CVPR 2021 | 基于Transformer的端到端视频实例分割方法
Posted jinnan88
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR 2021 | 基于Transformer的端到端视频实例分割方法相关的知识,希望对你有一定的参考价值。
实例分割是计算机视觉中的基础问题之一。虽然静态图像中的实例分割已经有很多的研究,对视频的实例分割(Video Instance Segmentation,简称VIS)的研究却相对较少。而真实世界中的摄像头所接收的,无论自动驾驶背景下车辆实时感知的周围场景,还是网络媒体中的长短视频,大多数为视频流的信息而非纯图像信息。因而研究对视频建模的模型有着十分重要的意义,本文系美团无人配送团队在CVPR 2021发表的一篇论文解读。
前言
实例分割是计算机视觉中的基础问题之一。目前,静态图像中的实例分割业界已经进行了很多的研究,但是对视频的实例分割(Video Instance Segmentation,简称VIS)的研究却相对较少。而真实世界中的摄像头所接收的,无论是自动驾驶背景下车辆实时感知的周围场景,还是网络媒体中的长短视频,大多数都是视频流信息而非纯图像信息。因而研究对视频建模的模型有着十分重要的意义,本文系美团无人配送团队在CVPR2021发表的一篇Oral论文: 《End-to-End Video Instance Segmentation with Transformers》的解读。本届CVPR大会共收到7015篇有效投稿,最终共1663篇论文被接收,论文录用率为23.7%,Oral的录用率仅为4%。
背景
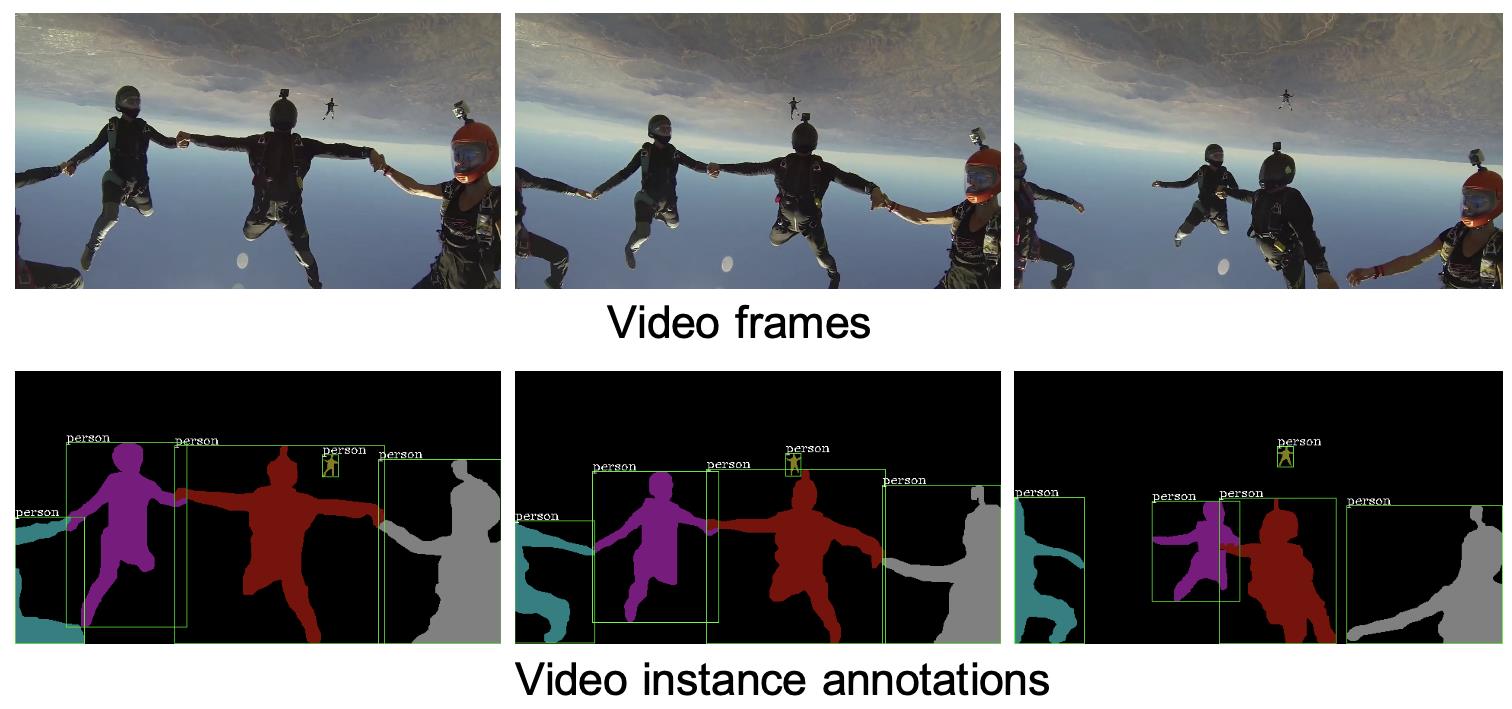
图像的实例分割指的是对静态图像中感兴趣的物体进行检测和分割的任务。视频是包含多帧图像的信息载体,相对于静态图像来说,视频的信息更为丰富,因而建模也更为复杂。不同于静态图像仅含有空间的信息,视频同时含有时间维度的信息,因而更接近对真实世界的刻画。其中,视频的实例分割指的是对视频中感兴趣的物体进行检测、分割和跟踪的任务。如图1所示,第一行为给定视频的多帧图像序列,第二行为视频实例分割的结果,其中相同颜色对应同一个实例。视频实例分割不光要对单帧图像中的物体进行检测和分割,而且要在多帧的维度下找到每个物体的对应关系,即对其进行关联和跟踪。
相关工作
现有的视频实例分割算法通常为包含多模块、多阶段的复杂流程。最早的Mask Track R-CNN[1]算法同时包含实例分割和跟踪两个模块,通过在图像实例分割算法Mask R-CNN[2]的网络之上增加一个跟踪的分支实现,该分支主要用于实例特征的提取。在预测阶段,该方法利用外部Memory模块进行多帧实例特征的存储,并将该特征作为实例关联的一个要素进行跟踪。该方法的本质仍然是单帧的分割加传统方法进行跟踪关联。Maskprop[3]在Mask Track R-CNN的基础上增加了Mask Propagation的模块以提升分割Mask生成和关联的质量,该模块可以实现当前帧提取的mask到周围帧的传播,但由于帧的传播依赖于预先计算的单帧的分割Mask,因此要得到最终的分割Mask需要多步的Refinement。该方法的本质仍然是单帧的提取加帧间的传播,且由于其依赖多个模型的组合,方法较为复杂,速度也更慢。
Stem-seg[4]将视频实例分割划分为实例的区分和类别的预测两个模块。为了实现实例的区分,模型将视频的多帧Clip构建为3D Volume,通过对像素点的Embedding特征进行聚类实现不同物体的分割。由于上述聚类过程不包含实例类别的预测,因此需要额外的语义分割模块提供像素的类别信息。根据以上描述,现有的算法大多沿袭单帧图像实例分割的思想,将视频实例分割任务划分为单帧的提取和多帧的关联多个模块,针对单个任务进行监督和学习,处理速度较慢且不利于发挥视频时序连续性的优势。本文旨在提出一个端到端的模型,将实例的检测、分割和跟踪统一到一个框架下实现,有助于更好地挖掘视频整体的空间和时序信息,且能够以较快的速度解决视频实例分割的问题。
VisTR算法介绍
重新定义问题
首先,我们对视频实例分割这一任务进行了重新的思考。相较于单帧图像,视频含有关于每个实例更为完备和丰富的信息,比如不同实例的轨迹和运动模态,这些信息能够帮助克服单帧实例分割任务中一些比较困难的问题,比如外观相似、物体邻近或者存在遮挡的情形等。另一方面,多帧所提供的关于单个实例更好的特征表示也有助于模型对物体进行更好的跟踪。因此,我们的方法旨在实现一个端到端对视频实例目标进行建模的框架。为了实现这一目标,我们第一个思考是:视频本身是序列级别的数据,能否直接将其建模为序列预测的任务?比如,借鉴自然语言处理(NLP)任务的思想,将视频实例分割建模为序列到序列(Seq2Seq)的任务,即给定多帧图像作为输入,直接输出多帧的分割Mask序列,这时需要一个能够同时对多帧进行建模的模型。
第二个思考是:视频的实例分割实际同时包含实例分割和目标跟踪两个任务,能否将其统一到一个框架下实现?针对这个我们的想法是:分割本身是像素特征之间相似度的学习,而跟踪本质是实例特征之间相似度的学习,因此理论上他们可以统一到同一个相似度学习的框架之下。
基于以上的思考,我们选取了一个同时能够进行序列的建模和相似度学习的模型,即自然语言处理中的Transformer[5]模型。Transformer本身可以用于Seq2Seq的任务,即给定一个序列,可以输入一个序列。并且该模型十分擅长对长序列进行建模,因此非常适合应用于视频领域对多帧序列的时序信息进行建模。其次,Transformer的核心机制,自注意力模块(Self-Attention),可以基于两两之间的相似度来进行特征的学习和更新,使得将像素特征之间相似度以及实例特征之间相似度统一在一个框架内实现成为可能。以上的特性使得Transformer成为VIS任务的恰当选择。除此之外,Transformer已经有被应用于计算机视觉中进行目标检测的实践DETR[6]。因此我们基于transformer设计了视频实例分割(VIS)的模型VisTR。
VisTR算法流程
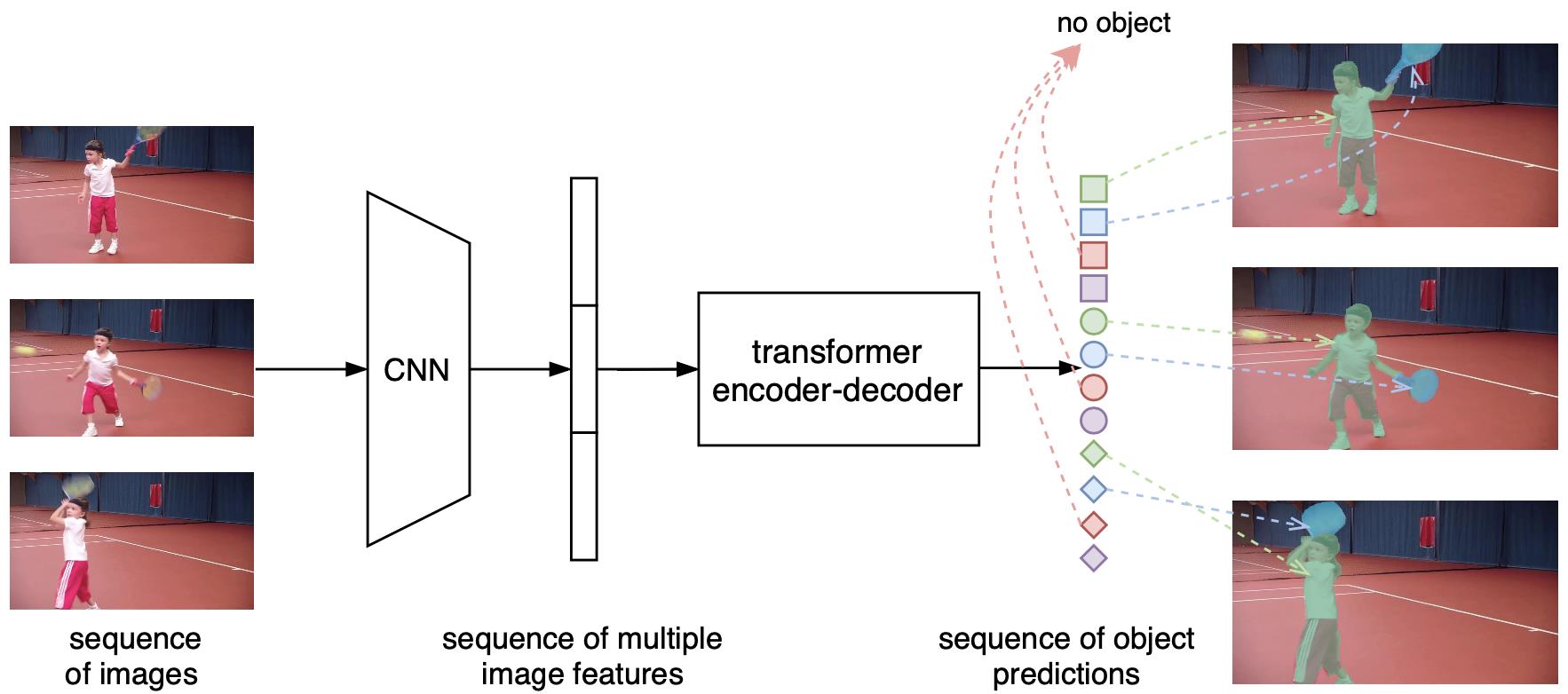
遵照上述思想,VisTR的整体框架如图2所示。图中最左边表示输入的多帧原始图像序列(以三帧为例),右边表示输出的实例预测序列,其中相同形状对应同一帧图像的输出,相同颜色对应同一个物体实例的输出。给定多帧图像序列,首先利用卷积神经网络(CNN)进行初始图像特征的提取,然后将多帧的特征结合作为特征序列输入Transformer进行建模,实现序列的输入和输出。
不难看出,首先,VisTR是一个端到端的模型,即同时对多帧数据进行建模。建模的方式即:将其变为一个Seq2Seq的任务,输入多帧图像序列,模型可以直接输出预测的实例序列。虽然在时序维度多帧的输入和输出是有序的,但是单帧输入的实例的序列在初始状态下是无序的,这样仍然无法实现实例的跟踪关联,因此我们强制使得每帧图像输出的实例的顺序是一致的(用图中同一形状的符号有着相同的颜色变化顺序表示),这样只要找到对应位置的输出,便可自然而然实现同一实例的关联,无需任何后处理操作。为了实现此目标,需要对属于同一个实例位置处的特征进行序列维度的建模。针对性地,为了实现序列级别的监督,我们提出了Instance Sequence Matching的模块。同时为了实现序列级别的分割,我们提出了Instance Sequence Segmentation的模块。端到端的建模将视频的空间和时间特征当做一个整体,可以从全局的角度学习整个视频的信息,同时Transformer所建模的密集特征序列又能够较好的保留细节的信息。
VisTR网络结构
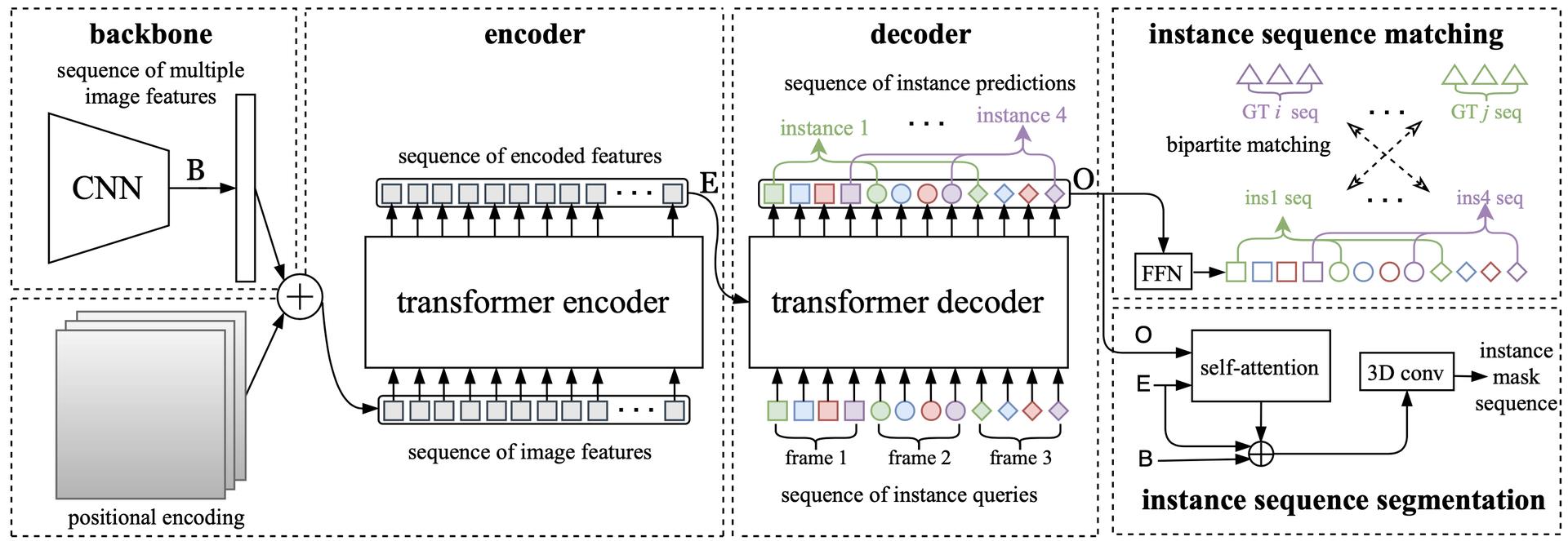
VisTR的详细网络结构如图3所示,以下是对网络的各个组成部分的介绍:
- Backbone:主要用于初始图像特征的提取。针对序列的每一帧输入图像,首先利用CNN的Backbone进行初始图像特征的提取,提取的多帧图像特征沿时序和空间维度序列化为多帧特征序列。由于序列化的过程损失了像素原始的空间和时序信息,而检测和分割的任务对于位置信息十分敏感,因此我们将其原始的空间和水平位置进行编码,作为Positional Encoding叠加到提取的序列特征上,以保持原有的位置信息。Positional Encoding的方式遵照Image Transformer[7]的方式,只是将二维的原始位置信息变为了三维的位置信息,这部分在论文中有详细的说明。
- Encoder:主要用于对多帧特征序列进行整体的建模和更新。输入前面的多帧特征序列,Transformer的Encoder模块利用Self-Attention模块,通过点和点之间相似度的学习,进行序列中所有特征的融合和更新。该模块通过对时序和空间特征的整体建模,能够对属于同一个实例的特征进行更好的学习和增强。
- Decoder:主要用于解码输出预测的实例特征序列。由于Encoder输入Decoder的是密集的像素特征序列,为了解码出稀疏的实例特征,我们参考DETR的方式,引入Instance Query进行代表性的实例特征的解码。Instance Query是网络自身学习的Embedding参数,用于和密集的输入特征序列进行Attention运算选取能够代表每个实例的特征。以处理3帧图像,每帧图像预测4个物体为例,模型一共需要12个Instance Query,用于解码12个实例预测。和前面的表示一致,用同样的形状表示对应同一帧图像的预测,同样的颜色表示同一个物体实例在不同帧的预测。通过这种方式,我们可以构造出每个实例的预测序列,对应为图3中的Instance 1...Instance 4,后续过程中模型都将单个物体实例的序列看作整体进行处理。
- Instance Sequence Matching:主要用于对输入的预测结果进行序列级别的匹配和监督。前面已经介绍了从序列的图像输入到序列的实例预测的过程。但是预测序列的顺序其实是基于一个假设的,即在帧的维度保持帧的输入顺序,而在每帧的预测中,不同实例的输出顺序保持一致。帧的顺序比较容易保持,只要控制输入和输出的顺序一致即可,但是不同帧内部实例的顺序其实是没有保证的,因此我们需要设计专门的监督模块来维持这个顺序。在通用目标检测之中,在每个位置点会有它对应的Anchor,因此对应每个位置点的Ground Truth监督是分配好的,而在我们的模型中,实际上是没有Anchor和位置的显式信息,因此对于每个输入点我们没有现成的属于哪个实例的监督信息。为了找到这个监督,并且直接在序列维度进行监督,我们提出了Instance Sequence Matching的模块,这个模块将每个实例的预测序列和标注数据中每个实例的Ground Truth序列进行二分匹配,利用匈牙利匹配的方式找到每个预测最近的标注数据,作为它的Groud Truth进行监督,进行后面的Loss计算和学习。
- Instance Sequence Segmentation:主要用于获取最终的分割结果序列。前面已经介绍了Seq2Seq的序列预测过程,我们的模型已经能够完成序列的预测和跟踪关联。但是到目前为止,我们为每个实例找到的只是一个代表性的特征向量,而最终要解决的是分割的任务,如何将这个特征向量变为最终的Mask序列,就是Instance Sequence Segmentation模块要解决的问题。前面已经提到,实例分割本质是像素相似度的学习,因此我们初始计算Mask的方式就是利用实例的预测和Encode之后的特征图计算Self-Attention相似度,将得到的相似度图作为这个实例对应帧的初始Attention Mask特征。为了更好的利用时序的信息,我们将属于同一个实例的多帧的Attention Mask 作为Mask序列输入3D卷积模块进行分割,直接得到最终的分割序列。这种方式通过利用多帧同一实例的特征对单帧的分割结果进行增强,可以最大化的发挥时序的优势。
VisTR损失函数
根据前面的描述,网络学习中需要计算损失的主要有两个地方,一个是Instance Sequence Matching阶段的匹配过程,一个是找到监督之后最终整个网络的损失函数计算过程。
Instance Sequence Matching过程的计算公式如式1所示:由于Matching阶段只是用于寻找监督,而计算Mask之间的距离运算比较密集,因此在此阶段我们只考虑Box和预测的类别c两个因素。第一行中的yi表示对应第i个实例的Ground Truth序列,其中c表示类别,b表示Boundingbox,T表示帧数,即T帧该实例对应的类别和Bounding Box序列。第二行和第三行分别表示预测序列的结果,其中p表示在ci这个类别的预测的概率,b表示预测的Bounding Box。序列之间距离的运算是通过两个序列对应位置的值两两之间计算损失函数得到的,图中用Lmatch表示,对于每个预测的序列,找到Lmatch最低那个Ground Truth序列作为它的监督。根据对应的监督信息,就可以计算整个网络的损失函数。
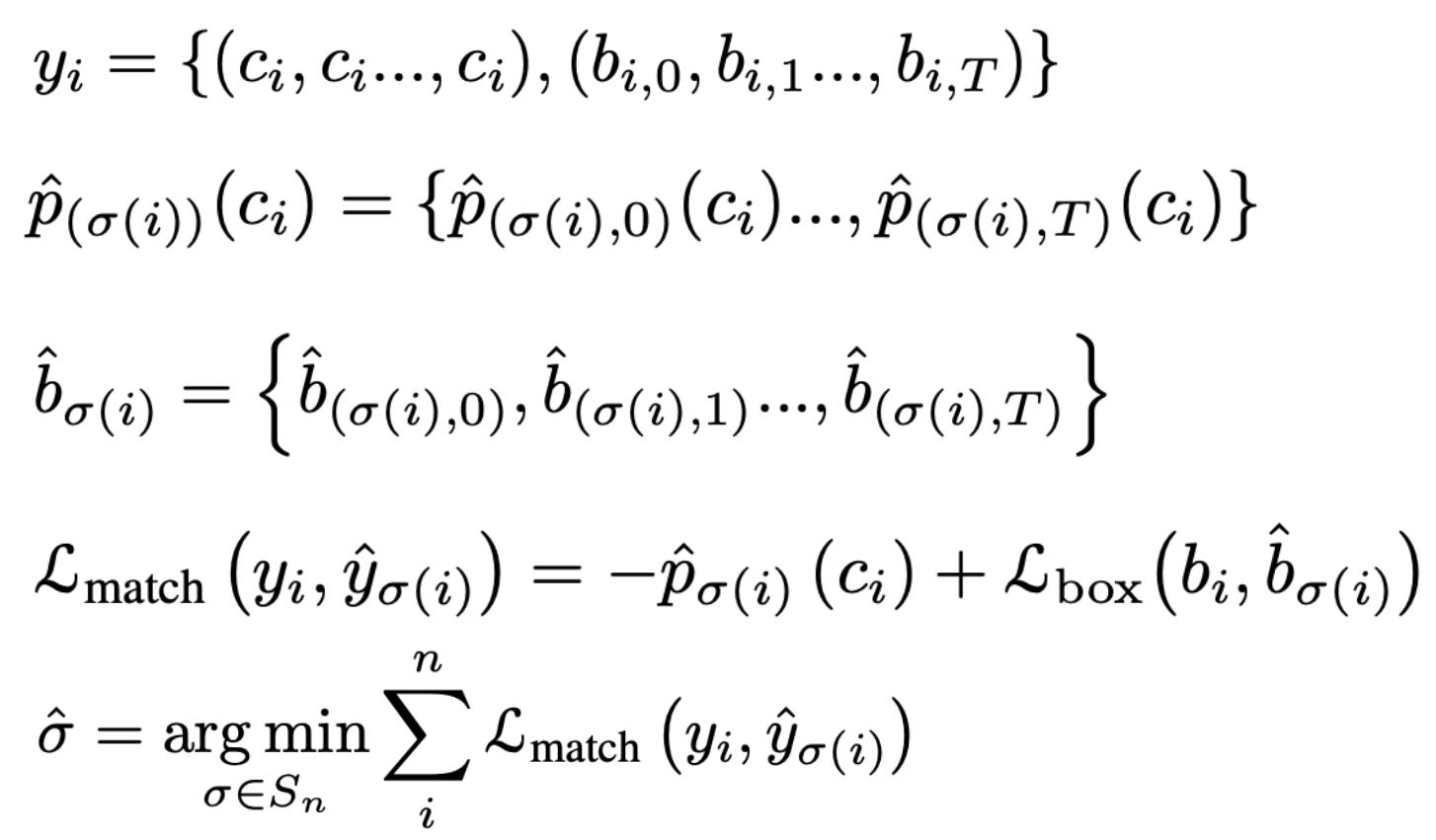
由于我们的方法是将分类、检测、分割和跟踪做到一个端到端网络里,因此最终的损失函数也同时包含类别、Bounding Box和Mask三个方面,跟踪通过直接对序列算损失函数体现。公式2表示分割的损失函数,得到了对应的监督结果之后,我们计算对应序列之间的Dice Loss和Focal Loss作为Mask的损失函数。
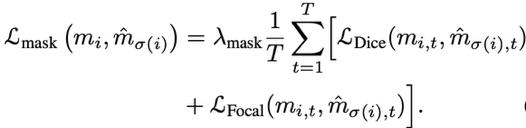
最终的损失函数如公式3所示,为同时包含分类(类别概率)、检测(Bounding Box)以及分割(Mask)的序列损失函数之和。
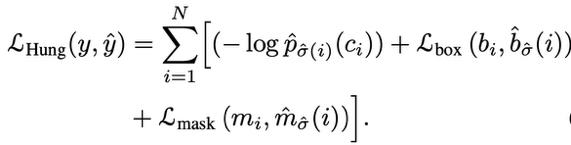
实验结果
为了验证方法的效果,我们在广泛使用的视频实例分割数据集YouTube-VIS上进行了实验,该数据集包含2238个训练视频,302个验证视频以及343个测试视频,以及40个物体类别。模型的评估标准包含AP和AR,以视频维度多帧Mask之间的IOU作为阈值。
时序信息的重要性
相对于现有的方法,VisTR的最大区别是直接对视频进行建模,而视频和图像的主要区别在于视频包含着丰富的时序信息,如果有效的挖掘和学习时序信息是视频理解的关键,因此我们首先探究了时序信息的重要性。时序包含两个维度:时序的多少(帧数)以及有序和无序的对比。
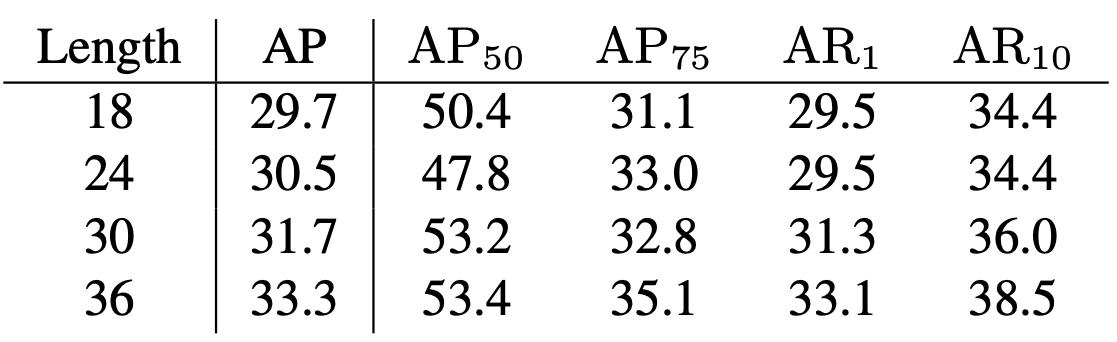
表1中展示了我们利用不同帧数的Clip训练模型最终的测试效果,不难看出,随着帧数从18提升至36,模型的精度AP也在不断提升,证明多帧提供的更丰富的时序信息对模型的学习有所帮助。

表2中展示了利用打乱物理时序的Clip以及按照物理时序的Clip进行模型训练的效果对比,可以看出,按照时间顺序训练的模型有一个点的提升,证明VisTR有学到物理时间下物体变化和规律,而按照物理时间顺序对视频建模也有助于视频的理解。
Query探究
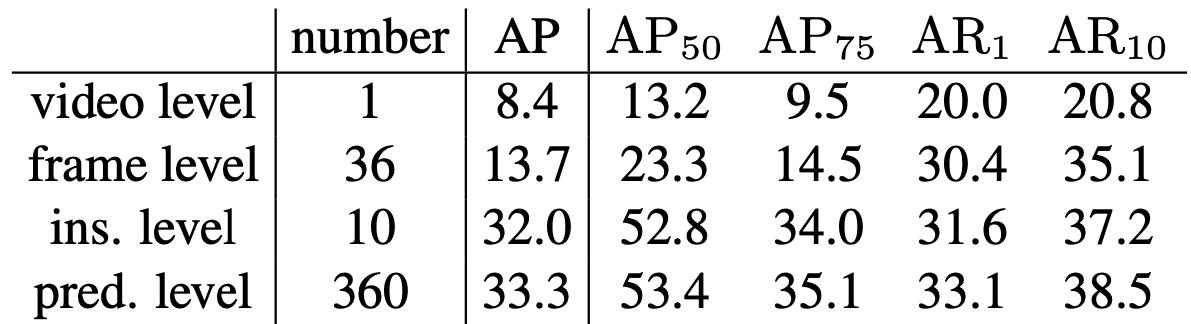
第二个实验是对于Query的探究。由于我们的模型直接建模的36帧图像,对每帧图像预测10个物体,因此需要360个Query,对应表3最后一行的结果(Prediction Level)。我们想探究属于同一帧或者同一个实例的Query之间是否存在一定的关联,即是否可以共享。针对这个目标,我们分别设计了Frame Level的实验:即一帧只使用一个Query的特征进行预测,以及Instance level的实验:一个实例只使用一个Query的特征进行预测。
可以看到,Instance Level的结果只比Prediction Level的结果少一个点,而Frame Level的结果要低20个点,证明不同帧属于同一个Instance的Query可以共享,而同一帧不同Instance的Query信息不可共享。Prediction Level的Query是和输入的图像帧数成正比的,而Instance Level的Query可以实现不依赖输入帧数的模型。只限制模型要预测的Instance个数,不限制输入帧数,这也是未来可以继续研究的方向。除此之外,我们还设计了Video Level的实验,即整个视频只用一个Query的Embedding特征进行预测,这个模型可以实现8.4的AP。
其他设计
以下是实验过程中我们发现有效的其他设计。

由于在特征序列化的过程中会损失原有的空间和时间信息,我们提供了原始的Positional Encoding特征以保留原有的位置信息。在表5中进行了有无该模块的对比,Positional Encoding提供的位置信息可以带来约5个点的提升。

在分割的过程中,我们通过计算实例的Prediction与Encoded之后特征的Self-Attention来获取初始的Attention Mask。在表6中,我们进行了利用CNN-Encoded的特征和利用Transformer-Encoded的特征进行分割的效果对比,利用Transformer的特征可以提升一个点。证明了Transformer进行全局特征更新的有效性。

表6中展示了在分割模块有无3D卷积的效果对比,使用3D卷积可以带来一个点的提升,证明了利用时序信息直接对多帧mask分割的有效性。
可视化结果

VisTR在YouTube-VIS的可视化效果如图4所示,其中每行表示同一个视频的序列,相同颜色对应同一个实例的分割结果。可以看出无论是在 (a).实例存在遮挡(b).实例位置存在相对变化 (c).同类紧邻易混淆的实例 以及 (d).实例处于不同姿态情形下,模型都能够实现较好的分割个跟踪,证明在有挑战性的情况下,VisTR仍具有很好的效果。
方法对比
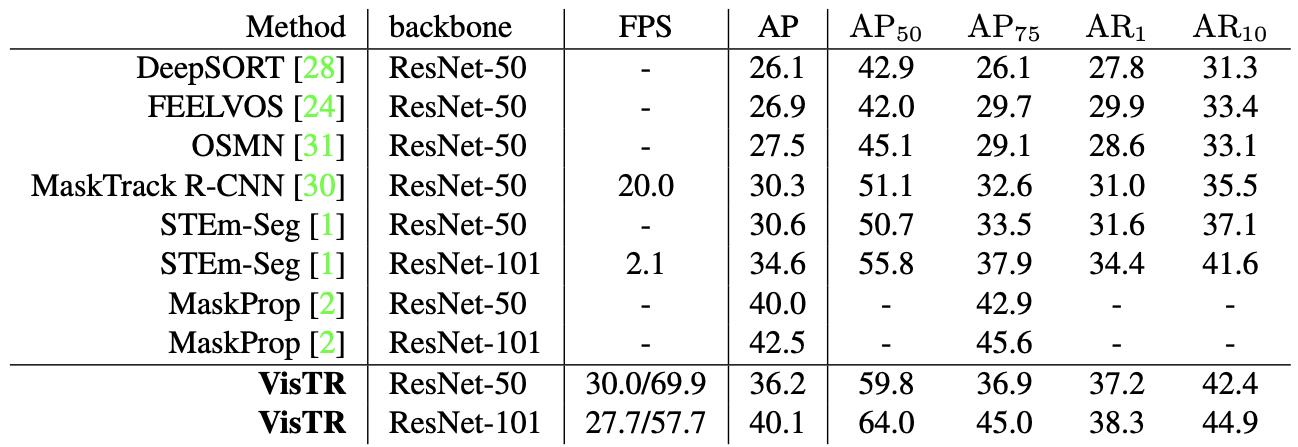
表7是我们的方法和其他方法在YoutubeVIS数据集上的对比。我们的方法实现了单一模型的最好效果(其中MaskProp包含多个模型的组合),在57.7FPS的速度下实现了40.1的AP。其中前面的27.7指的是加上顺序的Data Loading部分的速度(这部分可以利用并行进行优化),57.7指的是纯模型Inference的速度。由于我们的方法直接对36帧图像同时进行建模,因此相对于同样模型的单帧处理,理想情况下能带来大约36倍的速度提升,更有助于视频模型的广泛应用。
总结与展望
视频实例分割指的是同时对视频中感兴趣的物体进行分类,分割和跟踪的任务。现有的方法通常设计复杂的流程来解决此问题。本文提出了一种基于Transformer的视频实例分割新框架VisTR,该框架将视频实例分割任务视为直接端到端的并行序列解码和预测的问题。给定一个含有多帧图像的视频作为输入,VisTR直接按顺序输出视频中每个实例的掩码序列。该方法的核心是一种新的实例序列匹配和分割的策略,能够在整个序列级别上对实例进行监督和分割。 VisTR将实例分割和跟踪统一到了相似度学习的框架下,从而大大简化了流程。在没有任何trick的情况下,VisTR在所有使用单一模型的方法中获得了最佳效果,并且在YouTube-VIS数据集上实现了最快的速度。
据我们所知,这是第一个将Transformers应用于视频分割领域的方法。希望我们的方法能够启发更多视频实例分割的研究,同时也希望此框架未来能够应用于更多视频理解的任务。关于论文的更多细节,请参考原文:《End-to-End Video Instance Segmentation with Transformers》,同时代码也已经在GitHub上开源:https://github.com/Epiphqny/VisTR,欢迎大家来了解或使用。
作者
- 美团无人车配送中心: 钰晴、昭良、保山、申浩等。
- 阿德莱德大学:王鑫龙、沈春华。
参考文献
- Video Instance Segmentation, https://arxiv.org/abs/1905.04804.
- Mask R-CNN, https://arxiv.org/abs/1703.06870.
- Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation, https://arxiv.org/abs/1912.04573.
- STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos, https://arxiv.org/abs/2003.08429.
- Attention Is All You Need, https://arxiv.org/abs/1706.03762.
- End-to-End Object Detection with Transformers, https://arxiv.org/abs/2005.12872.
- Image Transformer, https://arxiv.org/abs/1802.05751.
招聘信息
美团无人车配送中心大量岗位持续招聘中,诚招算法/系统/硬件开发工程师及专家。欢迎感兴趣的同学发送简历至:ai.hr@meituan.com(邮件标题注明:美团无人车团队)。
阅读美团技术团队更多技术文章合集
前端 | 算法 | 后端 | 数据 | 安全 | 运维 | ios | android | 测试
| 在公众号菜单栏对话框回复【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至tech@meituan.com申请授权。
以上是关于CVPR 2021 | 基于Transformer的端到端视频实例分割方法的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2022MatteFormer: Transformer-Based Image Matting via Prior-Tokens
论文速递CVPR2022 : 用于对象跟踪的统一transformer跟踪器
微软华人团队刷新COCO记录!全新目标检测机制达到SOTA|CVPR 2021
微软华人团队刷新COCO记录!全新目标检测机制达到SOTA|CVPR 2021