2021年大数据Kafka:❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Kafka:❤️Kafka的集群搭建以及shell启动命令脚本编写❤️相关的知识,希望对你有一定的参考价值。
全网最详细的大数据Kafka文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
2、准备slave配置文件,用于保存要启动哪几个节点上的kafka
5、给start-kafka.sh、stop-kafka.sh配置执行权限
系列历史文章
2021年大数据Kafka(十二):❤️Kafka配额限速机制❤️
2021年大数据Kafka(十一):❤️Kafka的消费者负载均衡机制和数据积压问题❤️
2021年大数据Kafka(十):kafka生产者数据分发策略
2021年大数据Kafka(九):kafka消息存储及查询机制原理
2021年大数据Kafka(八):Kafka如何保证数据不丢失
2021年大数据Kafka(七):Kafka的分片和副本机制
2021年大数据Kafka(六):❤️安装Kafka-Eagle❤️
2021年大数据Kafka(五):❤️Kafka的java API编写❤️
2021年大数据Kafka(四):❤️kafka的shell命令使用❤️
2021年大数据Kafka(三):❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
2021年大数据Kafka(二):❤️Kafka特点总结和架构❤️
2021年大数据Kafka(一):❤️消息队列和Kafka的基本介绍❤️
Kafka的集群搭建以及shell启动命令脚本编写
一、搭建Kafka集群
1、 将Kafka的安装包上传到虚拟机,并解压
cd /export/software/
tar -xvzf kafka_2.12-2.4.1.tgz -C ../server/
cd /export/server/kafka_2.12-2.4.1/2、修改 server.properties
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
# 指定broker的id
broker.id=0
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node1:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka_2.12-2.4.1/data
# 配置zk的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:21813、将安装好的kafka复制到另外两台服务器
cd /export/server
scp -r kafka_2.12-2.4.1/ node2:$PWD
scp -r kafka_2.12-2.4.1/ node3:$PWD
修改另外两个节点的broker.id分别为1和2
---------node2--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=1
listeners=PLAINTEXT://node2:9092
--------node3--------------
cd /export/server/kafka_2.12-2.4.1/config
vim server.properties
broker.id=2
listeners=PLAINTEXT://node3:90924、配置KAFKA_HOME环境变量
vim /etc/profile
export KAFKA_HOME=/export/server/kafka_2.12-2.4.1
export PATH=:$PATH:$KAFKA_HOME
分发到各个节点
scp /etc/profile node2:$PWD
scp /etc/profile node3:$PWD
每个节点加载环境变量
source /etc/profile5、启动服务器
# 启动ZooKeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
# 启动Kafka
cd /export/server/kafka_2.12-2.4.1
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
# 测试Kafka集群是否启动成功 :
使用 jps 查看各个节点 是否出现有kafka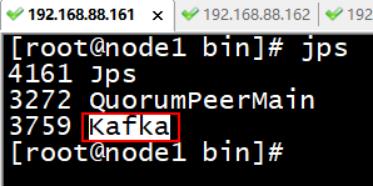
或者通过 zookeeper查看 brokers节点目录下, 是否有三个ids
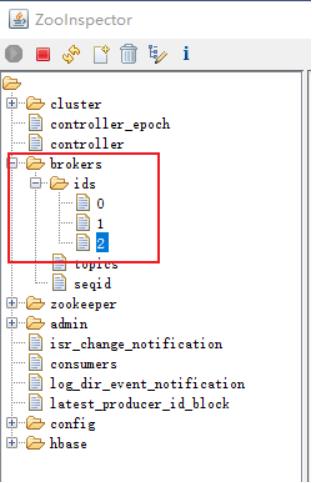
二、目录结构分析
| 目录名称 | 说明 |
| bin | Kafka的所有执行脚本都在这里。例如:启动Kafka服务器、创建Topic、生产者、消费者程序等等 |
| config | Kafka的所有配置文件 |
| libs | 运行Kafka所需要的所有JAR包 |
| logs | Kafka的所有日志文件,如果Kafka出现一些问题,需要到该目录中去查看异常信息 |
| site-docs | Kafka的网站帮助文件 |
三、Kafka一键启动/关闭脚本
为了方便将来进行一键启动、关闭Kafka,我们可以编写一个shell脚本来操作。将来只要执行一次该脚本就可以快速启动/关闭Kafka。
1、在节点1中创建 /export/onekey 目录
cd /export/onekey2、准备slave配置文件,用于保存要启动哪几个节点上的kafka
node1
node2
node33、编写start-kafka.sh脚本
vim start-kafka.sh
cat /export/onekey/slave | while read line
do
echo $line
ssh $line "source /etc/profile;export JMX_PORT=9988;nohup $KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties >/dev/nul* 2>&1 & "
&
wait
done4、编写stop-kafka.sh脚本
vim stop-kafka.sh
cat /export/onekey/slave | while read line
do
echo $line
ssh $line "source /etc/profile;jps |grep Kafka |cut -d' ' -f1 |xargs kill -s 9"
&
wait
done5、给start-kafka.sh、stop-kafka.sh配置执行权限
chmod u+x start-kafka.sh
chmod u+x stop-kafka.sh6、执行一键启动、一键关闭
./start-kafka.sh
./stop-kafka.sh- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据Kafka:❤️Kafka的集群搭建以及shell启动命令脚本编写❤️的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Kafka:❤️Kafka特点总结和架构❤️