机器学习One-Hot编码
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习One-Hot编码相关的知识,希望对你有一定的参考价值。
目录
1 什么是One-Hot编码 ?
在计算机科学中,数据可以用很多不同的方式表示,自然而然地,每一种方式在某些领域都有其优点和缺点。
由于计算机无法处理分类数据,因为这些类别对它们没有意义,如果我们希望计算机能够处理这些信息,就必须准备好这些信息。
此操作称为预处理。 预处理的很大一部分是编码 - 以计算机可以理解的方式表示每条数据(该名称的字面意思是“转换为计算机代码”)。
在计算机科学的许多分支中,尤其是机器学习和数字电路设计中,One-Hot Encoding 被广泛使用。
在本文中,我们将解释什么是 one-hot 编码,并使用一些流行的选择(Pandas 和 Scikit-Learn)在 Python 中实现它。 我们还将比较它与计算机中其他类型表示的有效性、优点和缺点,以及它的应用。
One-hot Encoding 是一种向量表示,其中向量中的所有元素都是 0,除了一个,它的值是 1,其中 1 表示指定元素类别的布尔值。
还有一个类似的实现,称为One-Cold Encoding,其中向量中的所有元素都是 1,除了 1 的值是 0。
例如,[0, 0, 0, 1, 0] 和 [1 ,0, 0, 0, 0] 可以是One-hot 向量的一些示例。 与此类似的技术,也用于表示数据,例如统计中的虚拟变量。
这与其他编码方案非常不同,其他编码方案都允许多个位的值为 1。 下表比较了从 0 到 7 的数字在二进制、格雷码和 one-hot 中的表示:
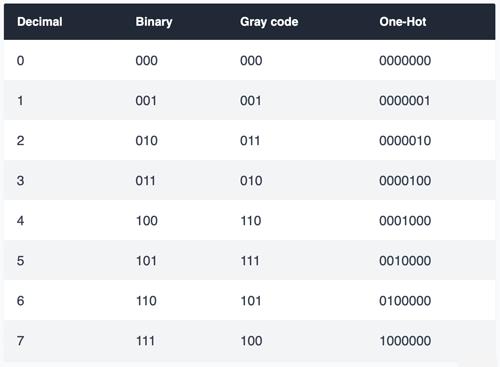
实际上,对于每个 one-hot 向量,我们会问 n 个问题,其中 n 是我们拥有的类别数:
这是数字1吗? 这是数字2吗? …这是数字7吗?
每个“0”都是“假”,一旦我们在向量中找到“1”,问题的答案就是“真”。
One-hot 编码将分类特征转换为一种更适合分类和回归算法的格式。 它在需要多种类型数据表示的方法中非常有用。
2 One-Hot编码示例
下面将会通过一些实际的例子来说明一下,对于上面的解释,其实 One-Hot 编码 也可称为 One of N encoding
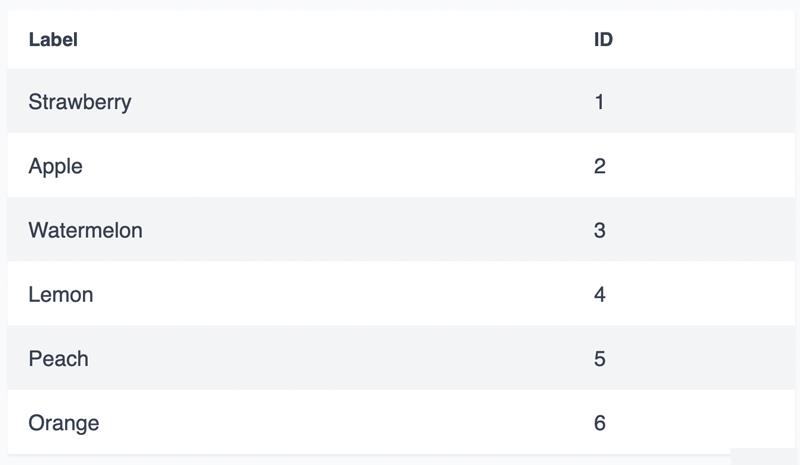
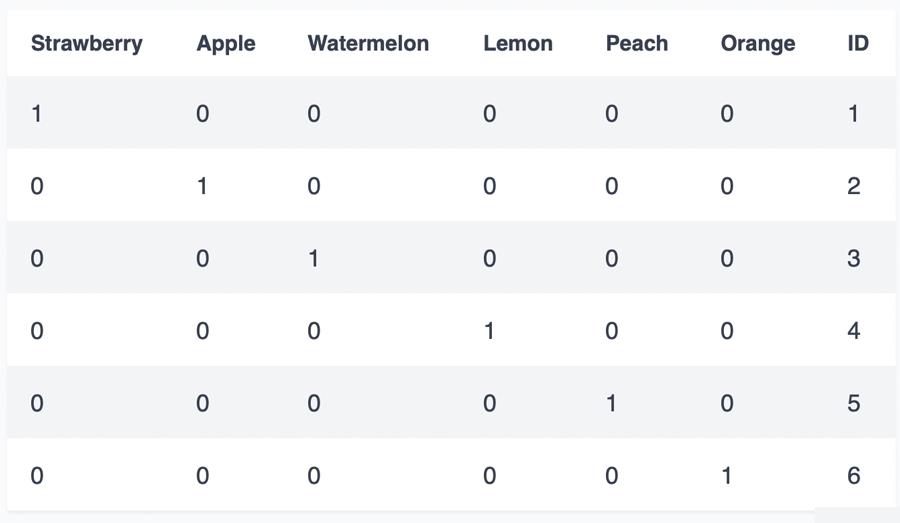
我们可以从上表中看出,与二进制或格雷码相比,one-hot 表示需要更多的数字。 对于n个数字,one-hot编码只能表示n个值,而Binary或Gray编码可以用n个数字表示2n个值。
- 假设对于学生的性别【男,女】进行编码
根据上面的官方概念,采用 N 位状态寄存器对 N 个状态进行编码,这里的特征有2个,也就是 N = 2,所以可以有下面的表示方式:
男 → rightarrow→ [1, 0] ;
女 → rightarrow→ [0, 1] ; - 假设对于学生的年级【小学,初中,高中】进行编码
如上,可以有如下表示:
小学 → rightarrow→ [1, 0, 0] ;
初中 → rightarrow→ [0, 1, 0] ;
高中 → rightarrow→ [0, 0, 1] ; - 假设对于学生的特长【钢琴,绘画,舞蹈,篮球】进行编码
如上,可以有如下表示:
钢琴 → rightarrow→ [1, 0, 0, 0,] ;
绘画 → rightarrow→ [0, 1, 0, 0] ;
舞蹈 → rightarrow→ [0, 0, 1, 0] ;
篮球 → rightarrow→ [0, 0, 0, 1] ;
那么,如果是这样的一个样本 【男,初中,篮球】,就可以这么表示:[1, 0, 0, 1, 0, 0, 0, 0, 1] 。
3 sklearn中的OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
# 模拟的训练数据
X = [[0, 0, 2],
[1, 2, 3],
[1, 1, 0],
[0, 0, 1]
]
enc = OneHotEncoder(sparse=False)
enc.fit(X)
# 测试数据
x_test = [[1, 0, 2]]
result = enc.transform(x_test)
print(result)
输出结果:
[[0. 1. 1. 0. 0. 0. 0. 1. 0.]]
上述代码中的有4个训练数据,特征数为3,对应上边的例子,训练数据的第一列都为 0 1 1 0,即对应学生的性别特征【男,女】;第二列 0 2 1 0 正好对应年级特征 【小学,初中,高中】;第三列 2 3 0 1 则正好对应特长这一特征【钢琴,绘画,舞蹈,篮球】;训练数据1:0, 0, 2 表示【男,小学,舞蹈】,其余类似;测试数据 1, 0, 2 表示【女,小学,舞蹈】,我们根据 2 中的示例,可以计算出 One-Hot 编码为:[0, 1, 1, 0, 0, 0, 0, 1, 0],跟代码运行出的编码也是一致的。
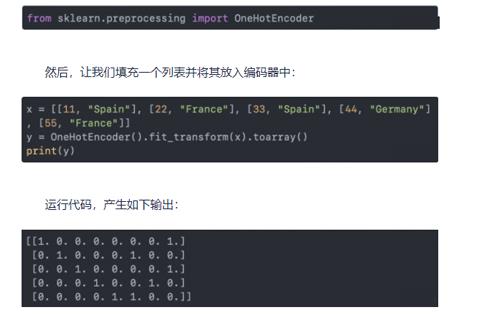
4 One-hot编码在机器学习领域的应用
如上所述,计算机不太擅长处理分类数据。 虽然我们很好地理解分类数据,但这是由于计算机不具备的一种先决知识。
大多数机器学习技术和模型使用非常有限的数据集(通常是二进制)。 神经网络消耗数据并产生 0…1 范围内的结果,我们很少会超出该范围。
简而言之,绝大多数机器学习算法都会接收样本数据(“训练数据”),从中提取特征。 基于这些特征,创建了一个数学模型,然后用于进行预测或决策,而无需明确编程来执行这些任务。
一个很好的例子是分类,其中输入在技术上可以是无界的,但输出通常仅限于几个类别。 在二元分类的情况下(假设我们正在教一个神经网络对猫和狗进行分类),我们的映射为 0 代表猫,1 代表狗。
大多数情况下,我们希望对其进行预测的训练数据是分类的,就像上面提到的带有水果的例子一样。 同样,虽然这对我们很有意义,但这些词本身对算法没有意义,因为它不理解它们。
在这些算法中使用one-hot编码来表示数据在技术上不是必需的,但如果我们想要一个有效的实现,它非常有用.
以上是关于机器学习One-Hot编码的主要内容,如果未能解决你的问题,请参考以下文章
独热编码(One-Hot Encoding)和 LabelEncoder标签编码 区别 数据预处理:(机器学习) sklearn
机器学习入门-数据预处理-数字映射和one-hot编码 1.LabelEncoder(进行数据自编码) 2.map(进行字典的数字编码映射) 3.OnehotEncoder(进行one-hot编码)