云计算与Hadoop期末考试知识点复习
Posted 桃浪十七
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云计算与Hadoop期末考试知识点复习相关的知识,希望对你有一定的参考价值。
七、八、九、十、十二、十三放到一起理解。
一、大数据的概念和特点、分类
又称巨量数据,是指数据量达到无法用 人脑,甚至现有工具获取,处理,并整理成为帮助企业经营决策更积极目的的资讯。
特点:数据量大,类型多,时效性,速度快,真实性。
分类:传统企业数据,机器和传感器数据,社交数据。
二、云计算的概念,特点
云计算是基于互联网的计算机方式,通过这计算方式,可以把共享的软硬件信息按需分配给计算机和其他设备。
特点:虚拟,灵活,可靠,可扩展,性价比高,按需部署。
三、Iaas,Paas,Saas
Iaas是基础设施即服务,完全的自助服务,主要提供基础资源。
Paas是平台即服务,主要提供软件部署平台,屏蔽底层实现细节和操作系统,开发者只需要关注业务逻辑问题。
Saas软件即服务,完全把软件开发管理托福第三方平台,不需要关乎技术问题,直接拿来使用。
四、虚拟化技术的概念和特征
虚拟化技术,是指通过虚拟化,把一台计算机虚拟化为多台逻辑计算机,多个逻辑计算机可以同时运行不同的操作系统。软件在相互独立的空间内运行且互不打扰,提高计算机的工作效率。
特征:分区,隔离,封装,硬件独立。
五、Hadoop的特征,优缺点,运行模式
特征:分布式架构,多租户环境,采用HDFS架构,可靠的文件系统,丰富的计算引擎,基于Hadoop的Spark架构可以处理更多的数据请求。
优点:高效,可扩展,容错低成本,可靠。
缺点:不适合低延迟的数据访问,不适合大量小文件,不支持多用户写入并修改文件。
运行模式:本地模式:Hadoop没有守护进程,程序运行在一个JVM上。
伪分布式:Hadoop守护进程运行在本地机器上,模拟小型集群。
全分布式:Hadoop的守护进程运行在集群中。
六、HDFS的概念和特征
概念:分布式的文件系统,用于存储文件,由很多计算机联合实现功能。
特征:面向大规模数据的,运行在廉价机器上的,简单地一致性,流式访问。
七、HDFS处理任务流程
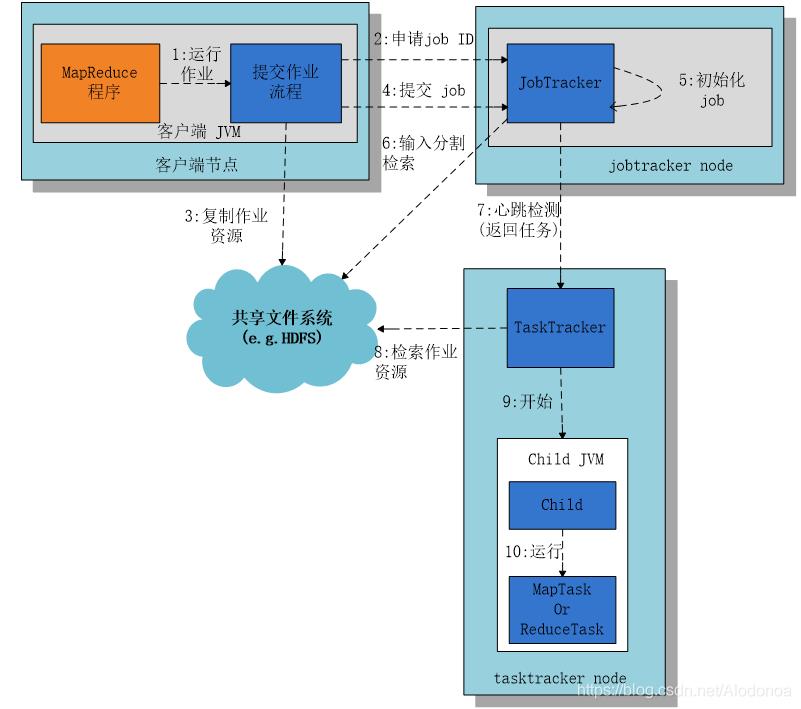
八、JobTracker、TaskTracker节点的工作原理及特征(*)
(1)一个集群中只有一个JobTracker进程,它运行在主节点上。该进程负责将应用程序与Hadoop系统对接。当执行用户提交的应用程序时,JobTracker负责确定要处理的文件,并为所执行任务分配指定的节点主机。
(2)TaskTracker进程在从节点上,与同样位于从节点的负责存储数据的DataNode进程相结合进行工作。TaskTracker的作用是独立管理其所在从节点上的任务进程。
(3)每个从节点上只有一个TaskTracker,但它可以产生多个JVM进程,以并行处理多个Map和Reduce任务。TaskTracker的一个重要职责是与JobTracker进行定时通讯联络。
(4)如果JobTracker不能准时获得TaskTracker的联络信息,则认为该节点已崩溃。这会导致JobTracker将任务重新分配给其他从节点。
九、DataNode、NameNode节点的工作原理及特征(*)
主节点的NameNode进程是HDFS文件系统的守护进程。该进程负责:
记录文件是如何分割成数据块,以及存储数据块的数据节点的信息。
对内存和I/O进行集中管理
通常情况下,运行NameNode的服务器上是不执行计算任务的,从而避免降低系统性能。另外,NameNode进程是单点的运行的,一旦宕机,将导致整个系统瘫痪。
各从节点服务器均会运行一个DataNode后台进程,负责将HDFS数据块读写到本地文件系统。
当客户端有读/写要求时,NameNode告诉客户端去哪个DataNode进行读/写操作。这样客户端将直接与这个DataNode服务器的进程进行读/写访问
十、Host、Slave节点特征(*)
(1)Host节点主要对域名解析到哪个虚拟主机进行配置,其name属性即为访问的域名。
作为主节点(Master Node)的主机一个Hadoop集群中只能有一个主节点。
主节点是集群的核心,负责协调和管理对所有从节点的数据访问和计算工作。
作为从节点(Slave Node)的主机,除主节点主机外的所有主机均作为从节点。数据分布在各从节点上,由HDFS进行统一管理。
各从节点还担任着数据的计算工作。此工作由节点上的MapReduce子系统来完成。
十一、MapReduce的优点和特征
优点
(1)对硬件低要求,MapReduce模型是面向由数千台中低端计算机组成的大规模集群而设计的,基于此优点MapReduce模型可以在现有的异构集群中很好的运行。
(2)接口化,MapReduce模型通过简单的接口实现了大规模分布式计算的自动并行化,它屏蔽了需要大量并行代码去实现的容错、负载均衡和数据分布等复杂细节,程序员只需关注实际操作数据的Map函数和Reduce函数即可。
(3)编程语言多样化,MapReduce模型支持Java、C、C++、Python、Shell、php、Ruby等多种开发语言,程序员可以选择所熟悉的语言编写Map函数和Reduce函数。
(4)扩展性强,它采用的shared-nothing结构保证了其良好的伸缩性,同时,使其具有了各个节点间的松耦合性和较强的容错能力,进而节点可以被任意地从集群中移除,而几乎不影响现有任务的执行。
(5)数据分析低延迟,基于MapReduce模型的数据分析,无需复杂的数据预处理和写入数据库的过程,而是直接基于平面文件进行分析,并且其采用的计算模式是移动计算而非移动数据[3],因此可以将分析延迟最小化。
特征
MapReduce是一个基于集群的高性能并行计算平台
MapReduce是一个并行计算与运行软件框架
MapReduce是一个并行程序设计模型与方法
十二、MapReduce处理流程
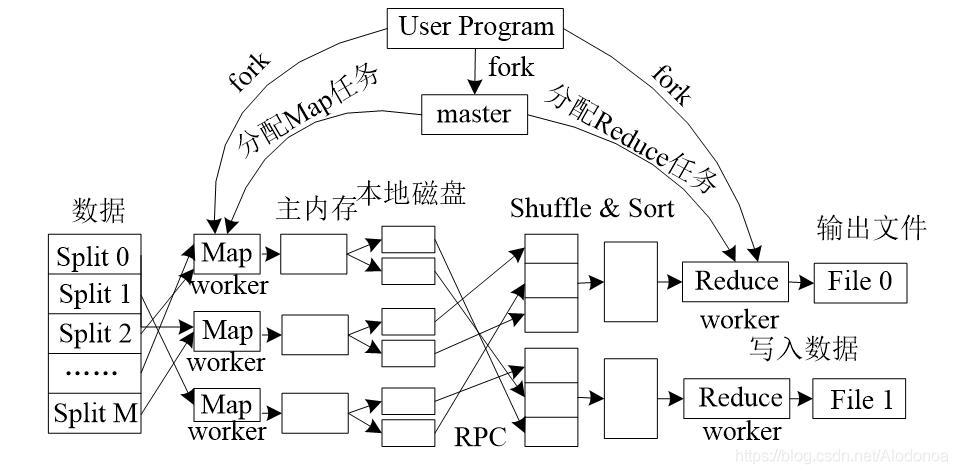
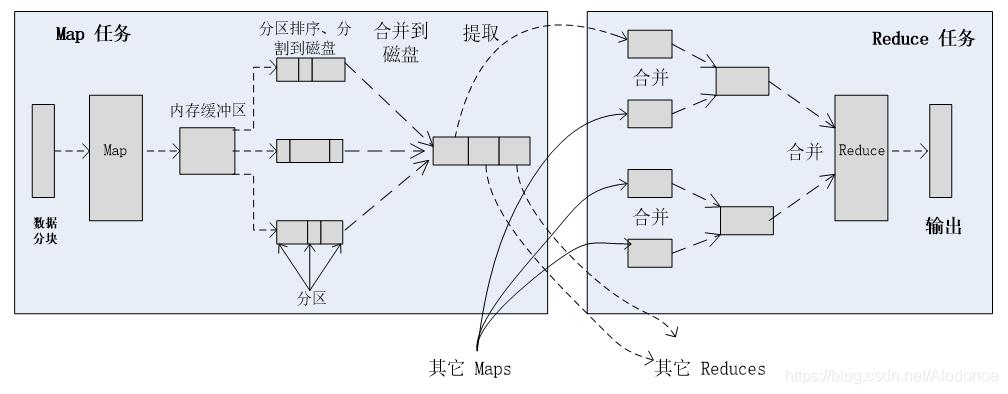
十三、shuffle & sort的过程
十四、“心跳”的概念
心跳机制是定时发送一个自定义的结构体(心跳包),让对方知道自己还活着,以确保连接的有效性的机制。
十五、HBase的特征
(1)适合存储超大文件
(2)适用于流式的数据访问
(3)支持简单的一致性模型
(4)计算向数据靠拢以上是关于云计算与Hadoop期末考试知识点复习的主要内容,如果未能解决你的问题,请参考以下文章