论文速递CVPR2022 : 用于对象跟踪的统一transformer跟踪器
Posted N0thing2say
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文速递CVPR2022 : 用于对象跟踪的统一transformer跟踪器相关的知识,希望对你有一定的参考价值。
【论文速递】CVPR2022 : 用于目标跟踪的统一transformer跟踪器
【论文原文】:Unified Transformer Tracker for Object Tracking
论文地址:https://arxiv.org/pdf/2203.15175v1.pdf
博主关键词: 多目标跟踪,transformer, correlation,Siamese
推荐相关论文:
【论文速递】CVPR2022 - 全局跟踪Transformers
-https://blog.csdn.net/Never_moresf/article/details/128704693
【论文速递】CVPR2022 - MeMOT: 带有记忆得到多目标跟踪
-https://blog.csdn.net/Never_moresf/article/details/128735708
摘要:
目标跟踪作为计算机视觉中的一个重要领域,已经形成了两个独立的场景,分别研究单对象跟踪(SOT)和多对象跟踪(MOT)。然而,由于两种任务的训练数据集和跟踪对象的不同,目前的一种跟踪场景的方法不容易适应另一种跟踪场景。虽然UniTrack [45]证明了可以使用具有多个头部的共享外观模型来处理单个跟踪任务,但它没有利用大规模跟踪数据集进行训练,并且在单目标跟踪上表现较差。在这项工作中,我们提出了统一transformer跟踪器(UTT),以解决不同场景下的跟踪问题。我们的UTT开发了一个跟踪transformer来在SOT和MOT中跟踪目标,利用目标特征和跟踪帧特征之间的相关性来定位目标。我们证明了SOT和MOT任务都可以在这个框架内得到解决,并且该模型可以通过在单个任务的数据集上交替优化SOT和MOT目标来同时进行端到端训练。在SOT和MOT数据集上训练了一个统一的模型,在几个基准测试上进行了广泛的实验。
关键词 多目标跟踪,transformer, correlation,Siamese
简介:
视觉目标跟踪是计算机视觉的基本任务之一,具有众多应用[10,25,40,55]。与明确定义的目标分类和检测问题[18,19,46,50]不同,目标跟踪因场景不同可以分为两种主要范式1)单目标跟踪(SOT)是在整个视频[13,25]中跟踪在第一帧中被标注的目标,类别任意;2)多目标跟踪(MOT)用于估计视频中目标的边界框和id,其中目标的类别是已知的,对象可能出现或消失[53,55]。目前跟踪的方法是通过在SOT或MOT的单个数据集上的训练模型来分别解决单个任务。
孪生架构在SOT中得到了广泛的应用,各种设计侧重于提高对象[10, 13, 25, 49]的判别性表示。对于MOT,检测跟踪是最流行的范式,在几个基准[2,37,55]上达到最高的跟踪性能。这个范式不适用于SOT,因为该模型将无法检测到SOT中不可见类别的目标。一些MOT方法[24,60]利用SOT [4]中的孪生跟踪器来预测跟踪帧中目标的位置,并将预测的框与检测框融合,以提高检测结果。然而,这些方法与MOT中的检测跟踪方法相比并不占优。尽管孪生追踪器已经应用于两种跟踪任务中,但这些工作都不能够以统一的范例解决两种跟踪任务。实际上,一个统一的跟踪系统在许多领域都具有重要意义。对于AR/VR应用程序,跟踪特定的或看不见的实例,如个人杯子,与SOT有关,而感知像人等一般类别的环境则与MOT有关。维护两个独立的跟踪系统是非常昂贵和低效的。统一跟踪系统可以根据需求轻松地切换跟踪模式,在现实部署中变得更加重要。
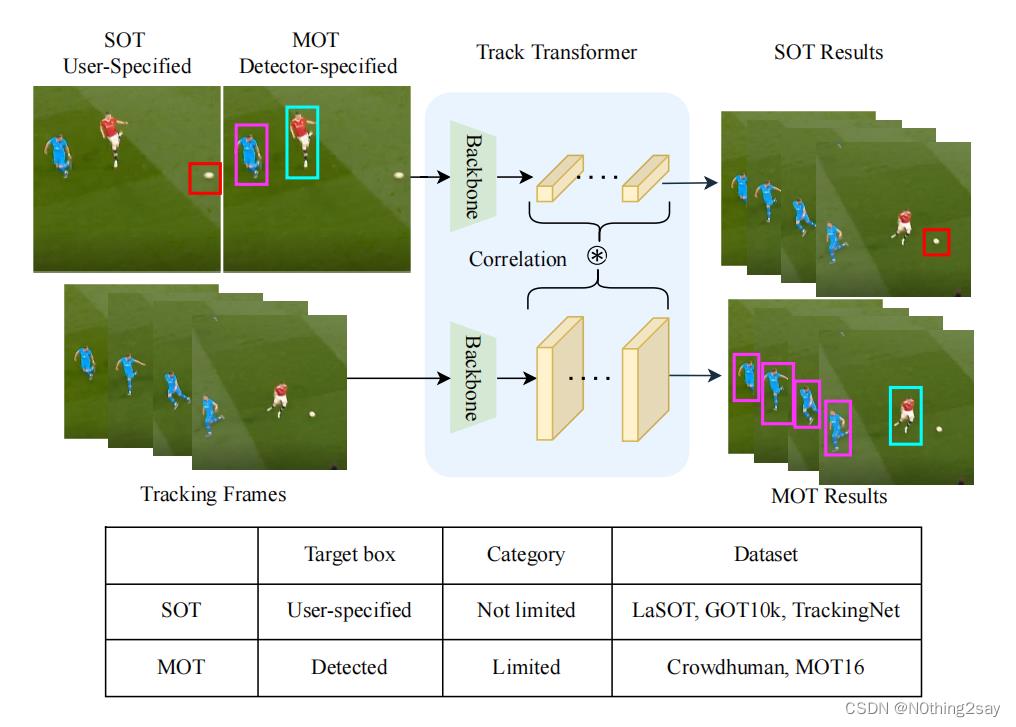
UniTrack [45]首先尝试通过共享主干和融合多个跟踪头来同时处理SOT和MOT。然而,由于头部设计和不同任务中训练数据集的差异,未能利用大规模的跟踪数据集进行训练。如图1所示,SOT和MOT中的训练数据来自不同的来源。SOT中的数据集只提供一个视频中的单个目标的注释,而MOT数据集中的密集的对象注释可用的,尽管对象类别固定。因此,UniTrack [45]的跟踪能力有限,该模型在复杂的场景中无法跟踪对象。
在本文中,我们引入了一个统一的transformer跟踪器(UTT),用于解决这两个跟踪任务。对于在SOT中指定或在MOT中检测到的参考帧的跟踪目标,我们基于之前的定位得到了跟踪帧中的小特征图proposal。然后将目标特征与特征图proposal相关联,以更新目标表示并输出目标定位。这使得我们的UTT能够以相同的设计跟踪SOT和MOT中的对象。更新后的目标特征与新的搜索特征proposal进一步相关联,该proposal基于产生的目标定位进行裁剪。这个过程重复了多次,以细化跟踪目标的定位。为了利用两个任务中的训练样本,我们在每个任务中使用数据集训练网络。实验表明,我们的跟踪器在这两个任务上都能很好地学习。我们的主要贡献总结如下:

•我们提出了一种新的统一transformer跟踪器(UTT),可用于单目标和多目标跟踪。据我们所知,这是第一个在这两个任务上进行端到端训练的跟踪模型。
•我们开发了一种新型的、有效的跟踪transformer,通过目标特征和跟踪帧特征之间的相关性来定位目标。目标特性通过我们的transformer设计得到了很好的编码。
•为了验证统一的目标跟踪能力,我们在SOT和MOT基准测试上评估了我们的UTT。我们提出的方法不仅在LaSOT[16]、TrackingNet[32]和GOT-10k [22]上取得了与现有算法相当的性能,而且在MOT16 [31]上也取得了与最先进算法相当的性能。
【社区访问】
 【论文速递 | 精选】
【论文速递 | 精选】
 阅读原文访问社区
阅读原文访问社区
https://bbs.csdn.net/forums/paper
以上是关于论文速递CVPR2022 : 用于对象跟踪的统一transformer跟踪器的主要内容,如果未能解决你的问题,请参考以下文章