2021年大数据Kafka:❤️安装Kafka-Eagle❤️
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Kafka:❤️安装Kafka-Eagle❤️相关的知识,希望对你有一定的参考价值。
全网最详细的大数据Kafka文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
2、将kafka_eagle上传,并解压到 /export/server 目录中
4、配置 kafka_eagle。使用vi打开conf目录下的system-config.properties
系列历史文章
2021年大数据Kafka(十二):❤️Kafka配额限速机制❤️
2021年大数据Kafka(十一):❤️Kafka的消费者负载均衡机制和数据积压问题❤️
2021年大数据Kafka(十):kafka生产者数据分发策略
2021年大数据Kafka(九):kafka消息存储及查询机制原理
2021年大数据Kafka(八):Kafka如何保证数据不丢失
2021年大数据Kafka(七):Kafka的分片和副本机制
2021年大数据Kafka(六):❤️安装Kafka-Eagle❤️
2021年大数据Kafka(五):❤️Kafka的java API编写❤️
2021年大数据Kafka(四):❤️kafka的shell命令使用❤️
2021年大数据Kafka(三):❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
2021年大数据Kafka(二):❤️Kafka特点总结和架构❤️
2021年大数据Kafka(一):❤️消息队列和Kafka的基本介绍❤️
安装Kafka-Eagle
一、Kafka-eagle基本介绍
二、开启Kafka JMX端口
JMX接口
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户可以在任何Java应用程序中使用这些代理和服务实现管理。很多的一些软件都提供了JMX接口,来实现一些管理、监控功能。
开启Kafka JMX
在启动Kafka的脚本前,添加:
cd $KAFKA_HOME
export JMX_PORT=9988
nohup bin/kafka-server-start.sh config/server.properties &三、安装Kafka-Eagle
1、安装JDK,并配置好JAVA_HOME
2、将kafka_eagle上传,并解压到 /export/server 目录中
cd /export/software/
tar -xvzf kafka-eagle-bin-1.4.6.tar.gz -C ../server/
cd /export/server/kafka-eagle-bin-1.4.6/
tar -xvzf kafka-eagle-web-1.4.6-bin.tar.gz
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.63、配置 kafka_eagle 环境变量
vim /etc/profileexport KE_HOME=/export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6
export PATH=$PATH:$KE_HOME/binsource /etc/profile4、配置 kafka_eagle。使用vi打开conf目录下的system-config.properties
vim conf/system-config.properties# 修改第4行,配置kafka集群别名
kafka.eagle.zk.cluster.alias=cluster1
# 修改第5行,配置ZK集群地址
cluster1.zk.list=node1:2181,node2:2181,node3:2181
# 注释第6行
#cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181
# 修改第32行,打开图标统计
kafka.eagle.metrics.charts=true
kafka.eagle.metrics.retain=30
# 注释第69行,取消sqlite数据库连接配置
#kafka.eagle.driver=org.sqlite.JDBC
#kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
#kafka.eagle.username=root
#kafka.eagle.password=www.kafka-eagle.org
# 修改第77行,开启mys
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://node1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=1234565、配置JAVA_HOME
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6/bin
vim ke.sh
# 在第24行添加JAVA_HOME环境配置
export JAVA_HOME=/export/server/jdk1.8.0_2416、修改Kafka eagle可执行权限
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6/bin
chmod +x ke.sh7、启动 kafka_eagle
./ke.sh start8、访问Kafka eagle
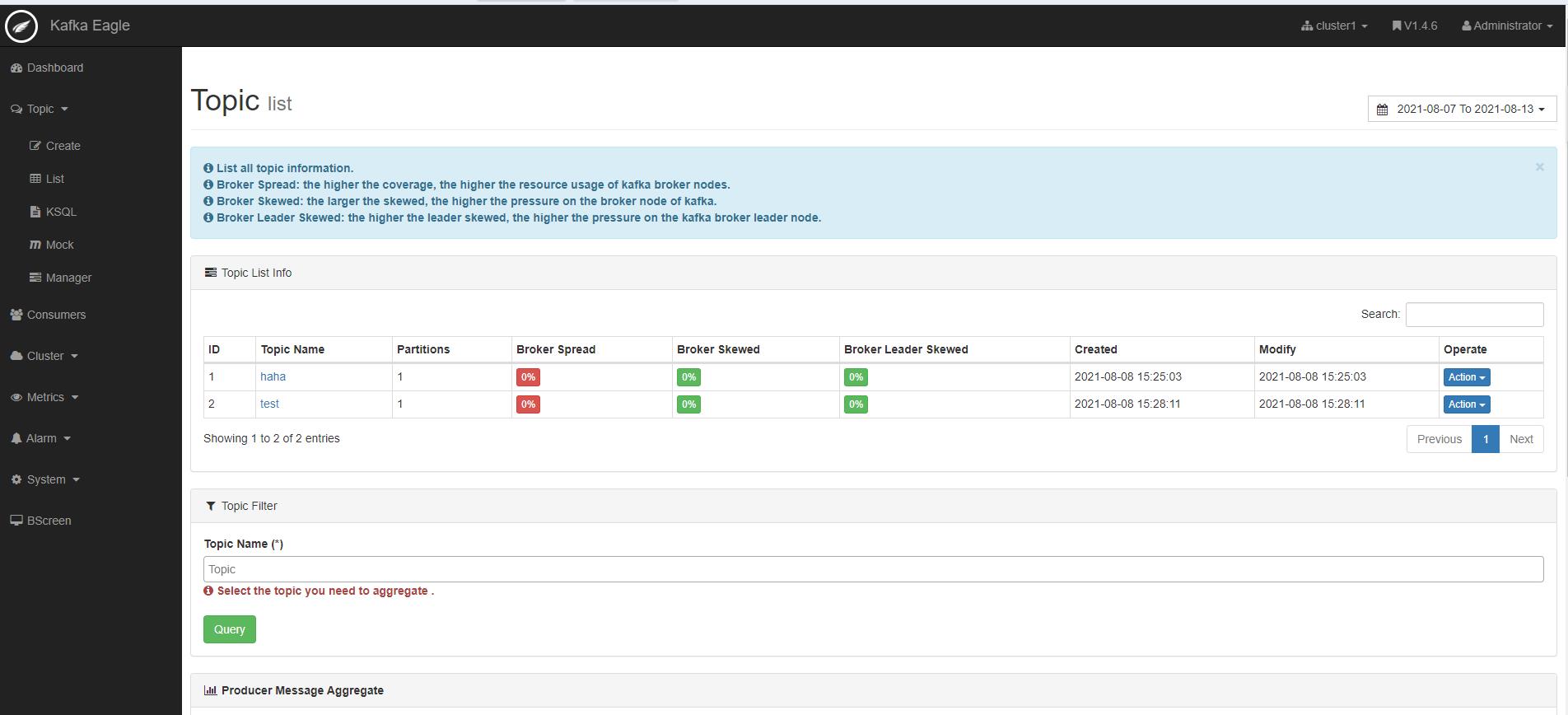
默认用户为admin,密码为:123456
http://node1:8048/ke


- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据Kafka:❤️安装Kafka-Eagle❤️的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Kafka:❤️Kafka特点总结和架构❤️
2021年大数据Kafka:❤️Kafka的集群搭建以及shell启动命令脚本编写❤️