对豆瓣电影进行可视化分析
Posted 苏苏相公
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对豆瓣电影进行可视化分析相关的知识,希望对你有一定的参考价值。
一、数据描述
1.数据解释
电影数据共140502部,2019年之前的电影有139129,当前未上映的有1373部,包含21个字段,部分字段数据为空,字段说明如下:
MOVIE_ID: 电影ID,对应豆瓣的DOUBAN_ID
NAME: 电影名称
ALIAS: 别名
ACTORS: 主演
COVER: 封面图片地址
DIRECTORS: 导演
GENRES: 类型
OFFICIAL_SITE: 地址
REGIONS: 制片国家/地区
LANGUAGES: 语言
RELEASE_DATE: 上映日期
MINS: 片长
IMDB_ID: IMDbID
DOUBAN_SCORE: 豆瓣评分
DOUBAN_VOTES: 豆瓣投票数
TAGS: 标签
STORYLINE: 电影描述
SLUG: 加密的url,可忽略
YEAR: 年份
ACTOR_IDS: 演员与PERSON_ID的对应关系,多个演员采用“|”符号分割,格式“演员A:ID|演员B:ID”;
DIRECTOR_IDS: 导演与PERSON_ID的对应关系,多个导演采用“|”符号分割,格式“导演A:ID|导演B:ID”;
2.导入数据
import pandas as pd df=pd.read_csv(r\'C:\\Users\\苏苏\\Desktop\\seaborn-data\\movies.csv\',encoding=\'utf-8\')
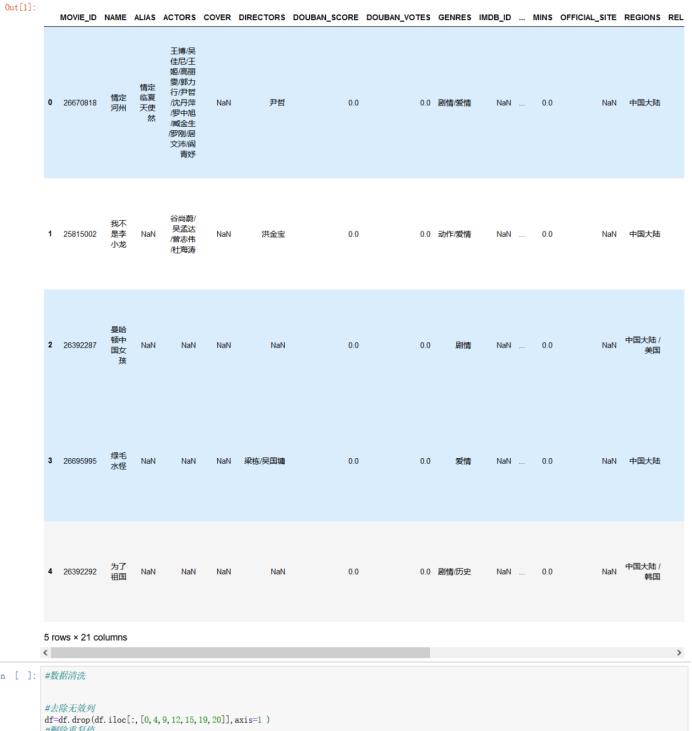
3.查看数据集信息
二、问题提出
1.主要比较世界电影和中国,以及中国大陆和中国港台电影之间的差别,分析各参数之间是否存在关联性及对评分产生的影响
2.评分与其他属性项的关系是什么,正负相关还是正态分布
三、数据清洗和预处理
查看缺失值
df.isnull().sum()
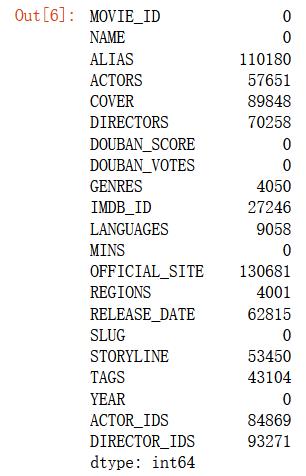
可以看出数据缺失的挺多,可进行删除处理,为了节省后续操作的效率,删去了不必要的字段。并且删去了没有评分的电影(评分为0)
#数据清洗 #去除无效列 df=df.drop(df.iloc[:,[0,4,9,12,15,19,20]],axis=1 ) #删除重复值 df.drop_duplicates(inplace=True) #删除缺失值 指定列有缺失值的行.dropna(subset = [\'gender\'],how =\'any\') df.dropna(inplace = True) #删去没有评分的电影(评分为0) df=df[~df[\'DOUBAN_SCORE\'].isin([0])] df.head()
查看数据类型
df.info()
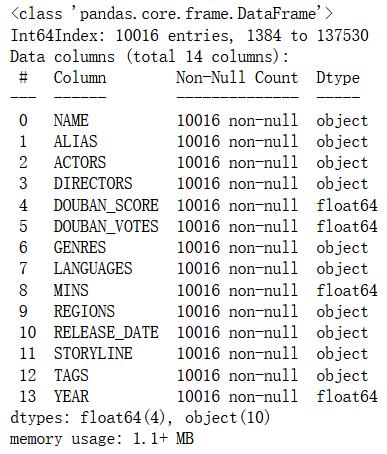
检查数据类型无误
四、各变量相关性数据分析与可视化
本数据使用探索性分析工具dtale进行探究
dtale.show(df,ignore_duplicate=True)
1.查看数据类型
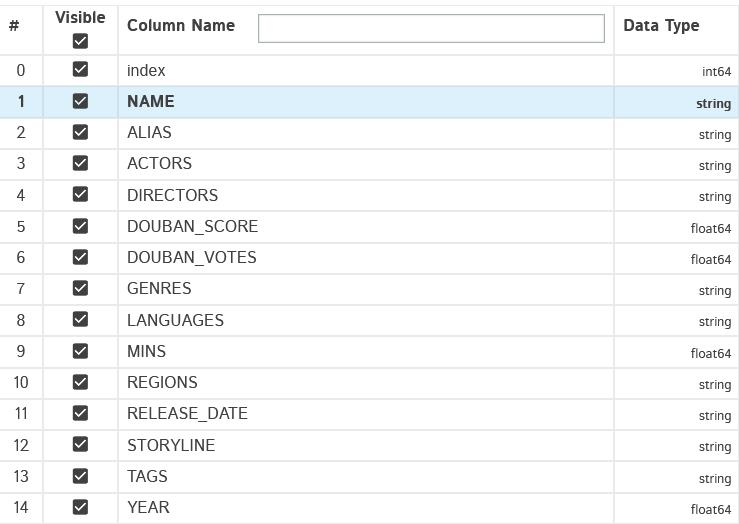
2.豆瓣评分分布情况描述及直方图
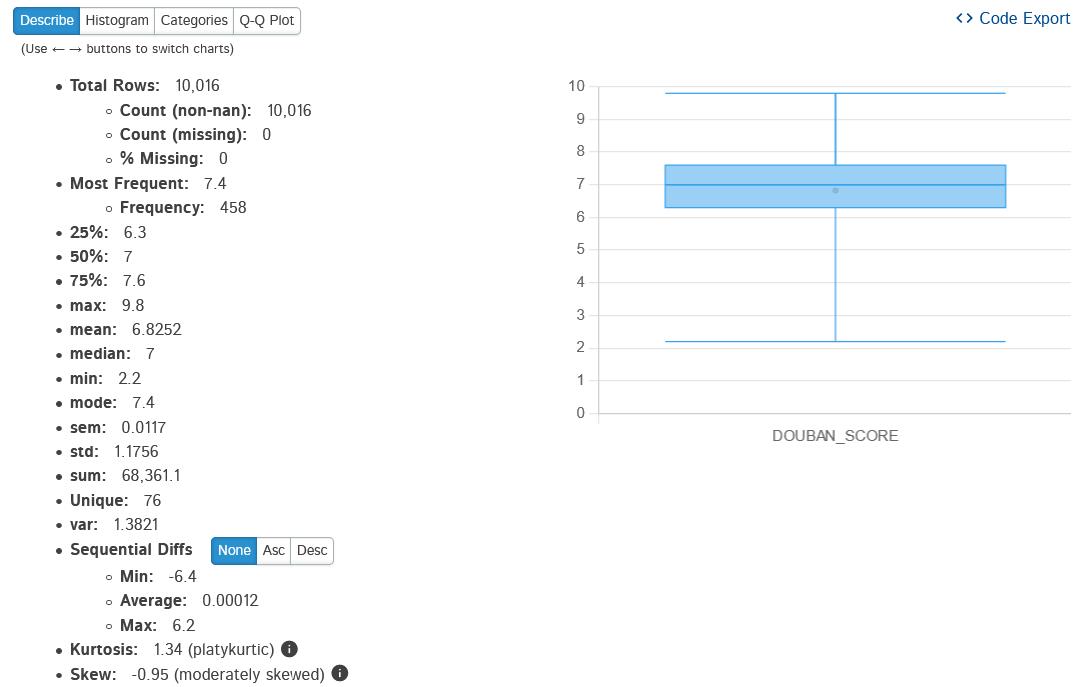
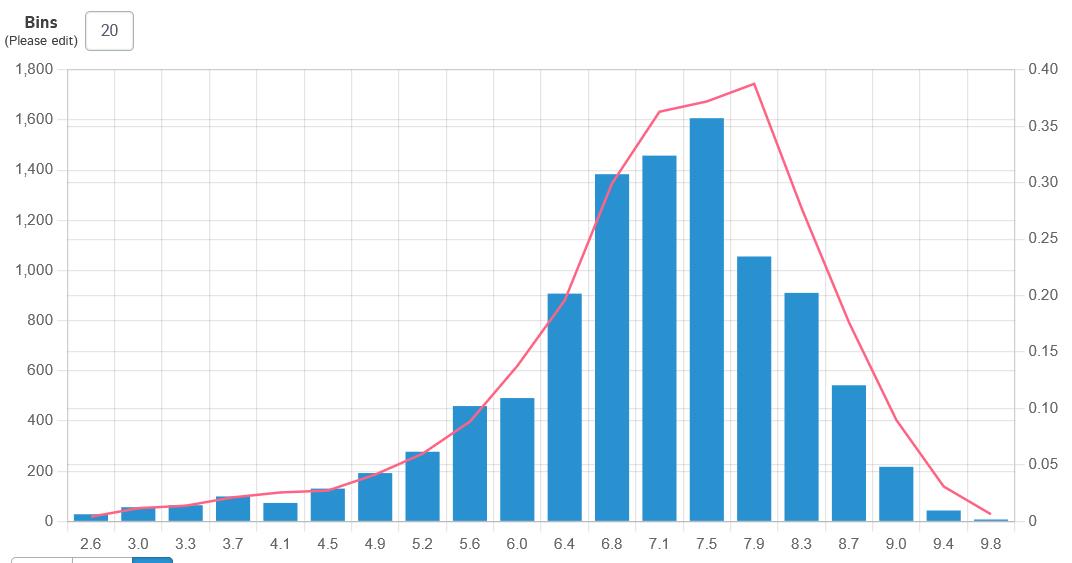
可以看出,25%,第1四分位数,50%,第2四分位数,75%,第3四分位数,百分位数各自评分,最高评分9.8,最低2.2,平均7分,评分主要积聚在6到8分之间
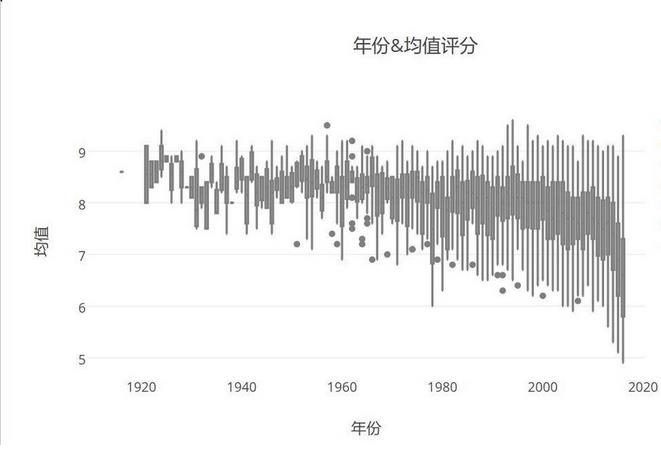
3.能从年份&评分中看出点什么?
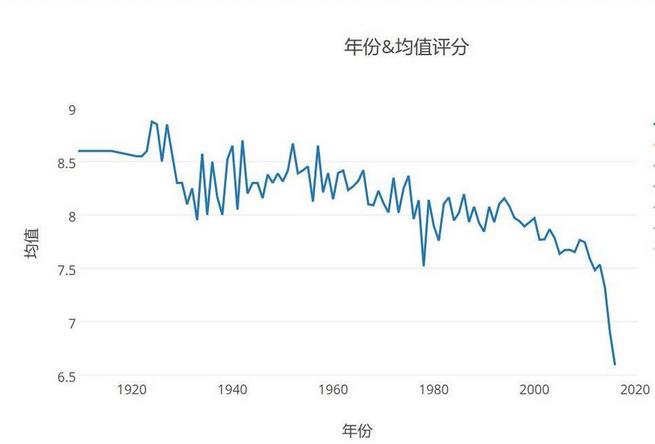
豆瓣世界电影的评分均值趋势:
世界电影的评分Box箱线图趋势:
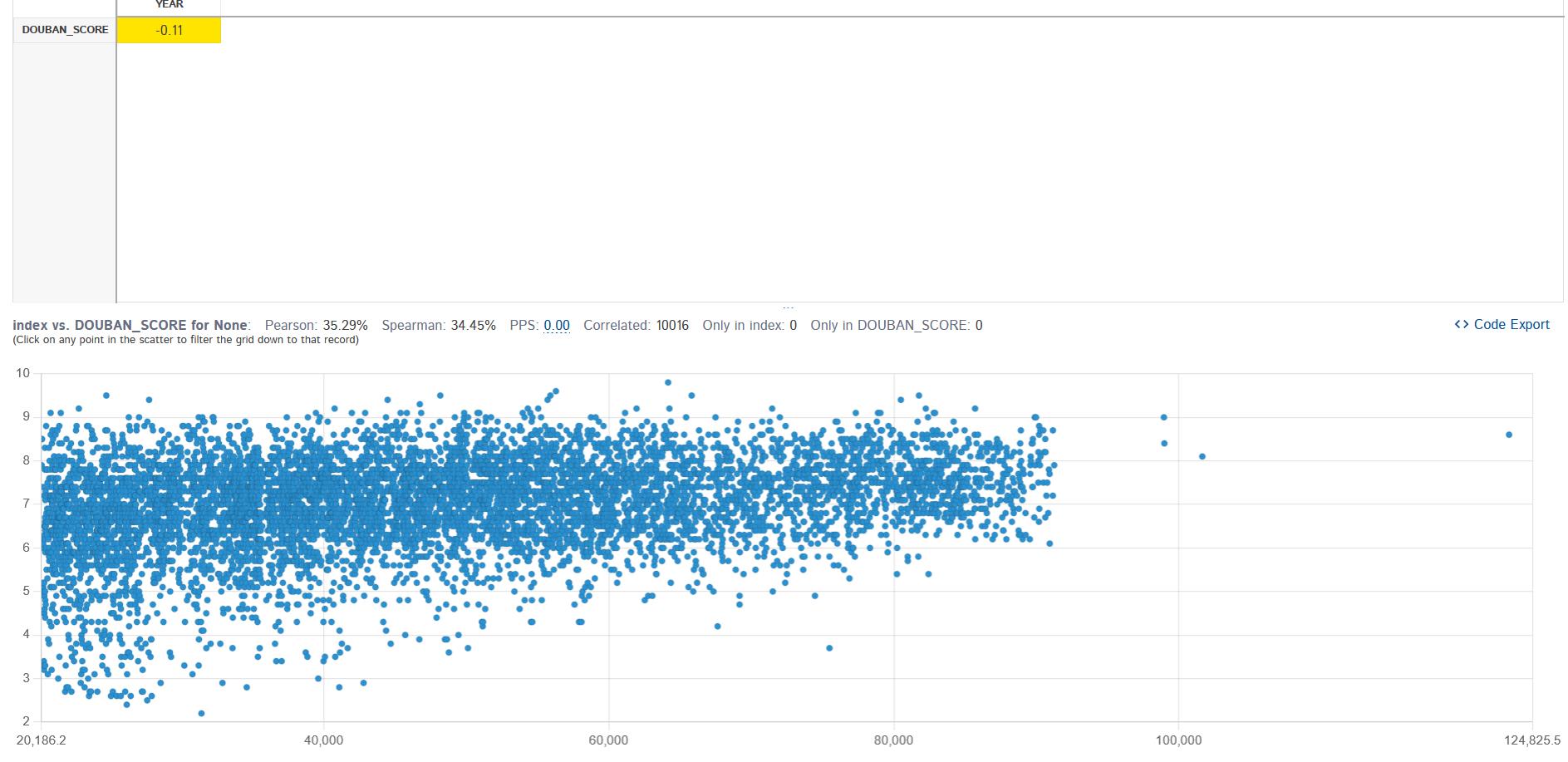
皮尔逊关联性(Pearson correlation)的可视化:评分与年份
4.利用词云显示在某个阶段时间内,哪部电影评分高低情况
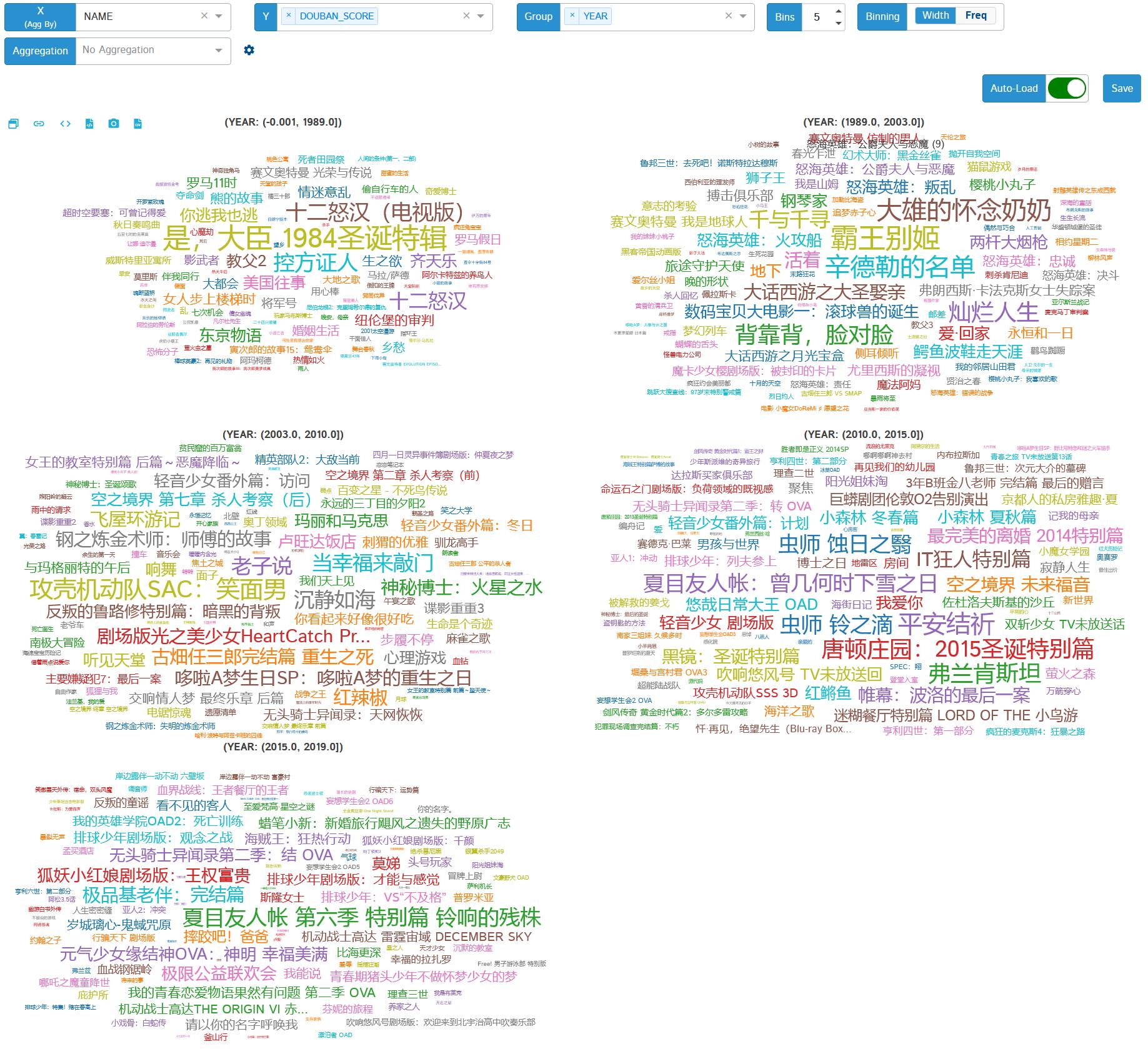
可以看出1989年以前,“是,大臣 1984圣诞特辑“评分较高,89年到03年”霸王别姬“等受欢迎,清晰明了。
5.豆瓣电影评分与时长关系
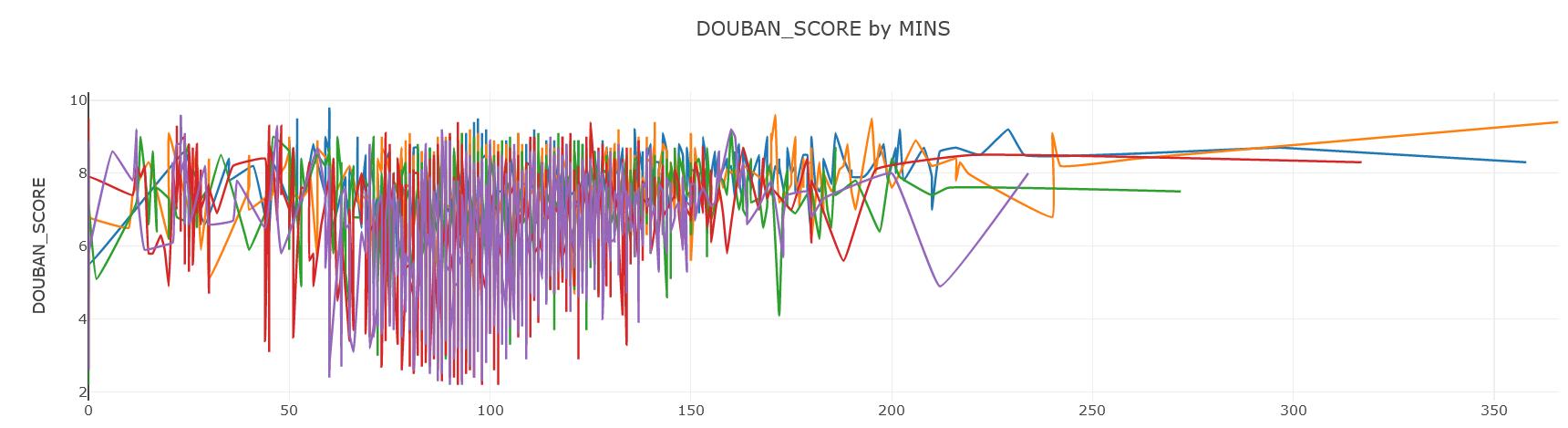
发现大部分电影时长集中在100分钟左右,符合人们的观影舒适感,不过此时长的电影残次不齐,好坏各分千秋,而且发现,超过150分钟的电影,不仅没有让观众因为电影太长而不喜欢,相反,正因为电影时长足够,能够充分铺垫,使得即使两三个小时的电影评分居高不下,当然也不排除个别又烂又长让人看了想睡觉毫无意义的电影。
6.电影类型与评分关系

剧情/喜剧、剧情/爱情、同性、喜剧/爱情等类型电影居多,但评分却普遍不高,可能是为了迎合大众但又拍出来的效果不佳,相反,西部,歌舞,音乐,儿童和动画类型的电影评分很高,深受喜爱
五、主要结论
以上是关于对豆瓣电影进行可视化分析的主要内容,如果未能解决你的问题,请参考以下文章