[Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像相关的知识,希望对你有一定的参考价值。
从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章分享了生成对抗网络GAN的基础知识,包括什么是GAN、常用算法(CGAN、DCGAN、infoGAN、WGAN)、发展历程、预备知识,并通过Keras搭建最简答的手写数字图片生成案例。这篇文章将通过Keras深度学习构建CNN模型识别阿拉伯手写文字图像,一篇非常经典的图像分类文字。本文参考并复现了刘润森老师的博客,推荐大家关注他的文章,真的非常棒!让我们开始吧~
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\\DTC\\SVM\\KNN\\NB\\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
一.数据集描述
阿拉伯字母共有共有28个,如下图所示:

众所周知,手写识别数字是非常经典的图像分类数据集(MNIST),这里则使用kaggle的另一种数据集。该数据集是由60名参与者书写的16800个字符组成。
整个数据集在两种形式上写下每个字符(从“alef”到“yeh”)共十次,数据集包含文件如下图所示:
解压后如下图所示:
训练集共有13440个字符图像,28个类别,每章图像32x32大小,如下图所示。
- Train Images 13440x32x32

训练集共有3360个字符图像,28个类别,每章图像32x32大小,如下图所示。
- Test Images 3360x32x32

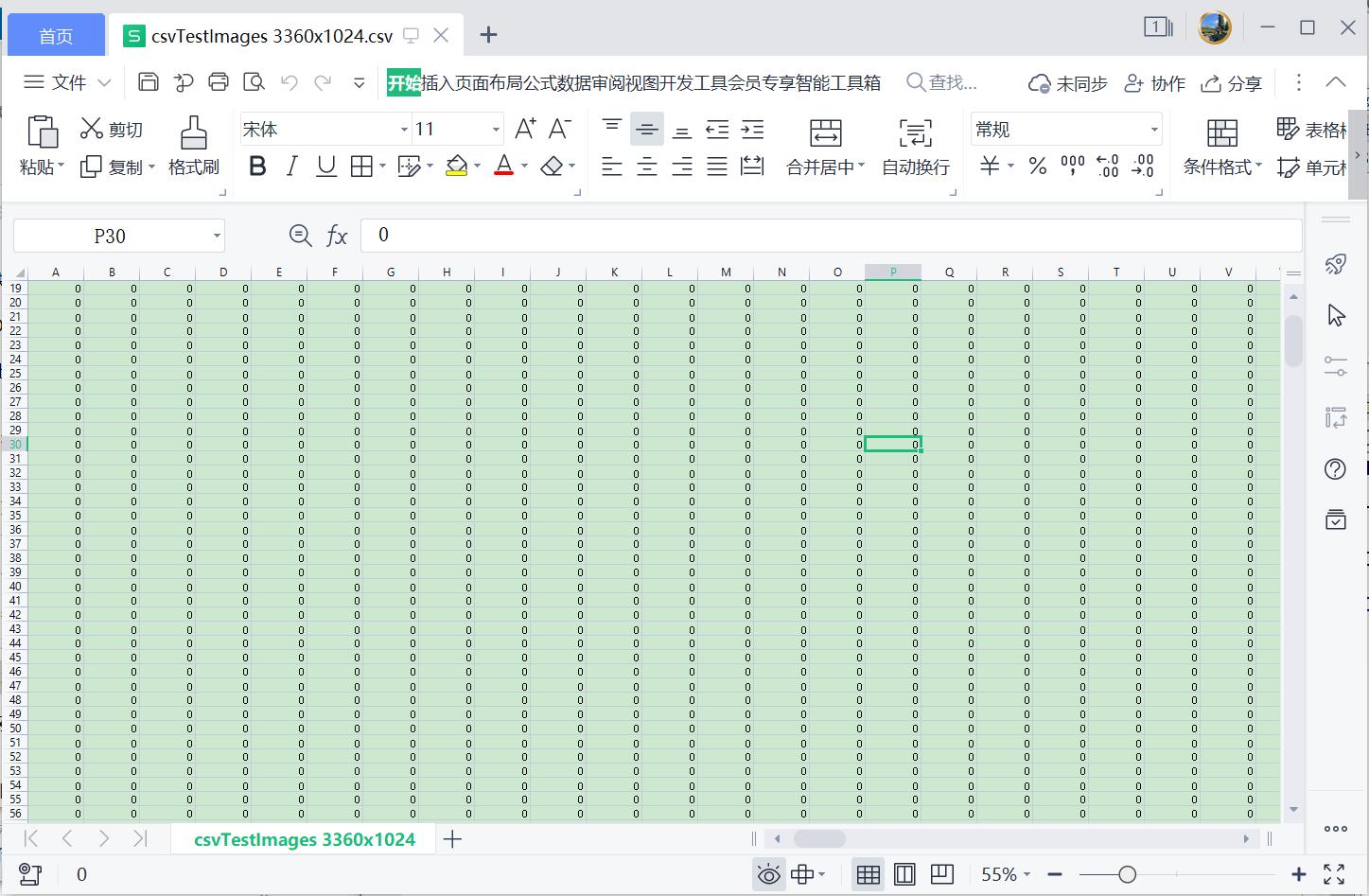
同时,数据集中包含CSV文件,对应图像像素的分布情况,比如测试集的数据如下图所示。
- csvTestImages 3360x1024.csv
对应的类别如下图所示,从1到28,因此在数据处理时应转换为0到27下标。
- csvTrainLabel 13440x1.csv
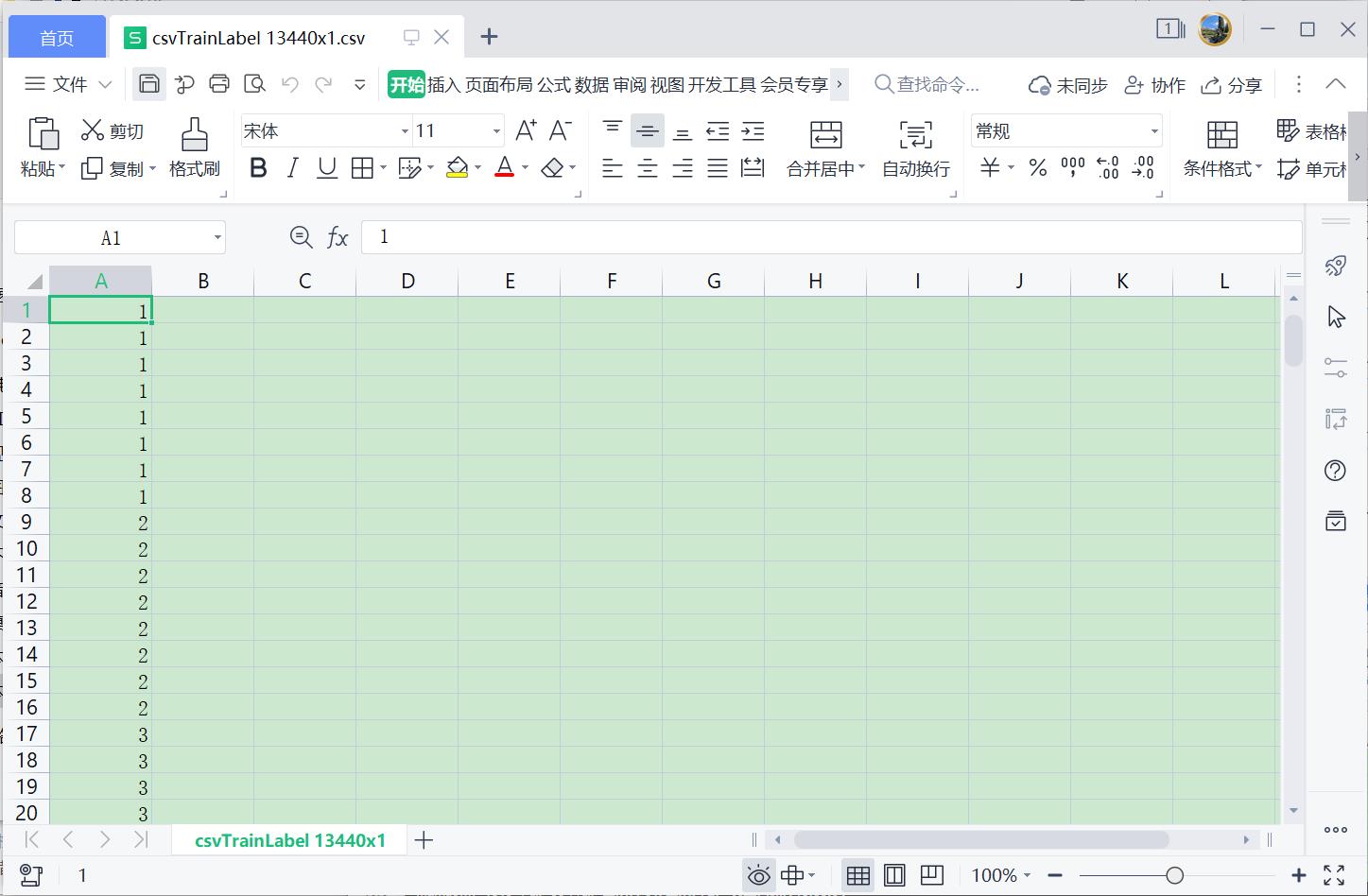
注意,很多时候图像数据集也会使用CSV文件存储,然后我们可以还原出对应的图像。只需要CSV的数据集和类别一一对应即可,接下来我们开始实验吧!
二.数据读取
# -*- coding: utf-8 -*-
"""
Created on Wed Jul 7 18:54:36 2021
@author: xiuzhang CSDN
参考:刘润森老师博客 推荐大家关注 很厉害的一位CV大佬
https://maoli.blog.csdn.net/article/details/117688738
"""
import numpy as np
import pandas as pd
from IPython.display import display
import csv
from PIL import Image
from scipy.ndimage import rotate
#----------------------------------------------------------------
# 第一步 读取数据
#----------------------------------------------------------------
#训练数据images和labels
letters_training_images_file_path = "dataset/csvTrainImages 13440x1024.csv"
letters_training_labels_file_path = "dataset/csvTrainLabel 13440x1.csv"
#测试数据images和labels
letters_testing_images_file_path = "dataset/csvTestImages 3360x1024.csv"
letters_testing_labels_file_path = "dataset/csvTestLabel 3360x1.csv"
#加载数据
training_letters_images = pd.read_csv(letters_training_images_file_path, header=None)
training_letters_labels = pd.read_csv(letters_training_labels_file_path, header=None)
testing_letters_images = pd.read_csv(letters_testing_images_file_path, header=None)
testing_letters_labels = pd.read_csv(letters_testing_labels_file_path, header=None)
print("%d个32x32像素的训练阿拉伯字母图像" % training_letters_images.shape[0])
print("%d个32x32像素的测试阿拉伯字母图像" % testing_letters_images.shape[0])
print(training_letters_images.head())
print(np.unique(training_letters_labels))
输出结果如下图所示:
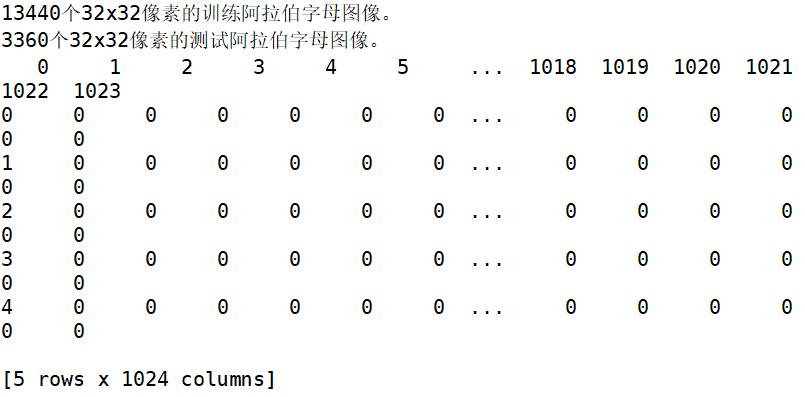
如果输出类别共有28类。
- [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28]
三.数据预处理
主要包括两个核心步骤:数值特征转换图像、图像标准化。
1.数值特征转换图像
接着尝试将CSV文件的数值特征转换为一张图像,图像像素为32x32。需要注意,由于原始数据集被反射,因此使用np.flip翻转图像,并通过rotate旋转从而获得更好的图像。
#----------------------------------------------------------------
# 第二步 数值转换为图像特征
#----------------------------------------------------------------
#原始数据集被反射使用np.flip翻转它 通过rotate旋转从而获得更好的图像
def convert_values_to_image(image_values, display=False):
#转换成32x32
image_array = np.asarray(image_values)
image_array = image_array.reshape(32,32).astype('uint8')
#翻转+旋转
image_array = np.flip(image_array, 0)
image_array = rotate(image_array, -90)
#图像显示
new_image = Image.fromarray(image_array)
if display == True:
new_image.show()
return new_image
convert_values_to_image(training_letters_images.loc[0], True)
输出结果是一张f字母。

2.图像标准化处理
图像标准化是将图像中的每个像素点除以255,从而缩放并标准化到[0, 1]范围。同时,数据类型进行相应转换。
#----------------------------------------------------------------
# 第三步 图像标准化处理
#----------------------------------------------------------------
training_letters_images_scaled = training_letters_images.values.astype('float32')/255
training_letters_labels = training_letters_labels.values.astype('int32')
testing_letters_images_scaled = testing_letters_images.values.astype('float32')/255
testing_letters_labels = testing_letters_labels.values.astype('int32')
print("Training images of letters after scaling")
print(training_letters_images_scaled.shape)
print(training_letters_images_scaled[0:5])
输出结果如下所示:
Training images of letters after scaling
(13440, 1024)
[[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
3.输出One-hot编码转换
由于本文是一个多分类问题,共包括28个阿拉伯字母,因此需要将将类别(0到27)进行One-hot转换,导入如下扩展包。
- from keras.utils import to_categorical
to_categorical 是将类别向量转换为二进制(只有0和1)的矩阵类型表示,其表现为将原有的类别向量转换为One-hot编码的形式。举一个简单的代码示例如下:
from keras.utils.np_utils import *
#类别向量定义
b = [0,1,2,3,4,5,6,7,8]
#调用to_categorical将b按照9个类别来进行转换
b = to_categorical(b, 9)
print(b)
"""
执行结果如下:
[[1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1.]]
"""
从以上代码运行可以看出,将原来类别向量中的每个值都转换为矩阵里的一个行向量,从左到右依次是0到8个类别。比如2表示为[0. 0. 1. 0. 0. 0. 0. 0. 0.],只有第3个为1,作为有效位,其余全部为0。one_hot encoding(独热编码)又称为一位有效位编码,上边代码例子中其实就是将类别向量转换为独热编码的类别矩阵。即如下转换:
0 1 2 3 4 5 6 7 8
0=> [1. 0. 0. 0. 0. 0. 0. 0. 0.]
1=> [0. 1. 0. 0. 0. 0. 0. 0. 0.]
2=> [0. 0. 1. 0. 0. 0. 0. 0. 0.]
3=> [0. 0. 0. 1. 0. 0. 0. 0. 0.]
4=> [0. 0. 0. 0. 1. 0. 0. 0. 0.]
5=> [0. 0. 0. 0. 0. 1. 0. 0. 0.]
6=> [0. 0. 0. 0. 0. 0. 1. 0. 0.]
7=> [0. 0. 0. 0. 0. 0. 0. 1. 0.]
8=> [0. 0. 0. 0. 0. 0. 0. 0. 1.]
该部分的预处理代码如下:
#----------------------------------------------------------------
# 第四步 输出One-hot编码转换
#----------------------------------------------------------------
import keras
from keras.utils import to_categorical
number_of_classes = 28
training_letters_labels_encoded = to_categorical(training_letters_labels-1,
num_classes=number_of_classes)
testing_letters_labels_encoded = to_categorical(testing_letters_labels-1,
num_classes=number_of_classes)
print(training_letters_labels)
print(training_letters_labels_encoded)
print(training_letters_images_scaled.shape)
# (13440, 1024)
输出结果如下图所示:
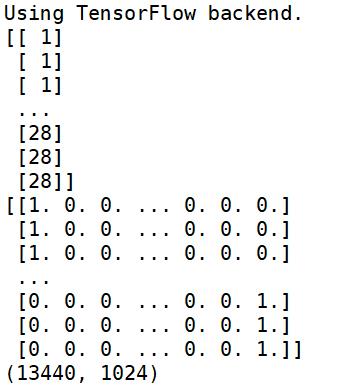
4.形状修改
深度学习中输入的形状非常重要,本文将输入图像修改为32x32x1,在Keras中接收一个四维数组作为输入,对应形状为:
- 图像样本总数
- 行
- 列
- 通道
#----------------------------------------------------------------
# 第五步 形状修改
#----------------------------------------------------------------
#输入形状 32x32x1
training_letters_images_scaled = training_letters_images_scaled.reshape([-1, 32, 32, 1])
testing_letters_images_scaled = testing_letters_images_scaled.reshape([-1, 32, 32, 1])
print(training_letters_images_scaled.shape,
training_letters_labels_encoded.shape,
testing_letters_images_scaled.shape,
testing_letters_labels_encoded.shape)
本文图像是32x32的灰度图,输出结果如下所示:
- (13440, 32, 32, 1) (13440, 28) (3360, 32, 32, 1) (3360, 28)
四.CNN模型搭建
1.卷积神经网络概念
卷积神经网络的英文是Convolutional Neural Network,简称CNN。它通常应用于图像识别和语音识等领域,并能给出更优秀的结果,也可以应用于视频分析、机器翻译、自然语言处理、药物发现等领域。著名的阿尔法狗让计算机看懂围棋就是基于卷积神经网络的。
神经网络是由很多神经层组成,每一层神经层中存在很多神经元,这些神经元是识别事物的关键,当输入是图片时,其实就是一堆数字。
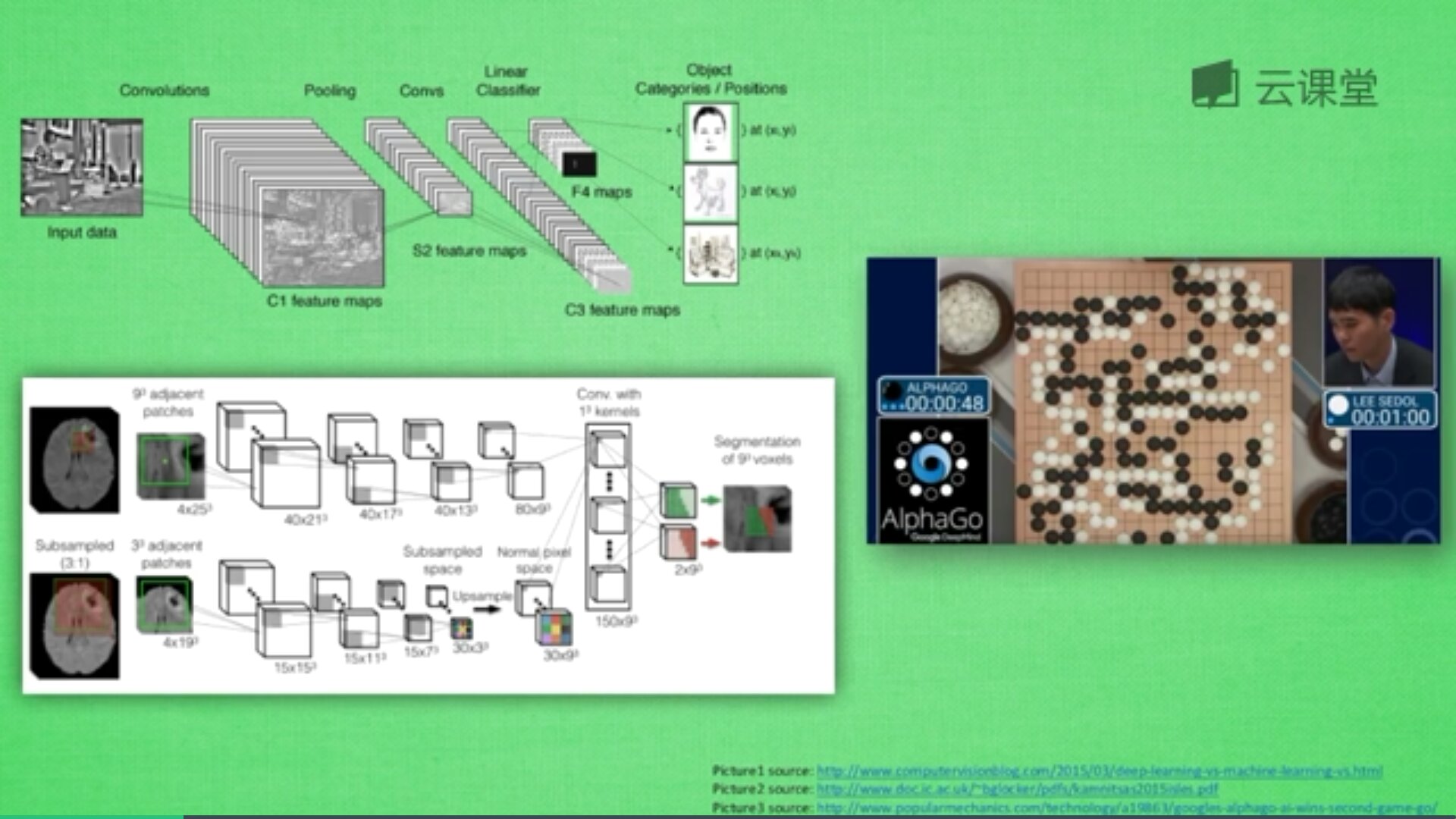
首先,卷积是什么意思呢?
卷积是指不在对每个像素做处理,而是对图片区域进行处理,这种做法加强了图片的连续性,看到的是一个图形而不是一个点,也加深了神经网络对图片的理解。
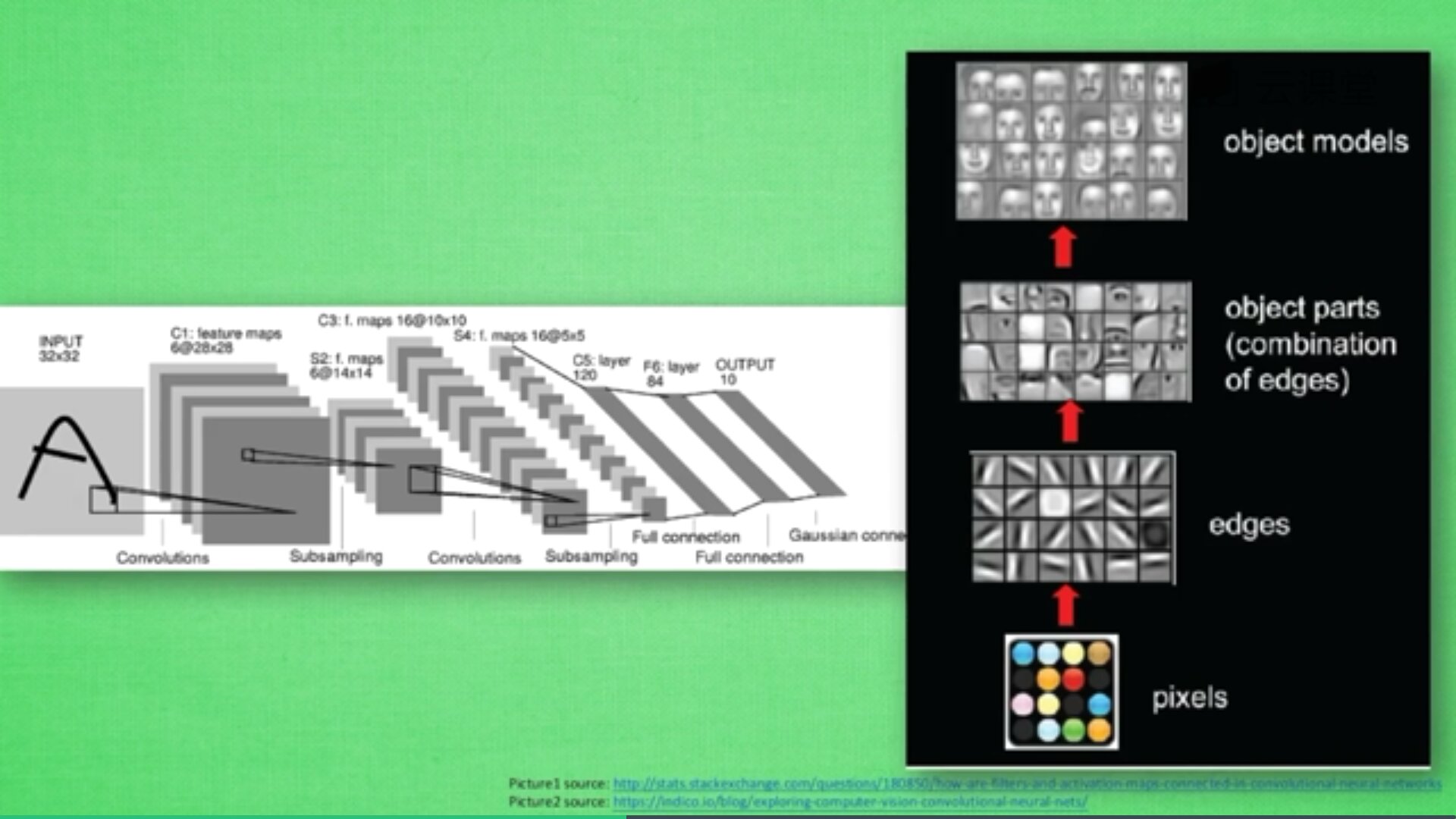
卷积神经网络批量过滤器,持续不断在图片上滚动搜集信息,每一次搜索都是一小块信息,整理这一小块信息之后得到边缘信息。比如第一次得出眼睛鼻子轮廓等,再经过一次过滤,将脸部信息总结出来,再将这些信息放到全神经网络中进行训练,反复扫描最终得出的分类结果。如下图所示,猫的一张照片需要转换为数学的形式,这里采用长宽高存储,其中黑白照片的高度为1,彩色照片的高度为3(RGB)。
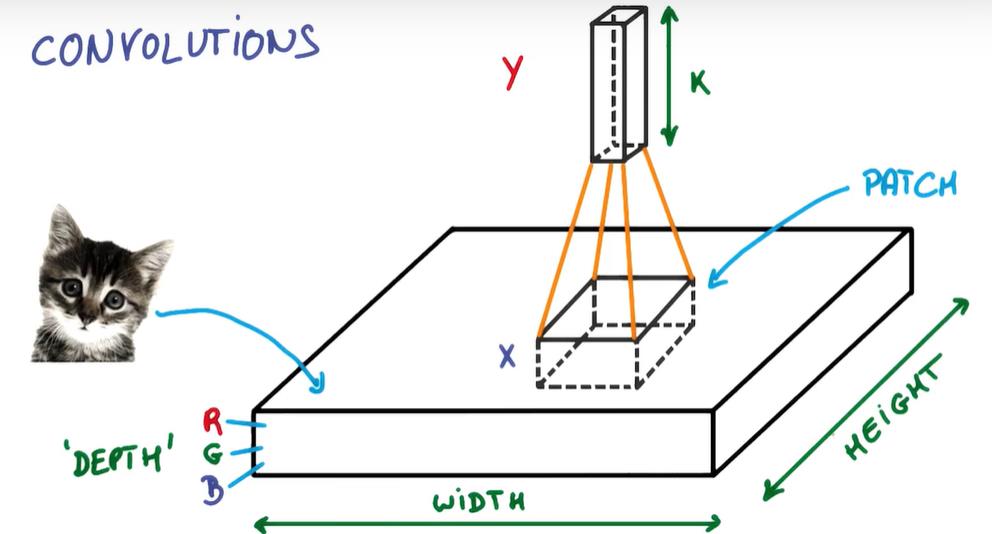
过滤器搜集这些信息,将得到一个更小的图片,再经过压缩增高信息嵌入到普通神经层上,最终得到分类的结果,这个过程即是卷积。Convnets是一种在空间上共享参数的神经网络,如下图所示,它将一张RGB图片进行压缩增高,得到一个很长的结果。
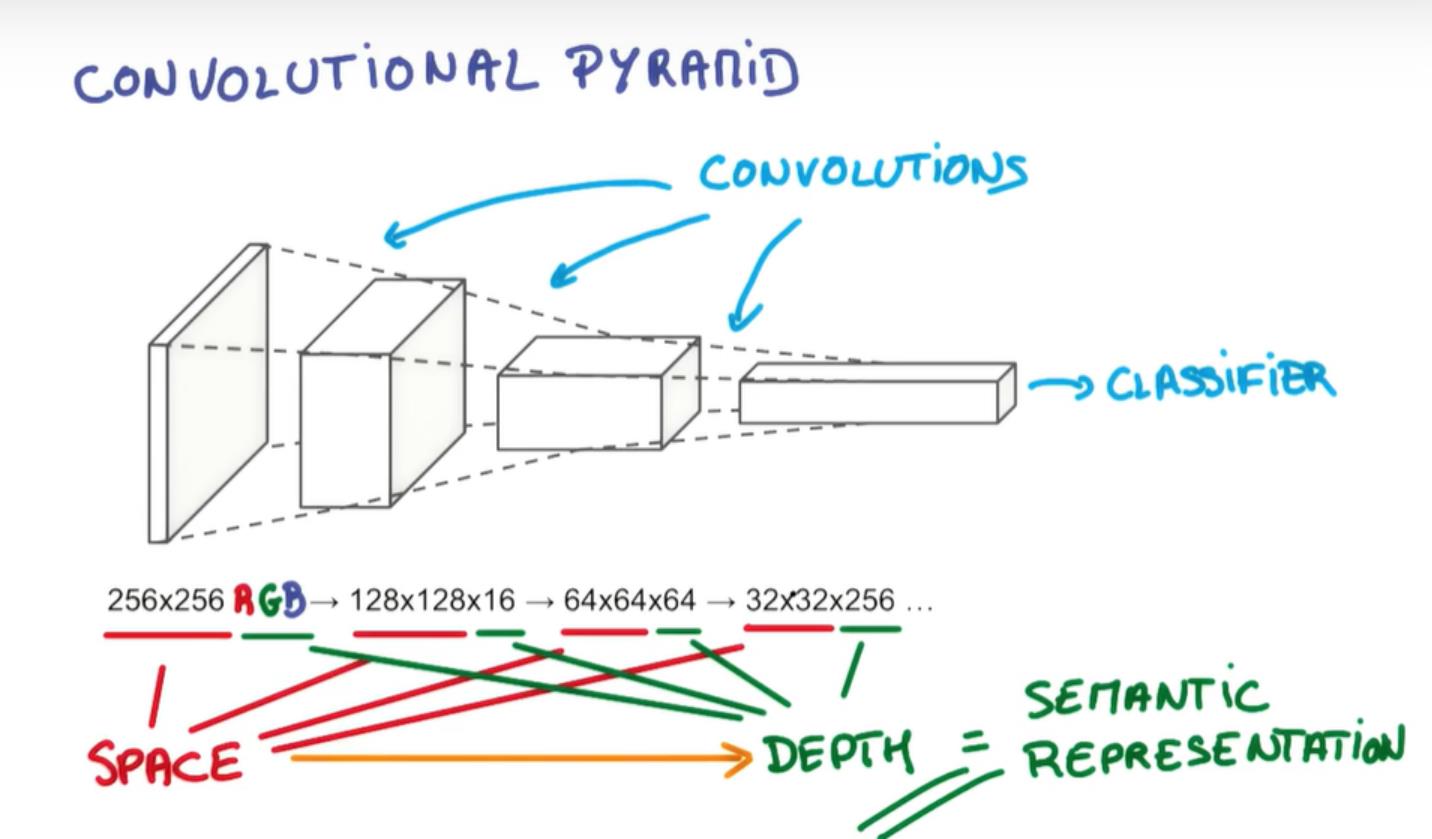
一个卷积网络是组成深度网络的基础,我们将使用数层卷积而不是数层的矩阵相乘。如上图所示,让它形成金字塔形状,金字塔底是一个非常大而浅的图片,仅包括红绿蓝,通过卷积操作逐渐挤压空间的维度,同时不断增加深度,使深度信息基本上可以表示出复杂的语义。同时,你可以在金字塔的顶端实现一个分类器,所有空间信息都被压缩成一个标识,只有把图片映射到不同类的信息保留,这就是CNN的总体思想。
上图的具体流程如下:
- 首先,这是有一张彩色图片,它包括RGB三原色分量,图像的长和宽为256*256,三个层面分别对应红(R)、绿(G)、蓝(B)三个图层,也可以看作像素点的厚度。
- 其次,CNN将图片的长度和宽度进行压缩,变成128x128x16的方块,压缩的方法是把图片的长度和宽度压小,从而增高厚度。
- 再次,继续压缩至64x64x64,直至32x32x256,此时它变成了一个很厚的长条方块,我们这里称之为分类器Classifier。该分类器能够将我们的分类结果进行预测,MNIST手写体数据集预测结果是10个数字,比如[0,0,0,1,0,0,0,0,0,0]表示预测的结果是数字3,Classifier在这里就相当于这10个序列。
- 最后,CNN通过不断压缩图片的长度和宽度,增加厚度,最终会变成了一个很厚的分类器,从而进行分类预测。
近几年神经网络飞速发展,其中一个很重要的原因就是CNN卷积神经网络的提出,这也是计算机视觉处理的飞跃提升。关于TensorFlow中的CNN,Google公司也出了一个非常精彩的视频教程,也推荐大家去学习。
2.模型设计
该部分采用Keras搭建四层CNN网络,是本文的核心过程,再次感谢刘兄代码,受益匪浅。
#----------------------------------------------------------------
# 第六步 CNN模型设计
#----------------------------------------------------------------
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, BatchNormalization, Dropout, Dense
#定义模型
def create_model(optimizer='adam', kernel_initializer='he_normal', activation='relu'):
#第一个卷积层
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=3, padding='same', input_shape=(32, 32, 1), kernel_initializer=kernel_initializer, activation=activation))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
#第二个卷积层
model.add(Conv2D(filters=32, kernel_size=3, padding='same', kernel_initializer=kernel_initializer, activation=activation))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
#第三个卷积层
model.add(Conv2D(filters=64, kernel_size=3, padding='same', kernel_initializer=kernel_initializer, activation=activation))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
#第四个卷积层
model.add(Conv2D(filters=128, kernel_size=3, padding='same', kernel_initializer=kernel_initializer, activation=activation))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.2))
model.add(GlobalAveragePooling2D())
#全连接层输出28类结果
model.add(Dense(28, activation='softmax'))
#损失函数定义
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=optimizer)
return model
#创建模型
model = create_model(optimizer='Adam', kernel_initializer='uniform', activation='relu')
model.summary()
模型包括四个卷积神经网络,再通过全连接层实现分类。每个卷积层内容如下:
- 输入层包括16个特征图,大小为3×3和一个relu激活函数;
- 接着是批量标准化层,主要用于解决特征分布在训练和测试数据中的变化,BN层添加在激活函数前,对输入激活函数的输入进行归一化,解决数据发送偏移和增大的影响;
- 池化层主要对输入进行下采样,从而减小参数的学习次数和训练时间;
- 使用dropout正则化,设置参数为0.2,即被配置为随机排除层中20%的神经元以减少过度拟合。
总共是16、32、64、128个元素的隐藏层,最后通过输出层(类别28),并使用softmax激活函数,利用交叉熵作为损失函数。整个模型的结构输出如下所示:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 16) 160
_________________________________________________________________
batch_normalization_1 (Batch (None, 32, 32, 16) 64
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 16) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) 以上是关于[Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像的主要内容,如果未能解决你的问题,请参考以下文章
[Python人工智能] 三十九.VS Code配置Python编程和Keras环境及手写数字识别(基础篇)
[Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析(上)
[Python人工智能] 三十五.基于Transformer的商品评论情感分析 机器学习和深度学习的Baseline模型实现
[Python人工智能] 三十二.Bert模型 Keras-bert基本用法及预训练模型
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型