深度学习和目标检测系列教程 11-300:小麦数据集训练Faster-RCNN模型
Posted 刘润森!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习和目标检测系列教程 11-300:小麦数据集训练Faster-RCNN模型相关的知识,希望对你有一定的参考价值。
@Author:Runsen
上次训练的Faster-RCNN的数据格式是xml和jpg图片提供,在很多Object-Detection中,数据有的是csv格式,

- 数据集来源:https://www.kaggle.com/c/global-wheat-detection
width和heigth是图片的长和宽,bbox是框的位置。
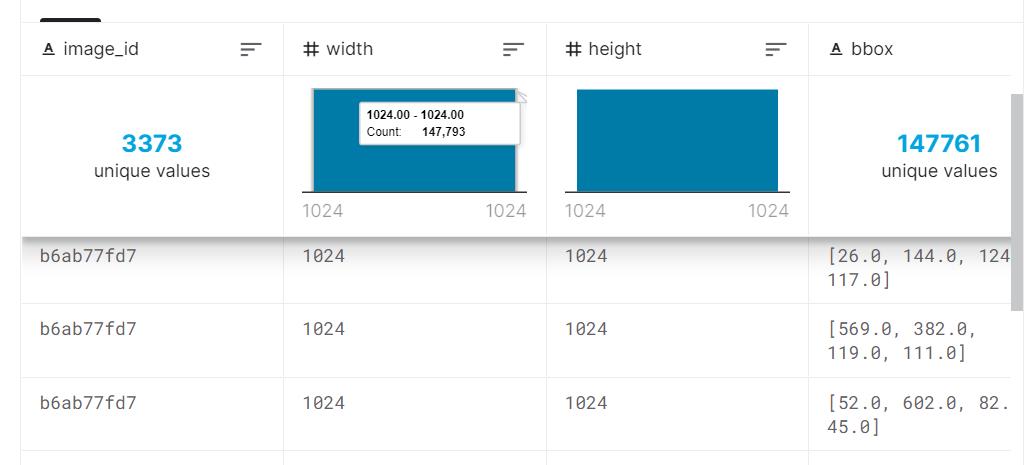
我们需要在小麦植物的室外图像中检测小麦头,分类的类别只有一个。
我们来看一个牛逼人的做法:https://www.kaggle.com/pestipeti/pytorch-starter-fasterrcnn-train
这次使用torch训练Faster-RCNN和之前的没有什么不一样。
import pandas as pd
import numpy as np
import cv2
import os
import re
from PIL import Image
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from matplotlib import pyplot as plt
DIR_INPUT = '/kaggle/input/global-wheat-detection'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
# 读取'x', 'y', 'w', 'h'
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'] = train_df['x'].astype(np.float)
train_df['y'] = train_df['y'].astype(np.float)
train_df['w'] = train_df['w'].astype(np.float)
train_df['h'] = train_df['h'].astype(np.float)
image_ids = train_df['image_id'].unique()
valid_ids = image_ids[-665:]
train_ids = image_ids[:-665]
# Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
# load a model; pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = 2 # 1 class (wheat) + background
# get number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
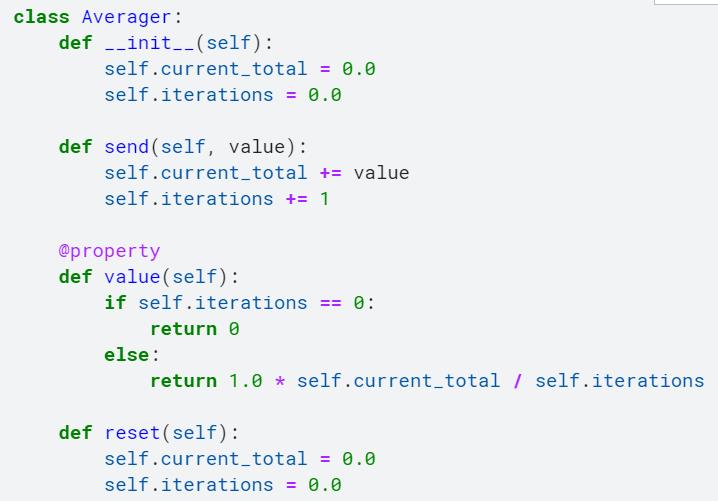
不同的是定义了Averager类,这一个类来保存对应的loss。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
images, targets, image_ids = next(iter(train_data_loader))
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
boxes = targets[2]['boxes'].cpu().numpy().astype(np.int32)
sample = images[2].permute(1,2,0).cpu().numpy()
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
for box in boxes:
cv2.rectangle(sample,
(box[0], box[1]),
(box[2], box[3]),
(220, 0, 0), 3)
ax.set_axis_off()
ax.imshow(sample)

model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
# lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
lr_scheduler = None
num_epochs = 2
loss_hist = Averager()
itr = 1
for epoch in range(num_epochs):
loss_hist.reset()
for images, targets, image_ids in train_data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
loss_hist.send(loss_value)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if itr % 50 == 0:
print(f"Iteration #{itr} loss: {loss_value}")
itr += 1
# update the learning rate
if lr_scheduler is not None:
lr_scheduler.step()
print(f"Epoch #{epoch} loss: {loss_hist.value}")
images, targets, image_ids = next(iter(valid_data_loader))
images = list(img.to(device) for img in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
boxes = targets[1]['boxes'].cpu().numpy().astype(np.int32)
sample = images[1].permute(1,2,0).cpu().numpy()
model.eval()
cpu_device = torch.device("cpu")
outputs = model(images)
outputs = [{k: v.to(cpu_device) for k, v in t.items()} for t in outputs]
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
for box in boxes:
cv2.rectangle(sample,
(box[0], box[1]),
(box[2], box[3]),
(220, 0, 0), 3)
ax.set_axis_off()
ax.imshow(sample)
torch.save(model.state_dict(), 'fasterrcnn_resnet50_fpn.pth')
这个代码真的值得学习和模仿:
https://www.kaggle.com/pestipeti/pytorch-starter-fasterrcnn-train
以上是关于深度学习和目标检测系列教程 11-300:小麦数据集训练Faster-RCNN模型的主要内容,如果未能解决你的问题,请参考以下文章
深度学习和目标检测系列教程 3-300:了解常见的目标检测的开源数据集
深度学习和目标检测系列教程 9-300:TorchVision和Albumentation性能对比,如何使用Albumentation对图片数据做数据增强
深度学习和目标检测系列教程 17-300: 3 个类别面罩检测类别数据集训练yolov5s模型
深度学习和目标检测系列教程 17-300: 3 个类别面罩检测类别数据集训练yolov5s模型