豆瓣电影TOP250爬虫及可视化分析笔记
Posted sun0225SUN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了豆瓣电影TOP250爬虫及可视化分析笔记相关的知识,希望对你有一定的参考价值。
人类社会已经进入大数据时代,大数据深刻改变着我们的工作和生活。随着互联网、移动互联网、社交网络等的迅猛发展,各种数量庞大、种类繁多、随时随地产生和更新的大数据,蕴含着前所未有的社会价值和商业价值!!!
文章目录
一、前言
本文是一篇爬虫实战学习笔记,记录近些时日对网络爬虫的认识和学习心得,主要使用了 requests、 re 、Beautifulsoup 和pandas库,初学爬虫,代码写的有点烂,望包涵!
本文同步发表在我的个人博客上,欢迎访问 :https://sunguoqi.com/2021/11/07/douban_top250/
二、实例引入
假设由于工作或者项目要求,我们需要获取豆瓣电影 Top250 上的影片数据,进行可视化分析。
数据包括 影片名 上映年份 评分 导演 主演 电影类别 上映地区 影片名言 等
原始的数据存放在豆瓣的网页上,像这样。
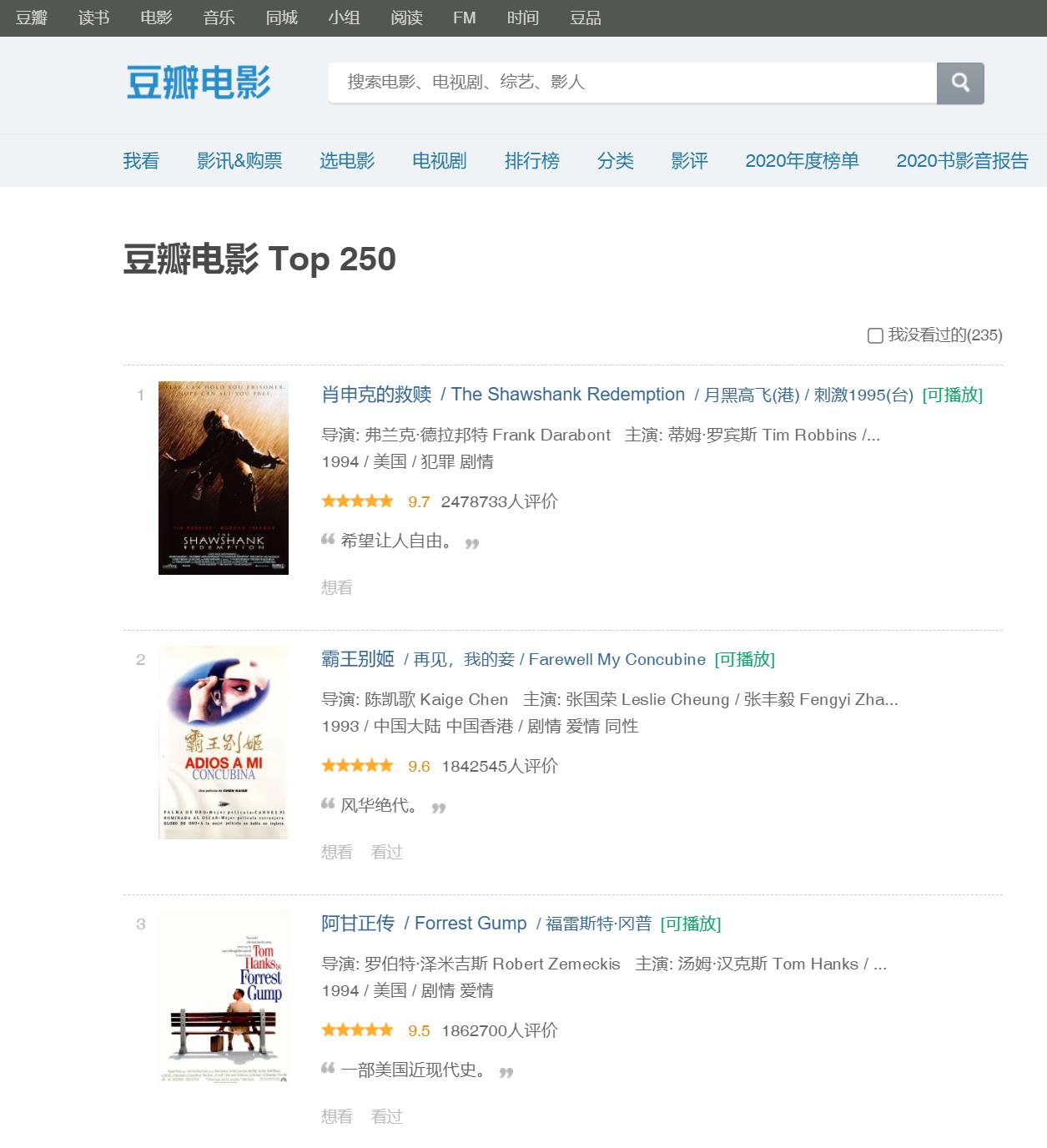
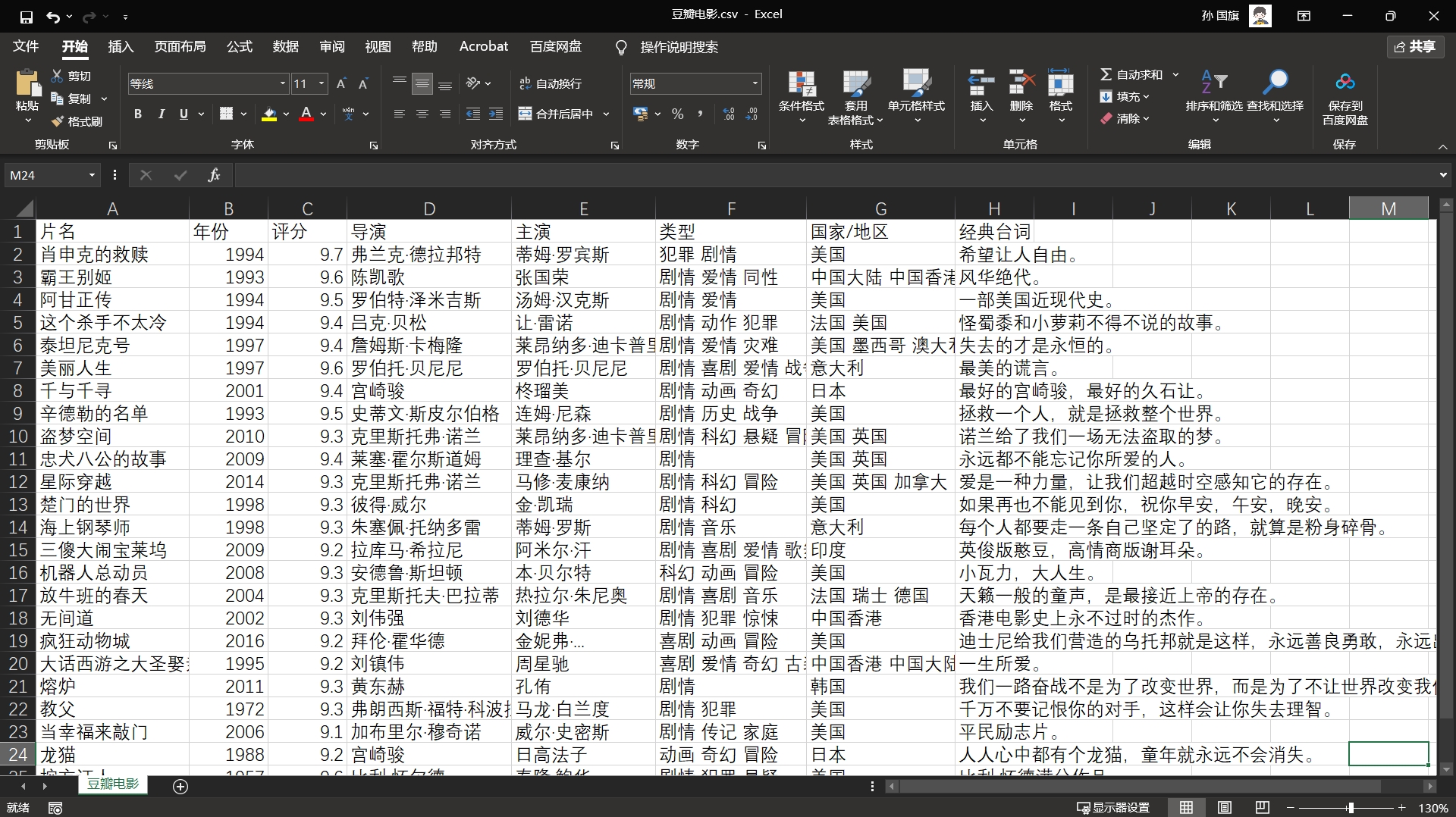


试想一下,我们该怎么做?
天大寒,砚冰坚,手指不可屈伸,弗之怠,录毕,走送之,不敢稍逾约?
我想人工摘录是一个极不明智的选择。在信息时代,我们有计算机,我们有python,我们应该想方设法让计算机去做这些事情。

三、爬虫
爬虫,其实就是代替人力去完成信息抓取工作的一门技术,他能按照一定的规则,从互联网上抓取任何我们想要的信息。
四、爬取思路
如何写爬虫?我们写爬虫的思路是什么?
前文提到,爬虫是代替人去完成信息抓取工作的,那么接下我们需要思考的问题便是,人是如何完成信息抓取工作的。
首先,我们打开豆瓣电影 TOP250 排行榜,分析我们需要的数据存放在哪里,然后复制粘贴,把我们的数据存放在excel表格里,依次重复如此枯燥乏味的工作对吧。
是的,其实爬虫要做的工作也是如此,写爬虫的大致思路如下。
确定URL——>发起请求获得服务器响应数据——>解析数据——> 数据存储
五、爬虫实战
1、单页爬取
先把单页爬取的代码放在这里,稍后我会做详细解释。
"""
-*- coding: utf-8 -*-
@Time : 2021/11/6 下午 4:59
@Author : SunGuoqi
@Website : https://sunguoqi.com
@Github: https://github.com/sun0225SUN
"""
# 导入一些模块
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
# 首先确定URL
url = 'https://movie.douban.com/top250'
# UA伪装
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
# 发起请求
response = requests.get(url, headers=headers)
# 获得响应文件文本
# print(response.text)
html = response.text
# 创建BeautifulSoup对象,方便解析
soup = BeautifulSoup(html, 'lxml')
# 找出所有的li标签
all_li = soup.find('ol', {'class': 'grid_view'}).find_all('li')
# 创建一个空列表,存放我们的数据。
datas = []
for item in all_li:
# 提取影片名称(只提取了中文名称)
name = item.find('span', {'class': 'title'}).text
# 提取影片评分
score = item.find('span', {'property': 'v:average'}).text
# 提取影片经典语录
quote = item.find('span', {'class': "inq"}).text
# 下面提取影片信息部分
info = item.find_all('p', {'class': ''})
# print(info.text)
# 返回的是一个列表,列表里是一个元组
# print(info[0].text)
info_contents = info[0].text
# 分割影片信息,提取影片 导演 || 主演 || 上映年份 || 国家/地区 || 类型
result = re.findall(
'^.*?\\u5bfc\\u6f14:\\s(.*?)\\s.*?\\u4e3b\\u6f14:\\s(.*?)\\s.*?(\\d{4})\\s.*?([\\u4e00-\\u9fa5].*)\\xa0.*?\\u002f.*?([\\u4e00-\\u9fa5].*?)\\s\\s.*$',
info_contents, re.S)
# 把数据按找字典的格式存放到列表里
datas.append({
'片名': name,
'年份': result[0][2],
'评分': score,
'导演': result[0][0],
'主演': result[0][1],
'类型': result[0][4],
'国家/地区': result[0][3],
'经典台词': quote
})
print("爬取完成!!!")
# 写入到文件
df = pd.DataFrame(datas)
df.to_csv("豆瓣电影.csv", index=False, header=True, encoding='utf_8_sig')
print("已写入豆瓣.csv文件")
1.1、导入模块
首先我们需要导入四个模块,没有下面四个库的同学需要PIP安装下。
import requests
import re
from bs4 import BeautifulSoup
import pandas as pd
1.2、确定URL
我们请求的URL是明确的,就是https://movie.douban.com/top250?start=0&filter=,其后面的参数是和多页爬取和过滤相关的,这个我们后面会用到。
url = 'https://movie.douban.com/top250'
1.3、发起请求
我们打开浏览器,输入网址,按下enter键后便可获得精美的页面,但其实在这期间,计算机和浏览器为我们做了很多事情。
不妨我们试一下,打开我们的浏览器,输入网址https://movie.douban.com/top250,然后按下我们电脑上的F12键,打开开发者工具,选择Network选项卡,刷新一下页面,你会看到很多数据包。这便是我们按下enter键后获得的数据本身,浏览器根据相应的规则对这些数据包进行解析和渲染,便生成了我们见到的网页。

我们是通过浏览器去获取和解析数据的,那么爬虫如何像浏览器一样去请求数据呢?
站在巨人的肩膀上,Python大牛们已经解决了这个问题,并把它封装成了一个库,这个库便是requests库,我们只需要调用库里面封装好的函数就可以模拟浏览器请求数据了。
似乎还需要讲一个东西,就是请求头 请求体和响应头 响应体的问题。
打开我们的开发者工具,点击一条数据,选择headers选项卡,我们便可以看到此次请求的请求头,其中包括我们请求的URL 请求方法 UA标识 请求参数等等
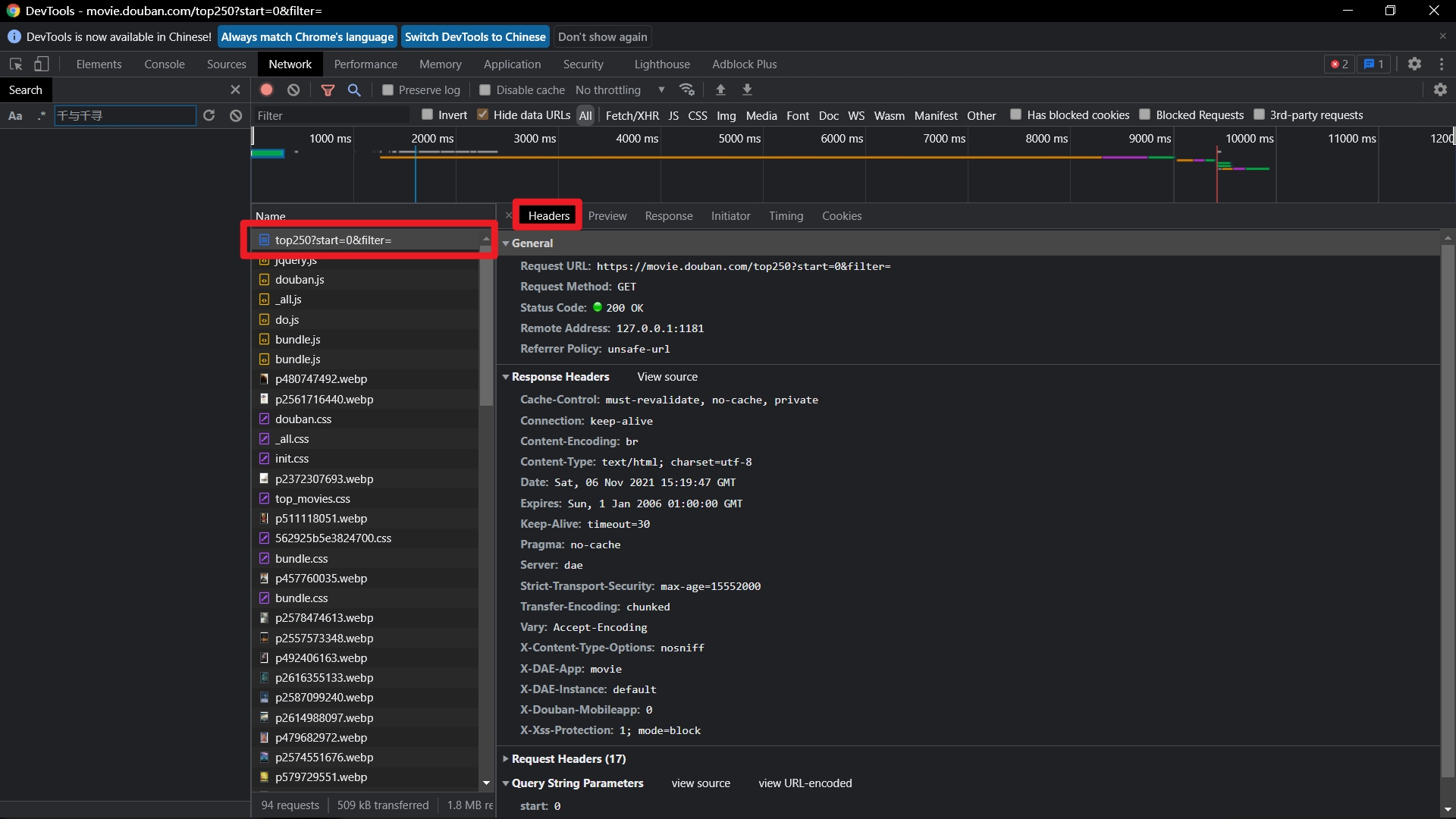
包裹是有身份的,就像我们收到的快递一样,数据包也是如此,我们需要知道这个数据是谁发送的,要干嘛,所以我们需要请求头 请求体这样一个东西。
一些网站会设置反爬虫机制,如果服务器发现请求是python发送的,便不会正常响应,所以我们需要伪装一下身份。
解决方法就是利用请求头进行UA伪装
# 首先确定URL
url = 'https://movie.douban.com/top250'
# UA伪装
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
# 发起请求
response = requests.get(url, headers=headers)
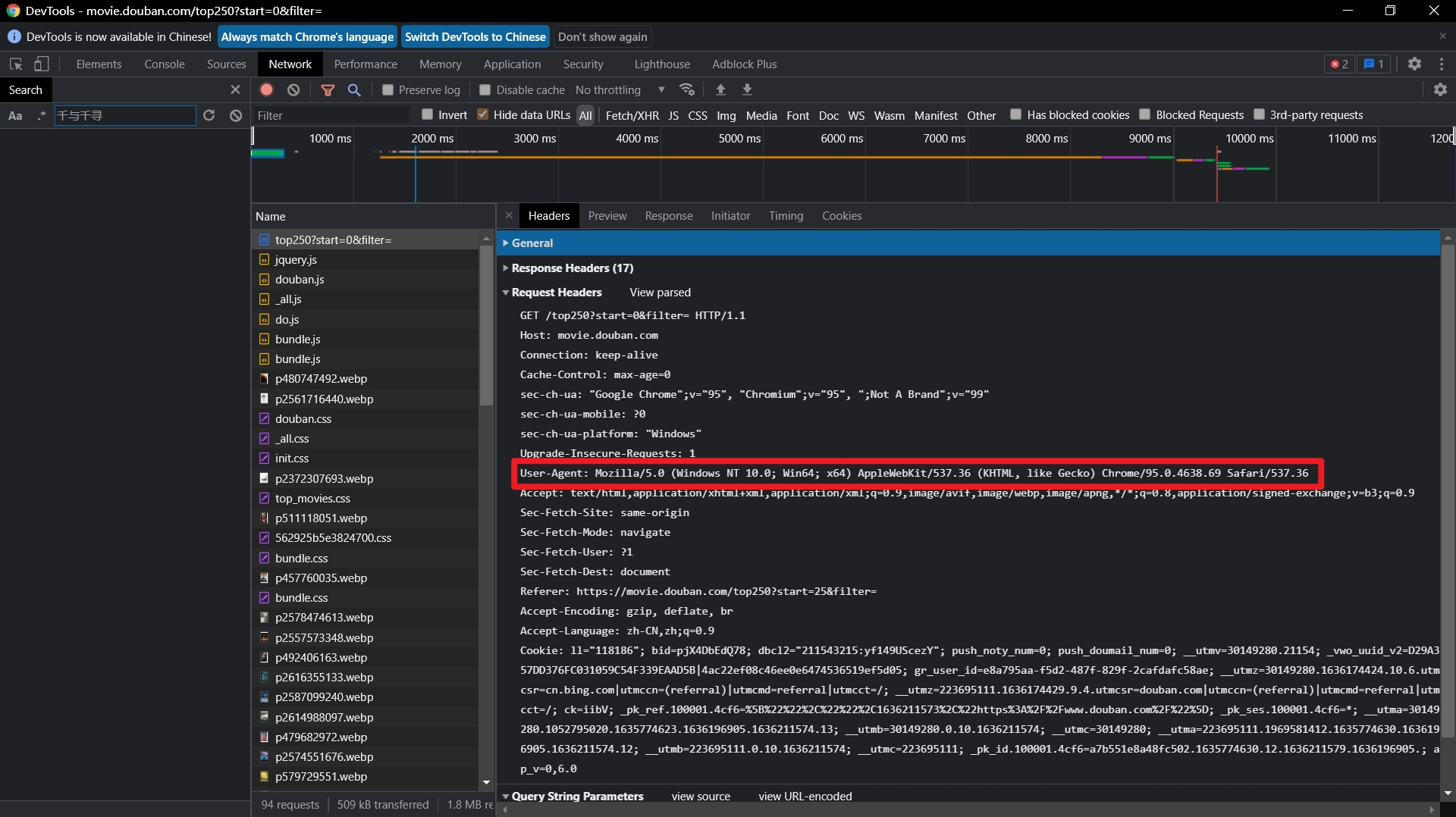
如何查看自己电脑的UA表示呢?打开开发者工具,找到我们headers选项卡,展开第三条数据即可看到我们电脑的UA
1.4、获得响应
如果程序正常运行,便会发送URL对应的资源文件,我们可以打印一下他的响应内容。
print(response.text)
屏幕应该会打印一大堆HTML文本,我们的数据就存放在里面。
1.5、数据解析
我们成功获取了HTML文件,我们需要的数据就存放在里面,但是如何过滤掉我们不需要的东西呢?
当米开朗琪罗被问及如何完成《大卫》这样匠心的雕刻作品时,他有一段著名的回答: 很简单,你需要用锤子把石头上不像大卫的地方敲掉就行了。
再次站在前人的肩膀上,BeautifulSoup库闪亮出场。
在使用BeautifulSoup库之前,我们应该很清楚的知道我们需要的数据存放在什么位置。

很显然,我们需要的数据存放在一个ol有序列表里,每条数据的便是一个列表项li,每个li标签又长什么样子呢?
因为豆瓣后台源代码有点乱,我们把它复制到vscode里格式化一下再看。
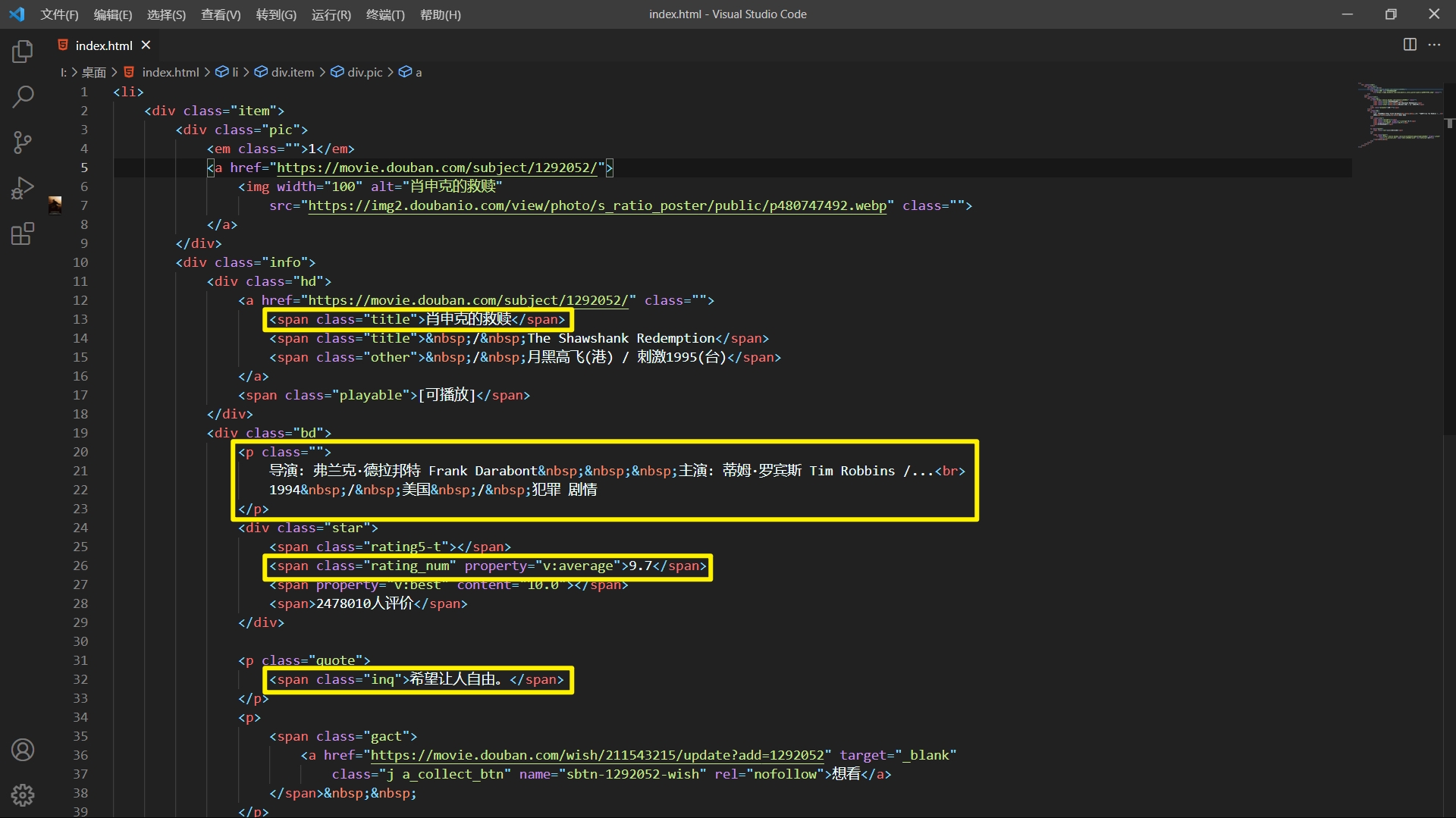
我们需要的数据存放的位置就更加明显了。好了,现在我们可以喝一碗美味的汤了(BeautifulSoup)
先将我们获取的HTML文本封装成BeautifulSoup对象,对象里包含了很多属性和方法,方便我们查找和获取我们需要的数据。
# print(response.text)
html = response.text
# 创建BeautifulSoup对象,方便解析
soup = BeautifulSoup(html, 'lxml')
这里我们首先获取所有的li标签,然后遍历all_li 获得每个li里的数据,在进行解析就可以了。
# 找出所有的li标签
all_li = soup.find('ol', {'class': 'grid_view'}).find_all('li')
我们创建一个空列表,将以后获得得每条数据,都存放在里面。
datas = []
我们通过上面的分析发现,影片名称存放在下面这一小块。
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
其对应的解析便是name = item.find('span', {'class': 'title'}).text
影片得分,存放在下面这一小块。
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2478010人评价</span>
</div>
其对应的解析便是name = item.find('span', {'class': 'title'}).text
影片语录存放在下面这一小块。
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
其对应的解析便是quote = item.find('span', {'class': "inq"}).text
其他内容都在这里面,
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
有些同学可能会发现,如果我们依旧按照上面的方式去解析,我们只能获得p标签里面的内容,没法把导演哇,主演哇,等等分离出来,emmm,怎么办呢?
魔法终究可以被魔法打败,我们有最强的字符串处理工具,就是正则表达式。在使用之前,我们应该先引用先导入此模块。
首先我们获取的p标签里的内容,它长下面这个样子。
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
其对应的解析便是result = re.findall('^.*?\\u5bfc\\u6f14:\\s(.*?)\\s.*?\\u4e3b\\u6f14:\\s(.*?)\\s.*?(\\d{4})\\s.*?([\\u4e00-\\u9fa5].*)\\xa0.*?\\u002f.*?([\\u4e00-\\u9fa5].*?)\\s\\s.*$',info_contents, re.S)
这里关于正则表达式就不多说了,有兴趣的同学可以研究研究。
计算机科学领域有一个笑话,如果你有一个问题打算用正则表达式来解决,那么就是两个问题了。
于是,程序就变成下面这样了。
for item in all_li:
# 提取影片名称(只提取了中文名称)
name = item.find('span', {'class': 'title'}).text
# 提取影片评分
score = item.find('span', {'property': 'v:average'}).text
# 提取影片经典语录
quote = item.find('span', {'class': "inq"}).text
# 下面提取影片信息部分
info = item.find_all('p', {'class': ''})
# print(info.text)
# 返回的是一个列表,列表里是一个元组
# print(info[0].text)
info_contents = info[0].text
# 分割影片信息,提取影片 导演 || 主演 || 上映年份 || 国家/地区 || 类型
result = re.findall(
'^.*?\\u5bfc\\u6f14:\\s(.*?)\\s.*?\\u4e3b\\u6f14:\\s(.*?)\\s.*?(\\d{4})\\s.*?([\\u4e00-\\u9fa5].*)\\xa0.*?\\u002f.*?([\\u4e00-\\u9fa5].*?)\\s\\s.*$',
info_contents, re.S)
接着我们把数据以字典的方式存放到列表里。
# 把数据按找字典的格式存放到列表里
datas.append({
'片名': name,
'年份': result[0][2],
'评分': score,
'导演': result[0][0],
'主演': result[0][1],
'类型': result[0][4],
'国家/地区': result[0][3],
'经典台词': quote
})
OK,这样其实我们就把单张的豆瓣影片数据爬取完成了!
1.6、写入文件
写入文件用的是强大的pandas库,这里需要注意下编码格式,否则打开的可能是乱码。
df = pd.DataFrame(datas)
df.to_csv("豆瓣电影.csv", index=False, header=True, encoding='utf_8_sig')
2、我是如何“放弃”爬取多页数据的
接下来我们要做的问题就是多页爬取了,单页爬取对应的是一个URL,多页爬取对应的当然就是多个URL了
emmm,不太严格,严格来说应该是我们每次请求的URL附加的参数变了,我们找到每次请求附加的参数变化规律就可以了。
第一页对应的URL:https://movie.douban.com/top250?start=0&filter=
第二页对应的URL:https://movie.douban.com/top250?start=25&filter=
…
第十页对应的URL:https://movie.douban.com/top250?start=225&filter=
很简单就发现了对吧,就是start参数的值变了,于是我们可以这样构造URL
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
用for循环遍历就好了。(当然还要注意data=[]要放在最外面,要不然获取每页数据时,data就被清空了)
for k in range(10):
print("正在抓取第{}页数据...".format(k+1))
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
......再把之前的代码加上去就可以了。
大功告成!!!
可是,真的这样么,我太天真了,现实给我来了当头一棒。

第二页数据就报错了,没有result[0][2]条数据,也就是年份,emmm,其实不是年份,是因为我们写的正则表达式没有捕捉到主演信息,所以列表索引超了。仔细查找下问题,看下图!
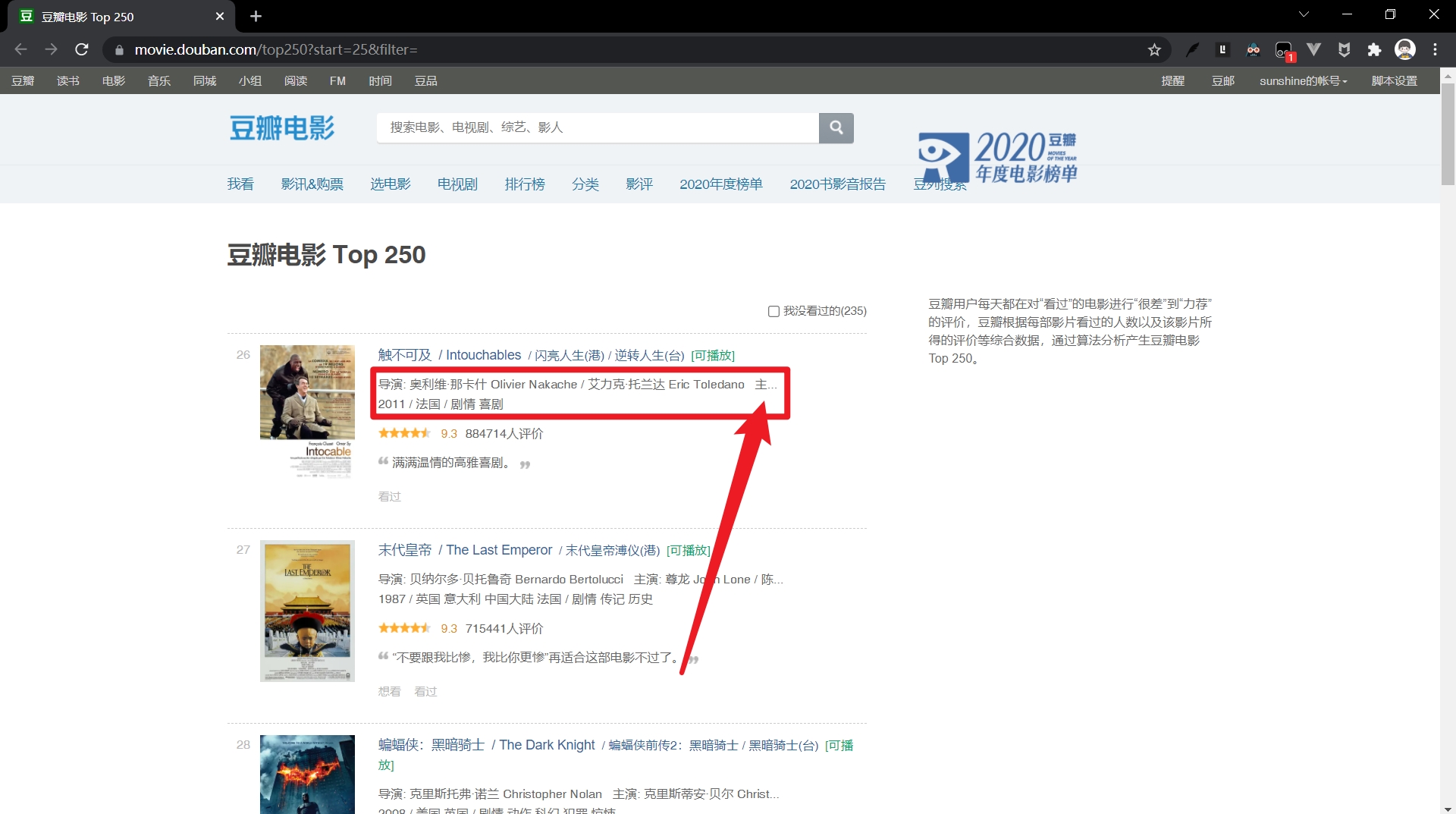
好吧,我确实忽略这个问题了,因为这个top榜主要是简介,字数什么的有限制,并不能完成主演等等详细数据的爬取任务,而且我们也没有去写异常处理。
仔细分析后,网页内容不只这一条不符合规范,如果要加入异常处理的话,需要加入很多,况且数据也不全,所以我放弃爬取多页了???
3、我是如何完成爬取多页数据的
在参考了其他同类的爬虫文章后,我发现,top 250 页面只是电影简介,详情都在点开电影链接之后。
比如,我们打开《肖申克的救赎》这部电影,该电影的所有信息都会按规范的格式展现在了我们的面前。
我们再写一个爬虫,爬取每个电影的链接,然后打开电影详情链接,去解析详情文本就可以了。

具体代码如下,这个我就不做具体分析了,思路和上面差不多,最复杂的就是解析数据和数据清洗那里,需要一点点尝试。
"""
-*- coding: utf-8 -*-
@Time : 2021/11/7 下午 4:25
@Author : SunGuoqi
@Website : https://sunguoqi.com
@Github: https://github.com/sun0225SUN
"""
import re
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 数据存放在列表里
datas = []
# 遍历十页数据
for k in range(10):
print("正在抓取第{}页数据...".format(k + 1))
url = 'https://movie.douban.com/top250?start=' + str(k * 25)
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
# 查找电影链接
lists = soup.find_all('div', {'class': 'hd'})
# 遍历每条电影链接
for item in lists:
href = item.a['href']
# 休息一下,防止被封
time.sleep(0.5)
# 请求每条电影,获得详细信息
response = requests.get(href, headers=headers)
# 把获取好的电影数据打包成BeautifulSoup对象
movie_soup = BeautifulSoup(response.text, 'lxml')
# 解析每条电影数据
# 片名
name = movie_soup.find('span', {'property': 'v:itemreviewed'}).text.split(' ')[0]
# 上映年份
year = movie_soup.find('span', {'class': 'year'}).text.replace('(', '').replace(')', '')
# 评分
score = movie_soup.find('strong', {'property': 'v:average'}).text
# 评价人数
votes = movie_soup.find('span', {'property': 'v:votes'}).text
infos = movie_soup.find('div', {'id': 'info'}).text.split('\\n')[1:11]
# infos返回的是一个列表,我们只需要索引提取就好了
# 导演
director = infos[0].split(': ')[1]
# 编剧
scriptwriter = infos[1].split(': ')[1]
# 主演
actor = infos[2].split(': ')[1]
# 类型
filmtype = infos[3].split(': ')[1]
# 国家/地区
area = infos[4].split(': ')[1]
# 数据清洗一下
if '.' in area:
area = infos[5].split(': ')[1].split(' / ')[0]
# 语言
language = infos[6].split(': ')[1].split(' / ')[0]
else:
area = infos[4].split(': ')[1].split(' / ')[0]
# 语言
language = infos[5].split(': ')[1].split(' / ')[0]
if '大陆' in area or '香港' in area or '台湾' in area:
area = '中国'
if '戛纳' in area:
area = '法国'
# 时长
times0 = movie_soup.find(attrs={'property': 'v:runtime'}以上是关于豆瓣电影TOP250爬虫及可视化分析笔记的主要内容,如果未能解决你的问题,请参考以下文章