Flink 最佳实践之 通过 TiCDC 将 TiDB 数据流入 Flink
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 最佳实践之 通过 TiCDC 将 TiDB 数据流入 Flink相关的知识,希望对你有一定的参考价值。
背景介绍
本文将介绍如何将 TiDB 中的数据,通过 TiCDC 导入到 Kafka 中,继而被 Flink 消费的案例。
为了能够快速的验证整套流程的功能性,所有的组件都以单机的形式部署。如果需要在生产环境中部署,建议将每一个组件替换成高可用的集群部署方案。
其中,我们单独创建了一套 Zookeeper 单节点环境,Flink、Kafka、等组件共用这个 Zookeeper 环境。
针对于所有需要 JRE 的组件,如 Flink,Kafka,Zookeeper,考虑到升级 JRE 可能会影响到其他的应用,我们选择每个组件独立使用自己的 JRE 环境。
本文分为两个部分,其中,前五小节主要介绍基础环境的搭建,最后一个小节介绍了数据是如何在各个组件中流通的。

应用场景介绍
TiDB + Flink 的结构,支持开发与运行多种不同种类的应用程序。
目前主要的特性主要包括:
批流一体化
精密的状态管理
事件时间支持
精确的一次状态一致性保障
Flink 可以运行在包括 YARN、Mesos、Kubernetes 在内的多种资源管理框架上,还支持裸机集群上独立部署。TiDB 可以部署 AWS、Kubernetes、GCP GKE 上,同时也支持使用 TiUP 在裸机集群上独立部署。
TiDB + Flink 结构常见的几类应用如下:
事件驱动型应用
反欺诈
异常检测
基于规则的报警
业务流程监控
数据分析应用
网络质量监控
产品更新及试验评估分析
事实数据即席分析
大规模图分析
数据管道应用
电商实时查询索引构建
电商持续 ETL
操作系统环境
[root@r20 topology]# cat /etc/redhat-release
CentOS Stream release 8
软件环境

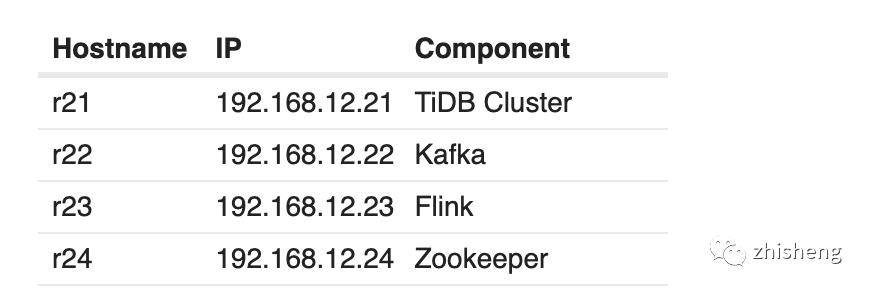
机器分配
部署 TiDB Cluster
与传统的单机数据库相比,TiDB 具有以下优势:
纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
支持 SQL,对外暴露 mysql 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:
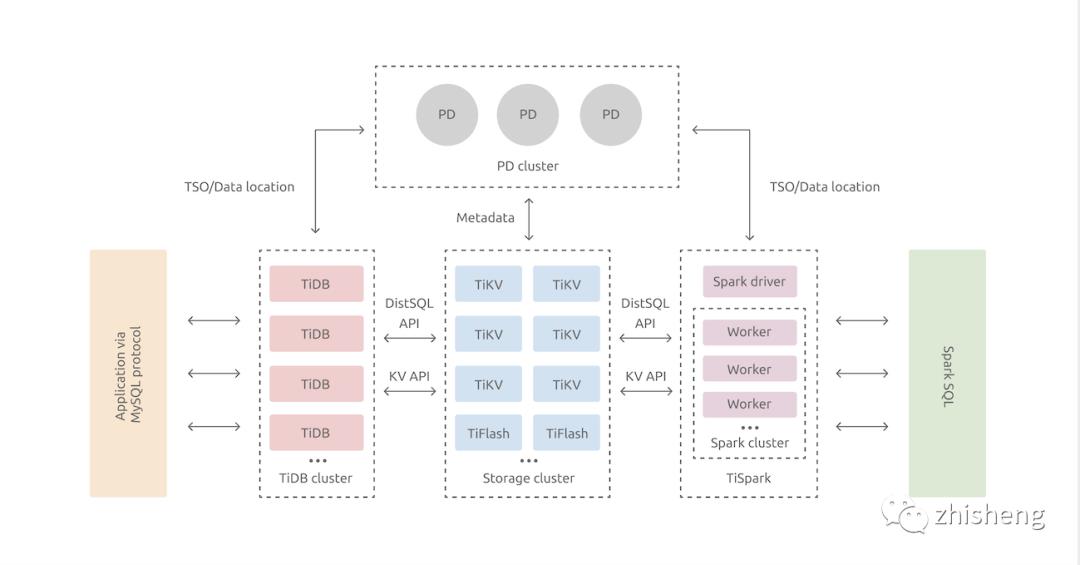
在本文中,我们只做最简单的功能测试,所以部署了一套单节点但副本的 TiDB,涉及到了以下的三个模块:
TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。
PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。
TiUP 部署模板文件
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/opt/tidb-c1/"
data_dir: "/opt/tidb-c1/data/"
# # Monitored variables are applied to all the machines.
#monitored:
# node_exporter_port: 19100
# blackbox_exporter_port: 39115
# deploy_dir: "/opt/tidb-c3/monitored"
# data_dir: "/opt/tidb-c3/data/monitored"
# log_dir: "/opt/tidb-c3/log/monitored"
# # Server configs are used to specify the runtime configuration of TiDB components.
# # All configuration items can be found in TiDB docs:
# # - TiDB: https://pingcap.com/docs/stable/reference/configuration/tidb-server/configuration-file/
# # - TiKV: https://pingcap.com/docs/stable/reference/configuration/tikv-server/configuration-file/
# # - PD: https://pingcap.com/docs/stable/reference/configuration/pd-server/configuration-file/
# # All configuration items use points to represent the hierarchy, e.g:
# # readpool.storage.use-unified-pool
# #
# # You can overwrite this configuration via the instance-level `config` field.
server_configs:
tidb:
log.slow-threshold: 300
binlog.enable: false
binlog.ignore-error: false
tikv-client.copr-cache.enable: true
tikv:
server.grpc-concurrency: 4
raftstore.apply-pool-size: 2
raftstore.store-pool-size: 2
rocksdb.max-sub-compactions: 1
storage.block-cache.capacity: "16GB"
readpool.unified.max-thread-count: 12
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
raftdb.rate-bytes-per-sec: 0
pd:
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
pd_servers:
- host: 192.168.12.21
ssh_port: 22
name: "pd-2"
client_port: 12379
peer_port: 12380
deploy_dir: "/opt/tidb-c1/pd-12379"
data_dir: "/opt/tidb-c1/data/pd-12379"
log_dir: "/opt/tidb-c1/log/pd-12379"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.pd` values.
config:
schedule.max-merge-region-size: 20
schedule.max-merge-region-keys: 200000
tidb_servers:
- host: 192.168.12.21
ssh_port: 22
port: 14000
status_port: 12080
deploy_dir: "/opt/tidb-c1/tidb-14000"
log_dir: "/opt/tidb-c1/log/tidb-14000"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tidb` values.
config:
log.slow-query-file: tidb-slow-overwrited.log
tikv-client.copr-cache.enable: true
tikv_servers:
- host: 192.168.12.21
ssh_port: 22
port: 12160
status_port: 12180
deploy_dir: "/opt/tidb-c1/tikv-12160"
data_dir: "/opt/tidb-c1/data/tikv-12160"
log_dir: "/opt/tidb-c1/log/tikv-12160"
numa_node: "0"
# # The following configs are used to overwrite the `server_configs.tikv` values.
config:
server.grpc-concurrency: 4
#server.labels: { zone: "zone1", dc: "dc1", host: "host1" }
#monitoring_servers:
# - host: 192.168.12.21
# ssh_port: 22
# port: 19090
# deploy_dir: "/opt/tidb-c1/prometheus-19090"
# data_dir: "/opt/tidb-c1/data/prometheus-19090"
# log_dir: "/opt/tidb-c1/log/prometheus-19090"
#grafana_servers:
# - host: 192.168.12.21
# port: 13000
# deploy_dir: "/opt/tidb-c1/grafana-13000"
#alertmanager_servers:
# - host: 192.168.12.21
# ssh_port: 22
# web_port: 19093
# cluster_port: 19094
# deploy_dir: "/opt/tidb-c1/alertmanager-19093"
# data_dir: "/opt/tidb-c1/data/alertmanager-19093"
# log_dir: "/opt/tidb-c1/log/alertmanager-19093"
TiDB Cluster 环境
本文重点并非部署 TiDB Cluster,作为快速实验环境,只在一台机器上部署单副本的 TiDB Cluster 集群。不需要部署监控环境。
[root@r20 topology]# tiup cluster display tidb-c1-v409
Starting component `cluster`: /root/.tiup/components/cluster/v1.3.2/tiup-cluster display tidb-c1-v409
Cluster type: tidb
Cluster name: tidb-c1-v409
Cluster version: v4.0.9
SSH type: builtin
Dashboard URL: http://192.168.12.21:12379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
192.168.12.21:12379 pd 192.168.12.21 12379/12380 linux/x86_64 Up|L|UI /opt/tidb-c1/data/pd-12379 /opt/tidb-c1/pd-12379
192.168.12.21:14000 tidb 192.168.12.21 14000/12080 linux/x86_64 Up - /opt/tidb-c1/tidb-14000
192.168.12.21:12160 tikv 192.168.12.21 12160/12180 linux/x86_64 Up /opt/tidb-c1/data/tikv-12160 /opt/tidb-c1/tikv-12160
Total nodes: 4
创建用于测试的表
mysql> show create table t1;
+-------+-------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`id` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin |
+-------+-------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
部署 Zookeeper 环境
在本实验中单独配置 Zookeeper 环境,为 Kafka 和 Flink 环境提供服务。
作为实验演示方案,只部署单机环境。
解压 Zookeeper 包
[root@r24 soft]# tar vxzf apache-zookeeper-3.6.2-bin.tar.gz
[root@r24 soft]# mv apache-zookeeper-3.6.2-bin /opt/zookeeper
部署用于 Zookeeper 的 jre
[root@r24 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r24 soft]# mv jre1.8.0_281 /opt/zookeeper/jre
修改 /opt/zookeeper/bin/zkEnv.sh 文件,增加 JAVA_HOME 环境变量
## add bellowing env var in the head of zkEnv.sh
JAVA_HOME=/opt/zookeeper/jre
创建 Zookeeper 的配置文件
[root@r24 conf]# cat zoo.cfg | grep -v "#"
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
clientPort=2181
启动 Zookeeper
[root@r24 bin]# /opt/zookeeper/bin/zkServer.sh start
检查 Zookeeper 的状态
## check zk status
[root@r24 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
## check OS port status
[root@r24 bin]# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 942/sshd
tcp6 0 0 :::2181 :::* LISTEN 15062/java
tcp6 0 0 :::8080 :::* LISTEN 15062/java
tcp6 0 0 :::22 :::* LISTEN 942/sshd
tcp6 0 0 :::44505 :::* LISTEN 15062/java
## use zkCli tool to check zk connection
[root@r24 bin]# ./zkCli.sh -server 192.168.12.24:2181
关于 Zookeeper 的建议
我个人有一个关于 Zookeeper 的不成熟的小建议:
Zookeeper 集群版本一定要开启网络监控。
特别是要关注 system metrics 里面的 network bandwidth。
部署 Kafka
Kafka 是一个分布式流处理平台,主要应用于两大类的应用中:
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。(相当于message queue)
构建实时流式应用程序,对这些流数据进行转换或者影响。(就是流处理,通过kafka stream topic和topic之间内部进行变化)
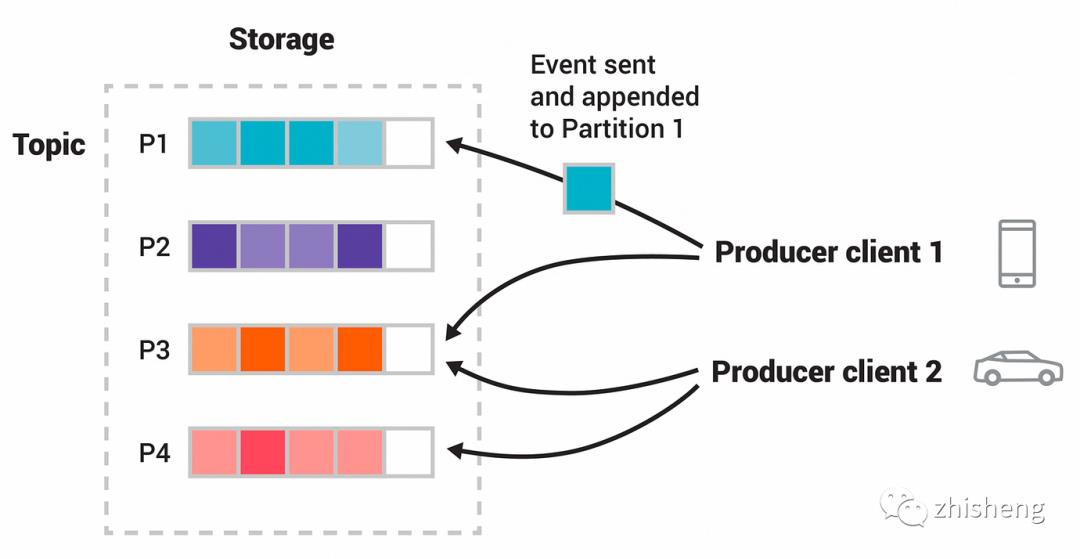
Kafka 有四个核心的 API:
The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
The Consumer API 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
在本实验中只做功能性验证,只搭建一个单机版的 Kafka 环境。
下载并解压 Kafka
[root@r22 soft]# tar vxzf kafka_2.13-2.7.0.tgz
[root@r22 soft]# mv kafka_2.13-2.7.0 /opt/kafka
部署用于 Kafka 的 jre
[root@r22 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r22 soft]# mv jre1.8.0_281 /opt/kafka/jre
修改 Kafka 的 jre 环境变量
[root@r22 bin]# vim /opt/kafka/bin/kafka-run-class.sh
## add bellowing line in the head of kafka-run-class.sh
JAVA_HOME=/opt/kafka/jre
修改 Kafka 配置文件
修改 Kafka 配置文件 /opt/kafka/config/server.properties
## change bellowing variable in /opt/kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.12.22:9092
log.dirs=/opt/kafka/logs
zookeeper.connect=i192.168.12.24:2181
启动 Kafka
[root@r22 bin]# /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
查看 Kafka 的版本信息
Kafka 并没有提供 --version 的 optional 来查看 Kafka 的版本信息。
[root@r22 ~]# ll /opt/kafka/libs/ | grep kafka
-rw-r--r-- 1 root root 4929521 Dec 16 09:02 kafka_2.13-2.7.0.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0.jar.asc
-rw-r--r-- 1 root root 41793 Dec 16 09:02 kafka_2.13-2.7.0-javadoc.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-javadoc.jar.asc
-rw-r--r-- 1 root root 892036 Dec 16 09:02 kafka_2.13-2.7.0-sources.jar
-rw-r--r-- 1 root root 821 Dec 16 09:03 kafka_2.13-2.7.0-sources.jar.asc
... ...
其中 2.13 是 scale 的版本信息,2.7.0 是 Kafka 的版本信息。
部署 Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
支持高吞吐、低延迟、高性能的分布式处理框架Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
本实验只做功能性测试,仅部署单机 Flink 环境。
下载并分发 Flink
[root@r23 soft]# tar vxzf flink-1.12.1-bin-scala_2.11.tgz
[root@r23 soft]# mv flink-1.12.1 /opt/flink
部署 Flink 的 jre
[root@r23 soft]# tar vxzf jre1.8.0_281.tar.gz
[root@r23 soft]# mv jre1.8.0_281 /opt/flink/jre
添加 Flink 需要的 lib
Flink 消费 Kafka 数据,需要 flink-sql-connector-kafka 包
Flink 链接 MySQL/TiDB,需要 flink-connector-jdbc 包
[root@r23 soft]# mv flink-sql-connector-kafka_2.12-1.12.0.jar /opt/flink/lib/
[root@r23 soft]# mv flink-connector-jdbc_2.12-1.12.0.jar /opt/flink/lib/
修改 Flink 配置文件
## add or modify bellowing lines in /opt/flink/conf/flink-conf.yaml
jobmanager.rpc.address: 192.168.12.23
env.java.home: /opt/flink/jre
启动 Flink
[root@r23 ~]# /opt/flink/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host r23.
Starting taskexecutor daemon on host r23.
查看 Flink GUI
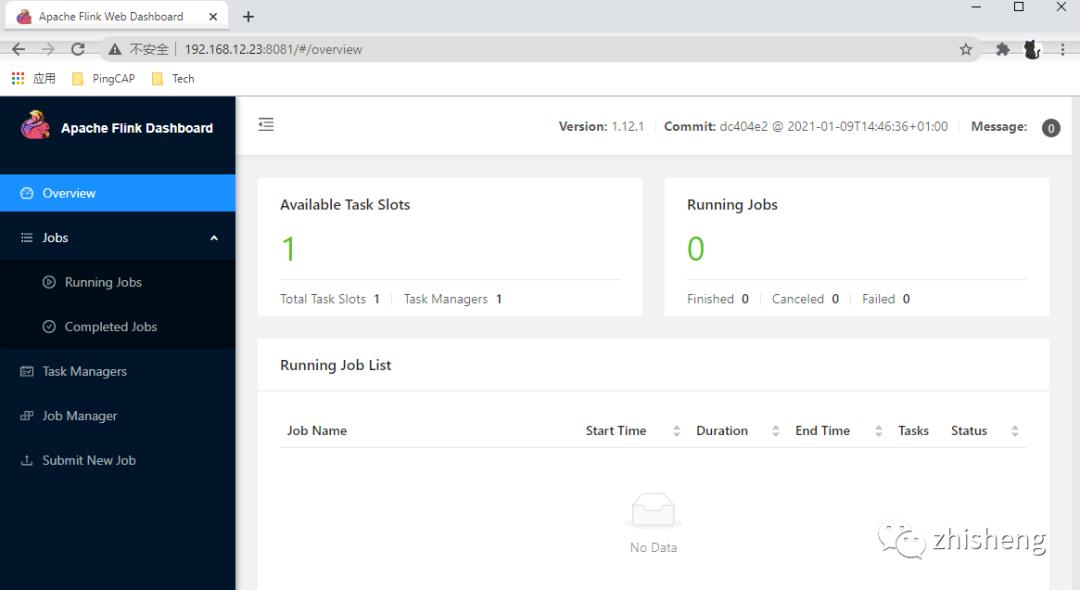
配置数据流向
ticdc -> Kafka 通路
TiCDC 运行时是一种无状态节点,通过 PD 内部的 etcd 实现高可用。TiCDC 集群支持创建多个同步任务,向多个不同的下游进行数据同步。
TiCDC 的系统架构如下图所示:
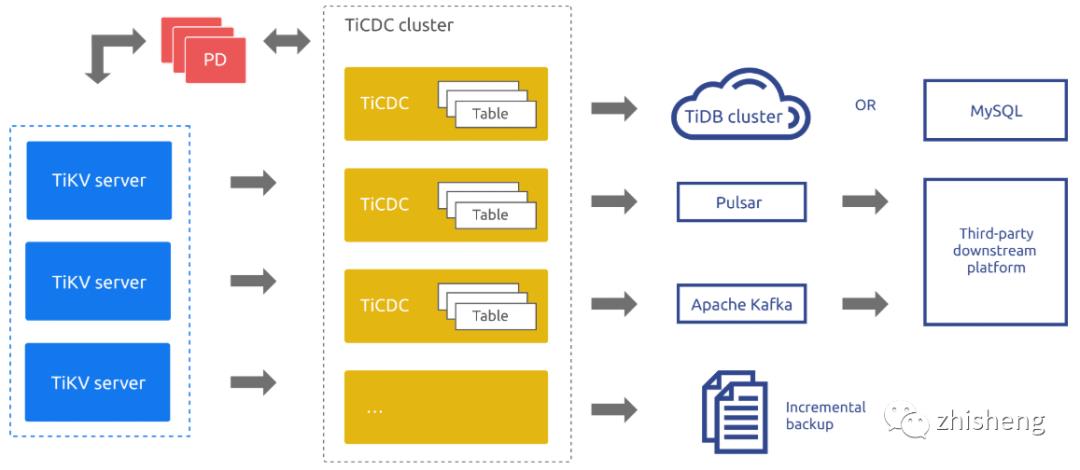
TiCDC 的系统角色:
TiKV CDC 组件:只输出 key-value (KV) change log。
内部逻辑拼装 KV change log。
提供输出 KV change log 的接口,发送数据包括实时 change log 和增量扫的 change log。
Capture:TiCDC 运行进程,多个 capture 组成一个 TiCDC 集群,负责 KV change log 的同步。
每个 capture 负责拉取一部分 KV change log。
对拉取的一个或多个 KV change log 进行排序。
向下游还原事务或按照 TiCDC Open Protocol 进行输出。
创建一个 Kafka Topic
创建 Kafka Topic ticdc-test
[root@r22 ~]# /opt/kafka/bin/kafka-topics.sh --create \\
> --zookeeper 192.168.12.24:2181 \\
> --config max.message.bytes=12800000 \\
> --config flush.messages=1 \\
> --replication-factor 1 \\
> --partitions 1 \\
> --topic ticdc-test
Created topic ticdc-test.
查看 Kafka 中所有的 Topic
[root@r22 ~]# /opt/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.12.24:2181
ticdc-test
查看 Kafka 中 Topic ticdc-test 的信息
[root@r22 ~]# /opt/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.12.24:2181 --topic ticdc-test
Topic: ticdc-test PartitionCount: 1 ReplicationFactor: 1 Configs: max.message.bytes=12800000,flush.messages=1
Topic: ticdc-test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
在 TiCDC 中创建 Kafka 的changefeed
创建 changefeed 配置文件,打开 enable-old-value:
## create a changefeed configuration file
[root@r21 ~]# cat /opt/tidb-c1/cdc-18300/conf/cdc-changefeed-old-value-enabled.conf
enable-old-value=true
创建 Kafka 的 changefeed:
## create a changefeed for kafka
[root@r21 ~]# /opt/tidb-c1/cdc-18300/bin/cdc cli changefeed create \\
> --pd=http://192.168.12.21:12379 \\
> --sink-uri="kafka://192.168.12.22:9092/ticdc-test?kafka-version=2.7.0&partition-num=1&max-message-bytes=67108864&replication-factor=1&enable-old-value=true&protocol=canal-json" \\
> --changefeed-id="ticdc-kafka" \\
> --config=/opt/tidb-c1/cdc-18300/conf/cdc-changefeed-old-value-enabled.conf
Create changefeed successfully!
ID: ticdc-kafka
Info: {"sink-uri":"kafka://192.168.12.22:9092/ticdc-test?kafka-version=2.7.0\\u0026artition-num=1\\u0026max-message-bytes=67108864\\u0026replication-factor=1\\u0026enable-old-value=true\\u0026protocol=canal-json","opts":{"max-message-bytes":"67108864"},"create-time":"2021-02-22T00:08:50.185073755-05:00","start-ts":423092690661933057,"target-ts":0,"admin-job-type":0,"sort-engine":"memory","sort-dir":".","config":{"case-sensitive":true,"enable-old-value":true,"force-replicate":false,"check-gc-safe-point":true,"filter":{"rules":["*.*"],"ignore-txn-start-ts":null,"ddl-allow-list":null},"mounter":{"worker-num":16},"sink":{"dispatchers":null,"protocol":"canal-json"},"cyclic-replication":{"enable":false,"replica-id":0,"filter-replica-ids":null,"id-buckets":0,"sync-ddl":false},"scheduler":{"type":"table-number","polling-time":-1}},"state":"normal","history":null,"error":null,"sync-point-enabled":false,"sync-point-interval":600000000000}
[root@r21 ~]# cat /opt/tidb-c1/cdc-18300/conf/cdc-changefeed-old-value-enabled.conf
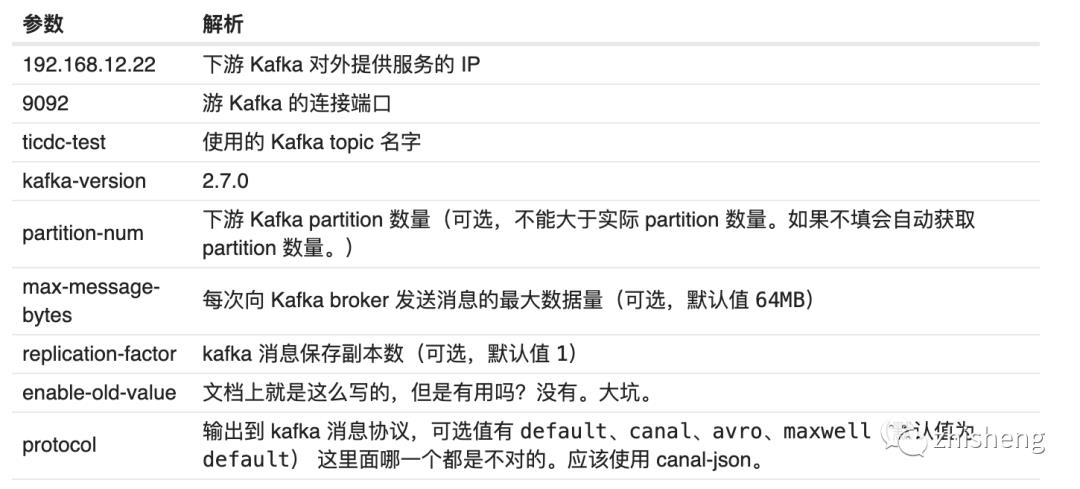
其中 Kafka 的 sink url 参数配置如下:
查看已经创建的 changefeed:
[root@r21 ~]# /opt/tidb-c1/cdc-18300/bin/cdc cli changefeed --pd=http://192.168.12.21:12379 list
[
{
"id": "ticdc-kafka",
"summary": {
"state": "normal",
"tso": 423092789699936258,
"checkpoint": "2021-02-22 00:15:07.974",
"error": null
}
}
]
查看 ticdc-kafka changefeed 的信息:
[root@r21 ~]# /opt/tidb-c1/cdc-18300/bin/cdc cli changefeed --pd=http://192.168.12.21:12379 query -c ticdc-kafka
{
"info": {
"sink-uri": "kafka://192.168.12.22:9092/ticdc-test?kafka-version=2.7.0\\u0026artition-num=1\\u0026max-message-bytes=67108864\\u0026replication-factor=1\\u0026enable-old-value=true\\u0026protocol=canal -json",
"opts": {
"max-message-bytes": "67108864"
},
"create-time": "2021-02-22T00:08:50.185073755-05:00",
"start-ts": 423092690661933057,
"target-ts": 0,
"admin-job-type": 0,
"sort-engine": "memory",
"sort-dir": ".",
"config": {
"case-sensitive": true,
"enable-old-value": true,
"force-replicate": false,
"check-gc-safe-point": true,
"filter": {
"rules": [
"*.*"
],
"ignore-txn-start-ts": null,
"ddl-allow-list": null
},
"mounter": {
"worker-num": 16
},
"sink": {
"dispatchers": null,
"protocol": "canal-json"
},
"cyclic-replication": {
"enable": false,
"replica-id": 0,
"filter-replica-ids": null,
"id-buckets": 0,
"sync-ddl": false
},
"scheduler": {
"type": "table-number",
"polling-time": -1
}
},
"state": "normal",
"history": null,
"error": null,
"sync-point-enabled": false,
"sync-point-interval": 600000000000
},
"status": {
"resolved-ts": 423093295690285057,
"checkpoint-ts": 423093295428403201,
"admin-job-type": 0
},
"count": 0,
"task-status": []
}
查看 Kafka 中 consumer 信息
在 TiCDC 中创建 Kafka 的 changefeed,将数据流向 Kafka 中的 ticdc-test topic 后,TiCDC -> Kafka 的通道就已经建立了。
插入一条数据用以测试:
mysql> insert into t1 values(1);
Query OK, 1 row affected (0.00 sec)
可以看到 TiCDC 的日志输出中有以下信息:
[2021/02/22 01:14:02.816 -05:00] [INFO] [statistics.go:118] ["sink replication status"] [name=MQ] [changefeed=ticdc-kafka] [captureaddr=192.168.12.21:18300] [count=1] [qps=0]
此时查看 Kafka 的 consumer 信息,可以看到数据已经过来了:
[root@r22 bin]# /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.12.22:9092 --topic ticdc-test --from-beginning
{"id":0,"database":"test","table":"t1","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1613974420325,"ts":0,"sql":"","sqlType":{"id":-5},"mysqlType":{"id":"int"},"data":[{"id":"1"}],"old":[null]}
Kafka -> Flink 通路
在 Flink 的 sql-client 中,创建 t1 表,connector 使用 kafka 类型:
[root@r23 ~]# /opt/flink/bin/sql-client.sh embedded
## create a test table t1 in
Flink SQL> create table t1(id int)
> WITH (
> 'connector' = 'kafka',
> 'topic' = 'ticdc-test',
> 'properties.bootstrap.servers' = '192.168.12.22:9092',
> 'properties.group.id' = 'cdc-test-consumer-group',
> 'format' = 'canal-json',
> 'scan.startup.mode' = 'latest-offset'
> );
Flink SQL> select * from t1;
在 TiDB 中插入数据,从 Flink 中进行查询:
## insert a test row in TiDB
mysql> insert into test.t1 values(4);
Query OK, 1 row affected (0.00 sec)
## check the result from Flink
SQL Query Result (Table)
Refresh: 1 s Page: Last of 1 Updated: 03:02:28.838
id
4
本文转自:https://asktug.com/t/topic/68884 作者:懂的都懂
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统关于数据中台的深度思考与总结(干干货)日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug ????
以上是关于Flink 最佳实践之 通过 TiCDC 将 TiDB 数据流入 Flink的主要内容,如果未能解决你的问题,请参考以下文章
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB