浙江移动大规模Hadoop集群运维踩过的坑及应对
Posted 三墩IT人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浙江移动大规模Hadoop集群运维踩过的坑及应对相关的知识,希望对你有一定的参考价值。
随着近年来移动互联网的飞速发展,更多、更广的数据不断产生,大数据平台技术的日益成熟也为各类大数据应用落地提供着有力支撑。浙江移动自2015年开始,基于“数据融合”、“平台共享”、“应用创新”的平台建设理念开始大数据平台的统一建设、运营工作。经过近3年的发展,当前大数据平台已经支撑了上百个应用,近千名开发者,数十PB的数据容量。应用与数据的增长也促使平台自身规模的增加,夯实大规模集群管理能力成为当前大数据平台运维的重点。
现网大数据平台采用Hadoop生态为主,MPP、流处理、内存库等多种技术混搭的架构,其中Hadoop资源池占比超过80%,某核心集群在三期扩容完成后即将突破1000节点。集群规模的增长对平台的支撑能力提出了挑战,部分集群内部服务组件在高并发、高吞吐的需求环境中也成为整个集群的瓶颈。
1. Namenode负载优化
Namenode作为hdfs分布式文件系统的大脑,记录了所有数据块的位置信息。一切针对hdfs数据文件的读写操作,必须先从Namenode中获取相关数据块位置。Namenode的响应能力将直接影响数据的读写性能。16年底,大数据平台某核心集群hdfs写入性能出现下降,部分hive 查询出现超时。大数据工程师通过beeline登陆检查发现所有hdfs相关命令反应迟钝。通过排查确认当时集群文件数达到近9000w个,文件数上升导致namenode内存耗尽出现full gc进而影响hdfs读写性能。
解决措施:
1) 优化namenode内存配置
namenode内存中驻留了整个hdfs数据块的位置信息。1G的内存大概可以存储100w个数据块信息。当时jvm内存参数设置为100G,9000w个数据块几乎占据所有的堆内存,导致频繁产生full gc 影响集群性能。在主机内存充足的情况下,通过增加namenode堆内存可以缓解该问题。
2) Hdfs小文件合并
Hdfs文件存储的基本单位为数据块,当前集群默认的块大小为128M,这也是建议的最小文件大小。另据统计,集群接近90%的MR任务由hive sql触发,通过对hive文件的强制合并可以确保输出结果的最小文件大小达到128M以上。
sethive.merge.mapfiles=true
sethive.merge.mapredfiles=true
sethive.merge.size.per.task=128000000
set hive.merge.smallfiles.avgsize=128000000
3) 对应用文件数量进行配额管理
以往对应用租户进行存储资源分配时,仅对存储容量进行限制,存在部分应用租户存储使用率不高,但是小文件过多影响了集群的整体性能。通过长期实践,我们总结出了集群存储容量:文件数最佳配比公式(最佳配比=集群存储容量/集群Namespace数*单Namespace最大承载文件数*0.9)。在租户存储资源分配时相应进行文件数配额限制,可以有效限制部分租户野蛮消耗文件数资源导致的集群性能问题,倒逼应用清理过期小文件并对长保留周期文件进行合并优化。文件数配额限制策略实施后,集群文件数增长速度由月均6%下降至1.5%,已累计减少了近4000万文件数的增长。
4) 通过联邦模式增加集群文件数承载能力
经评估,当前大数据平台hadoop集群单对namenode最大可承载文件数为10000w个。随着业务量的增在,优化namenode参数,对租户文件数进行配额限制,只能暂时缓解平台压力。如果要根本解决该问题,就需要进行架构改动,通过联邦模式扩充集群文件数承载能力。
联邦模式架构图如下:
目前大数据平台核心集群已经完成联邦模式改造,原本单对namenode承载的业务,通过数据文件命名空间改造被多对namenode承载。改造后,单对namenode承载的业务压力为改造前的1/3。理论上在此架构下,现有核心集群通过datanode扩容可以承载近3倍的业务压力。
2. Ldap负载优化
当前Hadoop集群采用openldap进行用户信息的集中管理。应用请求访问hadoop相关组件,需要先通过openldap的用户认证,相关架构如下图:
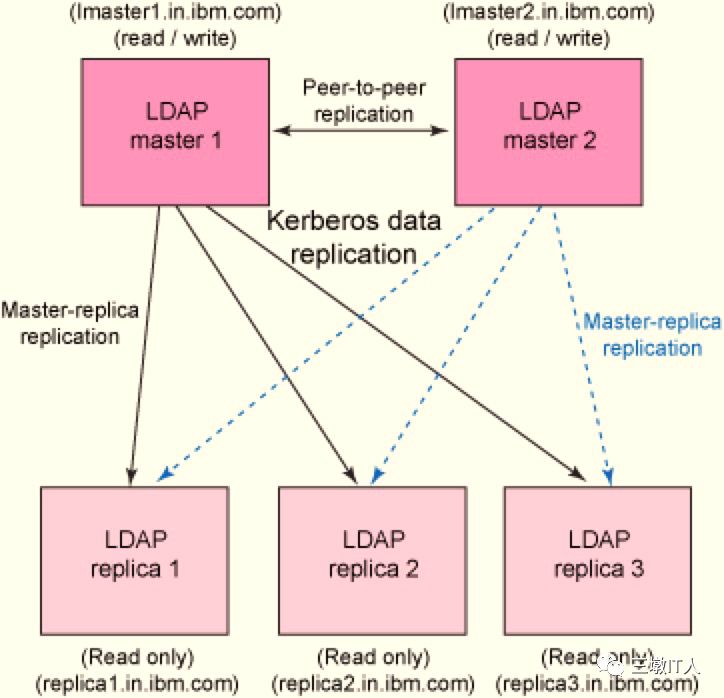
随着集群负载业务量的增加,现有的openldap也可能成为一个瓶颈点(根据我们的经验值,ldap每秒最大处理能力为250个左右)。
在一次Hadoop集群的滚动升级阶段,某应用租户反馈相关取数流程短时间内出现大量kerberos认证失败错误。通过查看告警时间点kerberos日志发现,该时刻kerberos服务请求积压明显,ldap每秒响应请求量达到250+次。进一步分析发现ldap进程所在节点CPU使用率较高,偶发性出现CPU使用达到1500%的现象。而当前ldap最多支持16路并发slapd线程,确认该问题是由于ldap性能达到瓶颈引起。
解决措施:
1) 限制应用的短连接
每次应用连接均需要调用ldap进行身份认证。在上述案例中就是因为部分租户频繁使用短连接进行小文件上传,占用大量ldap请求导致。对于这种现象,平台已对ldap日志进行了监控以便及时发现问题,提出预警。同时,应该加强应用开发的代码审核,尽量避免频繁创建短链接的现象。
2) 提升ldap服务器cpu性能
当前ldap官方只支持16路并发slapd线程,ldap自身的扩展能力受到很大限制,但是可以通过提升服务器cpu处理能力,达到提升ldap处理能力的效果
3) Ldap架构改造
当前ldap采用主备模式,备用ldap进程仅在主进程无法响应连接请求后才介入工作。通过对ldap的负载均衡改造,将只读访问分担至2个节点,将能够提升近一倍的连接请求响应能力。改造完成后,现有集群ldap处理能力将由250次/秒增加至450次/秒。
3. 集群管理服务优化
商用Hadoop产品都提供了自带的集群管理服务,功能涵盖组件启停、配置、指标采集/展现、告警监控等功能。当前平台在用的Hadoop集群管理服务架构如下:
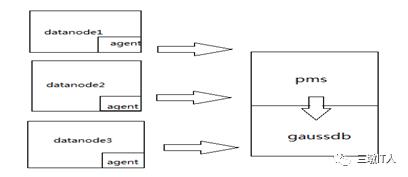
各类监控指标通过部署在hadoop节点上的agent采集,由 oms节点的pms进程进行预处理(指标汇聚,计算),结果写入oms节点本地gaussdb。在整个处理流程中,所有指标的汇聚计算都在oms节点内存中进行,集群规模的增长意味着内存需求的增加。以某集群为例,集群规模由200+增加到400+后,集群总指标数由6.5w+个增加到15w+个,pms相关指标计算的内存需求也增长了近3倍。另外用于指标存储的gaussdb也是一个本地轻量级数据库,无法承载大规模集群指标存储、计算、查询的压力。随着集群规模的增加,为了维持OMS服务的高效稳定,当前只提供最近一个月指标数据的查询分析,并对指标的采集频次进行了严格限制。
解决措施:
通过对集群管理服务的架构改造,利用大数据平台自有的多种分布式计算、存储组件,实现对各集群指标的采集、监控服务,具体架构图如下:
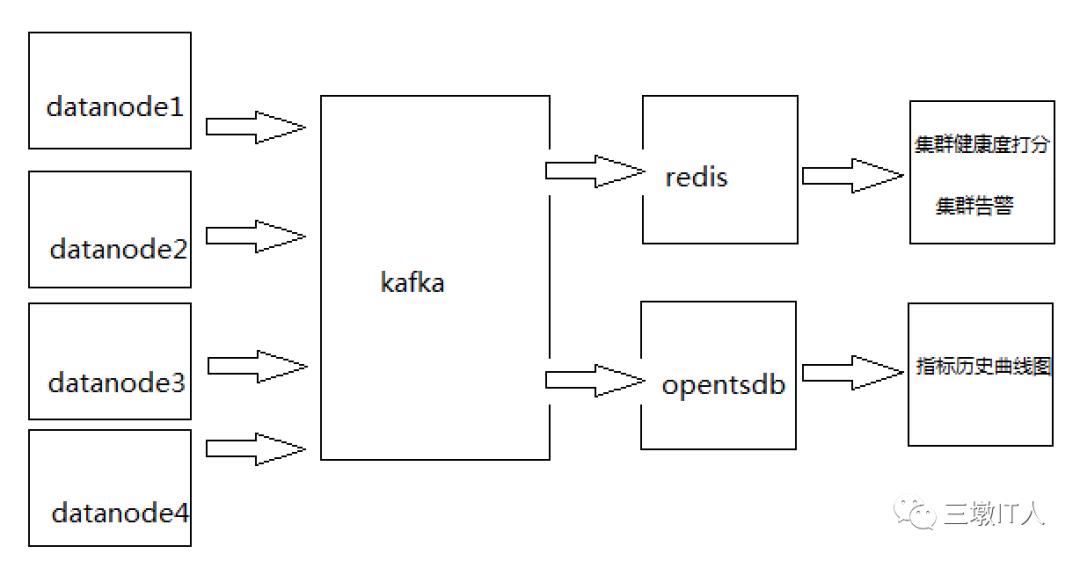
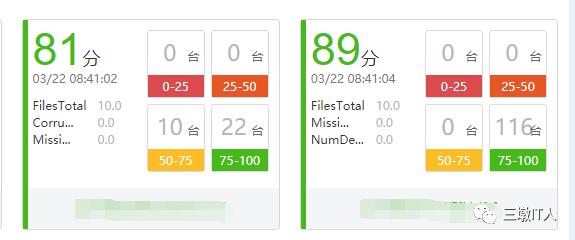
如上图所示通过kafka、redis、hbase(opentsdb)等组件的混搭使用,有效的解决了大数据平台海量指标的统一存储、分析、展现问题。改造后集群指标采集频次由5分钟提升至1分钟以内,历史指标存储周期也由1个月增加至3个月,为大数据工程师日常性能优化、故障分析提供了更详尽的数据支持。当前我们已基于该平台完成了集群组件健康度打分、告警展示、指标历史曲线展示等功能。
Hadoop作为分布式系统设计的典范,水平扩展能力一直是其拿手好戏,针对Hadoop的内部管理,同样可以通过水平扩展来解决单点的性能瓶颈,Namenode的联邦模式、Ldap双活、集群管理服务的大数据架构改造都遵循了该思路,并无二致。
以上是关于浙江移动大规模Hadoop集群运维踩过的坑及应对的主要内容,如果未能解决你的问题,请参考以下文章