib/oro-2.0.8.jar:/opt/canal/bin/../lib/netty-tcnative-boringssl-static-1.1.33.Fork26.jar:/opt/canal/bin/../lib/netty-all-4.1.6.Final.jar:/opt/canal/bin/../lib/netty-3.2.2.Final.jar:/opt/canal/bin/../lib/mysql-connector-java-5.1.47.jar:/opt/canal/bin/../lib/metrics-core-2.2.0.jar:/opt/canal/bin/../lib/lz4-java-1.4.1.jar:/opt/canal/bin/../lib/logback-core-1.1.3.jar:/opt/canal/bin/../lib/logback-classic-1.1.3.jar:/opt/canal/bin/../lib/kafka-clients-1.1.1.jar:/opt/canal/bin/../lib/kafka_2.11-1.1.1.jar:/opt/canal/bin/../lib/jsr305-3.0.2.jar:/opt/canal/bin/../lib/jopt-simple-5.0.4.jar:/opt/canal/bin/../lib/jctools-core-2.1.2.jar:/opt/canal/bin/../lib/jcl-over-slf4j-1.7.12.jar:/opt/canal/bin/../lib/javax.annotation-api-1.3.2.jar:/opt/canal/bin/../lib/jackson-databind-2.9.6.jar:/opt/canal/bin/../lib/jackson-core-2.9.6.jar:/opt/canal/bin/../lib/jackson-annotations-2.9.0.jar:/opt/canal/bin/../lib/ibatis-sqlmap-2.3.4.726.jar:/opt/canal/bin/../lib/httpcore-4.4.3.jar:/opt/canal/bin/../lib/httpclient-4.5.1.jar:/opt/canal/bin/../lib/h2-1.4.196.jar:/opt/canal/bin/../lib/guava-18.0.jar:/opt/canal/bin/../lib/fastsql-2.0.0_preview_973.jar:/opt/canal/bin/../lib/fastjson-1.2.58.jar:/opt/canal/bin/../lib/druid-1.1.9.jar:/opt/canal/bin/../lib/disruptor-3.4.2.jar:/opt/canal/bin/../lib/commons-logging-1.1.3.jar:/opt/canal/bin/../lib/commons-lang3-3.4.jar:/opt/canal/bin/../lib/commons-lang-2.6.jar:/opt/canal/bin/../lib/commons-io-2.4.jar:/opt/canal/bin/../lib/commons-compress-1.9.jar:/opt/canal/bin/../lib/commons-codec-1.9.jar:/opt/canal/bin/../lib/commons-cli-1.2.jar:/opt/canal/bin/../lib/commons-beanutils-1.8.2.jar:/opt/canal/bin/../lib/canal.store-1.1.4.jar:/opt/canal/bin/../lib/canal.sink-1.1.4.jar:/opt/canal/bin/../lib/canal.server-1.1.4.jar:/opt/canal/bin/../lib/canal.protocol-1.1.4.jar:/opt/canal/bin/../lib/canal.prometheus-1.1.4.jar:/opt/canal/bin/../lib/canal.parse.driver-1.1.4.jar:/opt/canal/bin/../lib/canal.parse.dbsync-1.1.4.jar:/opt/canal/bin/../lib/canal.parse-1.1.4.jar:/opt/canal/bin/../lib/canal.meta-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.spring-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.manager-1.1.4.jar:/opt/canal/bin/../lib/canal.instance.core-1.1.4.jar:/opt/canal/bin/../lib/canal.filter-1.1.4.jar:/opt/canal/bin/../lib/canal.deployer-1.1.4.jar:/opt/canal/bin/../lib/canal.common-1.1.4.jar:/opt/canal/bin/../lib/aviator-2.2.1.jar:/opt/canal/bin/../lib/aopalliance-1.0.jar:
cd to /opt/canal/bin for continue
查看 Canal 日志
查看 /opt/canal/logs/example/example.log
2021-02-24 01:41:40.293 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2021-02-24 01:41:40.293 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2021-02-24 01:41:40.542 [destination = example , address = /192.168.12.25:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=binlog.000001,position=4,serverId=1,gtid=<null>,timestamp=1614134832000] cost : 244ms , the next step is binlog dump
查看 Kafka 中 consumer 信息
在 MySQL 中插入一条测试信息:
mysql> insert into t2 values(1);
Query OK, 1 row affected (0.00 sec)
查看 consumer 的信息,已经有了刚才插入的测试数据:
/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.12.22:9092 --topic canal-kafka --from-beginning
{"data":null,"database":"test","es":1614151725000,"id":2,"isDdl":false,"mysqlType":null,"old":null,"pkNames":null,"sql":"create database test","sqlType":null,"table":"","ts":1614151725890,"type":"QUERY"}
{"data":null,"database":"test","es":1614151746000,"id":3,"isDdl":true,"mysqlType":null,"old":null,"pkNames":null,"sql":"create table t2(id int)","sqlType":null,"table":"t2","ts":1614151746141,"type":"CREATE"}
{"data":[{"id":"1"}],"database":"test","es":1614151941000,"id":4,"isDdl":false,"mysqlType":{"id":"int"},"old":null,"pkNames":null,"sql":"","sqlType":{"id":4},"table":"t2","ts":1614151941235,"type":"INSERT"}
Kafka -> Flink 通路
在 Flink 中创建 t2 表,connector 类型为 kafka
## create a test table t2 in Flink
Flink SQL> create table t2(id int)
> WITH (
> 'connector' = 'kafka',
> 'topic' = 'canal-kafka',
> 'properties.bootstrap.servers' = '192.168.12.22:9092',
> 'properties.group.id' = 'canal-kafka-consumer-group',
> 'format' = 'canal-json',
> 'scan.startup.mode' = 'latest-offset'
> );
Flink SQL> select * from t1;
在 MySQL 中在插入一条测试数据:
mysql> insert into test.t2 values(2);
Query OK, 1 row affected (0.00 sec)
从 Flink 中可以实时同步数据:
Flink SQL> select * from t1;
Refresh: 1 s Page: Last of 1 Updated: 02:49:27.366
id
2
Flink -> TiDB 通路
在 下游的 TiDB 中创建用于测试的表
[root@r20 soft]# mysql -uroot -P14000 -hr21
mysql> create table t3 (id int);
Query OK, 0 rows affected (0.31 sec)
在 Flink 中创建测试表
Flink SQL> CREATE TABLE t3 (
> id int
> ) with (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://192.168.12.21:14000/test',
> 'table-name' = 't3',
> 'username' = 'root',
> 'password' = 'mysql'
> );
Flink SQL> insert into t3 values(3);
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: a0827487030db177ee7e5c8575ef714e
在下游 TiDB 中查看插入的数据
mysql> select * from test.t3;
+------+
| id |
+------+
| 3 |
+------+
1 row in set (0.00 sec)
本文转自:https://asktug.com/t/topic/68731 作者:懂的都懂
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界


公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug ????
以上是关于Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB的主要内容,如果未能解决你的问题,请参考以下文章
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Flink 最佳实践之 通过 TiCDC 将 TiDB 数据流入 Flink