大数据系列之Kafka安装
Posted 路漫漫,其修远,吾将上下而求索
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列之Kafka安装相关的知识,希望对你有一定的参考价值。

先简单说下安装kafka的流程。。(可配置多个zookeeper,这篇文只说一个zookeeper场景)
1.环境配置:jdk1.7+ (LZ用的是jdk1.8)
2.资料准备:下载 kafka_2.10-0.10.1.1.tgz ,官网链接为https://www.apache.org/dyn/closer.cgi?path=/kafka/0.10.1.1/kafka_2.10-0.10.1.1.tgz
3.单机版安装步骤:
a.将tgz放入目录: /app/
b.解压:
tar -xzvf kafka_2.10-0.10.1.1.tgz
c.修改配置:(暂时可不修改)
d.启动zookeeper:在kafka文件夹下操作命令
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties &
e.验证启动状态: jps,出现红色尖头部分表示启动成功

f.启动kafka
bin/kafka-server-start.sh -daemon config/server.properties &
g.验证kafka启动状态: jps

h.创建topic,名为slavetest
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic slavetest

i.topic为slavetest ,生产数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic slavetest

j.另打开一个终端连接操作,消费数据
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic slavetest --from-beginning
k.验证(Producer-Consumer)


l.End
4.分布式版安装步骤:
与单机版不同的是在于
注意事项
1.修改配置:config/server.properties
a.master节点上
broker.id=0 zookeeper.connect=master:2181
b.slave节点上
broker.id=1 zookeeper.connect=master:2181
2.slave不启动zk,可直接启动kafka
3.slave节点上开启消费命令时将localhost改为master
bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic slavetest --from-beginning
验证:
1.master 节点生产者
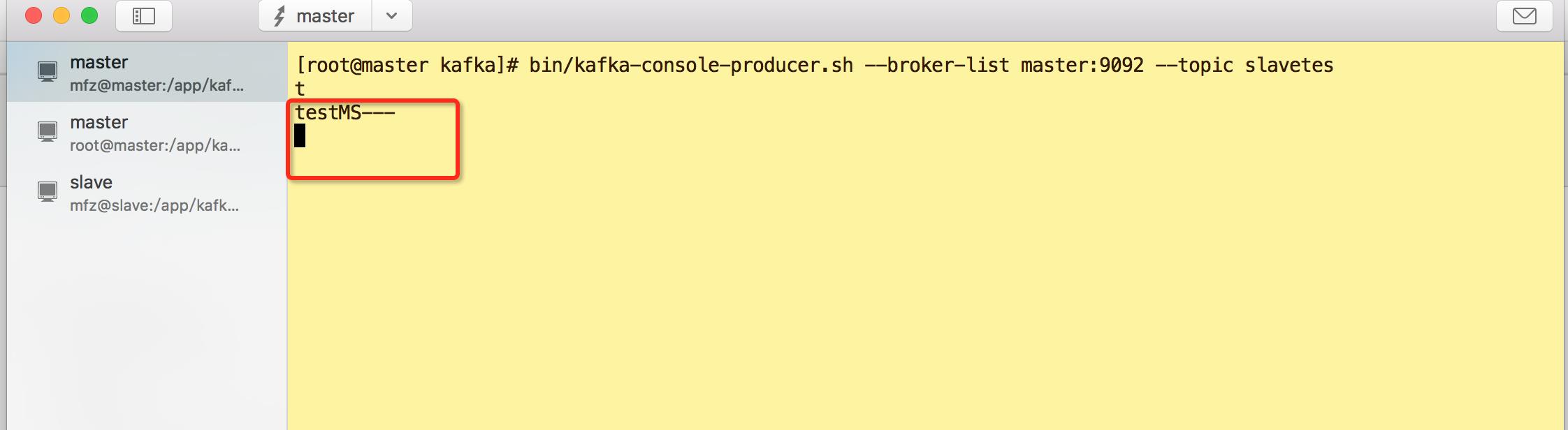
2.master节点上消费者

3.slave节点上消费者

以上是关于大数据系列之Kafka安装的主要内容,如果未能解决你的问题,请参考以下文章
Flink实战系列Flink 1.14.0 消费 kafka 数据自定义反序列化器
2021年大数据Kafka:❤️安装Kafka-Eagle❤️