安装hadoop集群模拟大数据集群踩到的坑
Posted blind_mokey
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安装hadoop集群模拟大数据集群踩到的坑相关的知识,希望对你有一定的参考价值。
1.安装虚拟机
使用VMWARE安装虚拟机CentOS7时候踩到的第一个坑,当安装完毕CentOS7的时候,使用vmware workstation pro 14进行启动虚拟机,win10系统有概率蓝屏重启报错,这时候就需要更新到更高版本的VMware workstation pro 16进行安装,因为这是兼容性问题,升级到16之后就没有蓝屏问题。
2.布置虚拟环境
参考本人最早的一篇centos7最小化安装开始,几年前写的文档帮我填了坑
紧接着测试是否能连通DNS
#ping www.baidu.com
发现没办法ping通,然后ping 公网服务器IP,发现可以ping通,就知道是DNS的问题,在/etc/sysconfig/network-scripts/ifcfg-ens33(这是网卡的驱动脚本,根据自己实际情况进行修改)文件中修改获取IP方式和DNS地址
#vi /etc/sysconfig/network-scripts/ifcfg-ens33
然后我改成了这样
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static #修改为静态IP
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=b8f3e8d2-5fdc-4261-a740-111272b77e0f
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.153.129#修改为静态IP指定地址
NETMASK=255.255.255.0#子网掩码
GATEWAY=192.168.153.2#网关
DNS1=8.8.8.8#DNS服务器
紧接着重启network
#service network restart
再ping一下百度,成功。
3.安装wget 和更改国内镜像源mirror163
#yum install wget
下载repo文件
#wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
备份并替换系统的repo文件
#cp CentOS7-Base-163.repo /etc/yum.repos.d/
#cd /etc/yum.repos.d/
#mv CentOS-Base.repo CentOS-Base.repo.bak
#mv CentOS7-Base-163.repo CentOS-Base.repo
执行yum源更新命令
#yum clean all
#yum makecache
#yum update
这个时候已经更改为国内的镜像YUM源,可以放心食用。
紧接着我们安装JDK
4.jdk与hadoop
首先我们查找对应的hadoop版本,我这里安装的是hadoop 2.10.1
官网指路:hadoop官网
然后下载hadoop二进制文件到虚拟机当中,推荐http浏览器下载或者迅雷下载之后通过xftp之类的传输文件到虚拟机当中,然后进行解压缩
#tar -zxvf hadoop-2.10.1.tar.gz
因为hadoop依赖于java jdk,所以我们需要安装jdk,2.10.1的hadoop需要1.17以上的jdk
#yum search jdk
得到如下结果
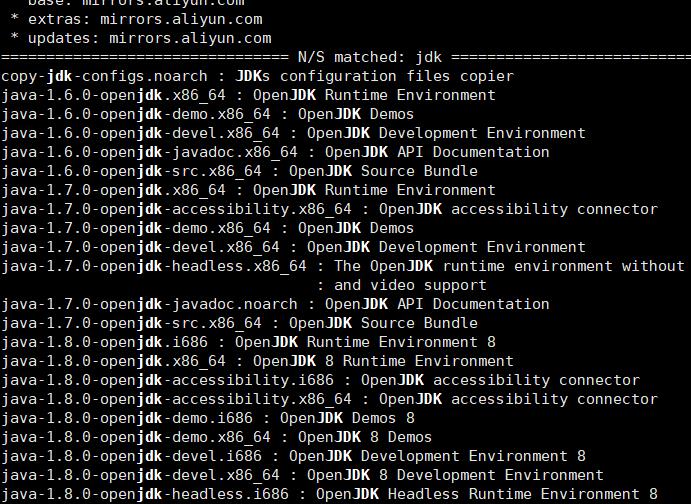
果断选择1.18版本jdk
#yum install java-1.8.0-openjdk.x86_64
安装完毕之后验证java版本
#java -version
如果正确显示版本就安装成功
紧接着我们安装hadoop,我这里不赘述了
参考文档:CentOS安装hadoop
这里有坑,需要修改三个地方,第一个地方是hadoop文件夹下的脚本
#vi hadoop-env.sh
这里需要把java_home写清楚
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64
怎么写清楚呢?
which java
/usr/bin/java
$ ls -l /usr/bin/java
lrwxrwxrwx. 1 root root 22 7月 16 11:38 /usr/bin/java -> /etc/alternatives/java
$ ls -l /etc/alternatives/java
lrwxrwxrwx. 1 root root 73 7月 16 11:38 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64/jre/bin/java
最后那一长串才是jdk的目录
然后我们还要修改
#sudo vi /etc/profile
添加如下内容
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存,初始化hadoop,这时候才成功
如果上述情况无法完成JDK环境配置的话,可以前往Oracle官网进行LINUX的JDK下载,然后解压缩后配置到java_home里面
下载完之后放在download文件夹中,进行解压缩
#tar -zxvf jdk-16.0.1.tar.gz
#mv jdk-16.0.1 /usr/lib/jvm/
移动到这个位置,将JAVA_HOME设置为这个路径也能JAVA运行成功,最后初始化的界面如图所示
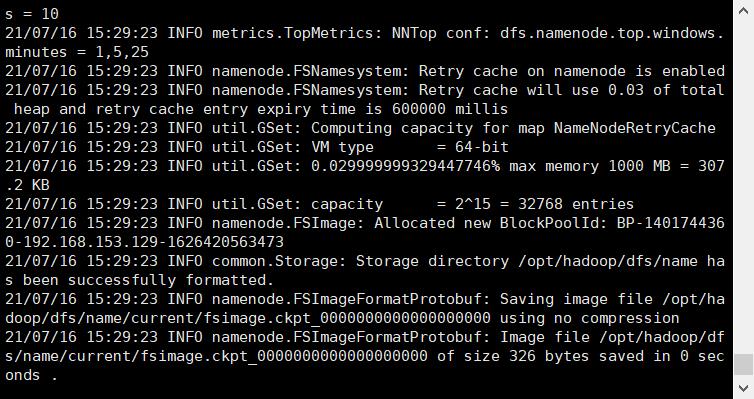
好了,到这里集群已经安装成功了!
以上是关于安装hadoop集群模拟大数据集群踩到的坑的主要内容,如果未能解决你的问题,请参考以下文章