数据项目总结 - 租房数据分析(完整篇)
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据项目总结 - 租房数据分析(完整篇)相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:皮钱超,厦门大学,Datawhale成员
深圳租房数据分析完整篇
从2020年11月发表第一篇深圳租房数据分析的文章,到这篇基于深度学习框架Keras的建模分析和预测,在此谈谈3篇文章的特点:
1、第一篇:
写于2020年11月,笔者作为一名数据分析师,学习了Python、SQL、爬虫、可视化以及部分机器学习的常见算法和模型,所以在第一篇文章中的重点是:统计与可视化分析。看过文章的小伙伴应该都知道,里面出现了许多还算漂亮的可视化图表(下面是部分图)。
一图胜千言,从统计和可视化图表的角度能够很快速且直观地看到数据分布和变化趋势。文章中使用可视化库是Plotly,一个非常棒的动态可视化库,强烈推荐学习~

文章地址:
https://mp.weixin.qq.com/s/DEsclUfdnmVqICiK5rM57Q
2、第二篇:
写于2022年3月,笔者仍然是一名数据分析师。从2020年末到2022年初,一年左右的时间,笔者接触和学习了更多的是机器学习的算法、特征工程以及模型的可解释性等知识点。
在这篇文章中,笔者花费了大量的工作来做10个字段的预处理和特征工程工作,重点是如何做编码处理,便于后续输入到不同的回归模型中,以及各种模型的对比。
最后,笔者对模型的可解释性进行了探索,主要基于目前一个流行的可解释库:SHAP。
SHAP将所有的特征都视为“贡献者”。 对于每个预测样本,模型都产生一个对应的预测值,SHAP value就是该样本中每个特征所分配到的数值
关于特征工程的学习,笔者推荐一本书:《特征工程入门与实践》。

文章地址:
https://mp.weixin.qq.com/s/iO47yo6IgYgw6xZ8W-8lbQ
3、第三篇(本篇)
写第3篇(也就是看到的这篇)的时候,笔者依旧是一名数据分析师。今年的学习重点转移到了深度学习和kaggle比赛,最近一段时间学习一些DL的基础和Keras框架对于分类和回归问题的建模,从网络模型搭建、编译、训练网络等步骤完成整个建模的基本过程。
DL的建模过程后面深入学习了之后,会对现有的模型进行下一步的优化!

写在最后:3篇文章仅代表了笔者的一些学习经历和知识总结,关于文章的具体细节部分,如果大家有认为有更好的处理方式或者不恰当的地方,欢迎指出来一起学习讨论~
Datawhale后台回复 深圳 可下载租房数据
本文是针对深圳租房数据的第3次分析,主要包含数据预处理、采样处理、基于Keras的建模等:

导入库
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import matplotlib.pyplot as plt
import seaborn as sns
# plt.style.use("fivethirtyeight")
plt.style.use('ggplot')
import sklearn.preprocessing as pre_processing
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import tensorflow as tf
from keras import models
from keras import layers
np.random.seed(123)
pd.options.mode.chained_assignment = None数据基本信息
读取数据
df = pd.read_excel("leyoujia.xls")
df.head()
数据shape
In [3]:
# 数据形状
df.shapeOut[3]:
(2020, 12)数据shape返回的是一个列表,第一个取值表示数据的行数,第二个是属性个数,即字段的多少
字段类型
In [4]:
# 数据的字段类型
df.dtypesOut[4]:
大部分都是字符串类型,只有money,就是最终的预测值是数值型
name object
layout object
location object
size object
sizeInside object
zhuangxiu object
numberFloor object
time object
zone object
position object
money int64
way object
dtype: objectIn [5]:
# 数据中的缺失值
df.isnull().sum()Out[5]:
name 0
layout 0
location 0
size 0
sizeInside 0
zhuangxiu 0
numberFloor 0
time 6 # 缺失值
zone 0
position 0
money 0
way 0
dtype: int64缺失值处理
找出缺失值
在time字段中存在缺失值,找出缺失值所在的行数据信息:

填充缺失值
缺失值的填充有多种方法:
填充具体值
填充现有数据的某个统计值,比如均值、众数等
填充前后项的值等
本文直接在网上找到每个小区的具体时间进行填充:
In [7]:
# 2019 2003 2004 2019 2019 2020
times = ["2019年", "2003年", "2004年", "2019年", "2019年", "2020年"]
# 通过对应的索引位置来填充缺失值
for i in range(len(df0)):
df.iloc[df0.index.tolist()[i], 7] = times[i]In [8]:
df.isnull().sum()Out[8]:
填充之后发现没有缺失值:
name 0
layout 0
location 0
size 0
sizeInside 0
zhuangxiu 0
numberFloor 0
time 0
zone 0
position 0
money 0
way 0
dtype: int64预处理
下面的内容是针对不同的字段做预处理,包含丰富的特征工程工作
name
小区的姓名name对我们建模是没有任何帮助,考虑直接删除
In [9]:
df.drop("name",axis=1,inplace=True) # inplace=True表示原地修改layout
layout分成3个具体的属性:室、厅、卫;当layout为"商铺"时,直接删除该部分数据
In [10]:
df[df["layout"] == "商铺"]
提取出几室几厅几卫:在这里我们使用的是Pandas中的extract函数
df1 = df["layout"].str.extract(r'(?P<shi>\\d)室(?P<ting>\\d)厅(?P<wei>\\d)卫')
df1.head()
# 合并到原数据
df = pd.concat([df1,df],axis=1)
# 原地删除原字段layout
df.drop("layout",axis=1,inplace=True)
删除3个字段中的空值:
# 基于3个字段删除空值
df.dropna(subset=["shi","ting","wei"],inplace=True)
df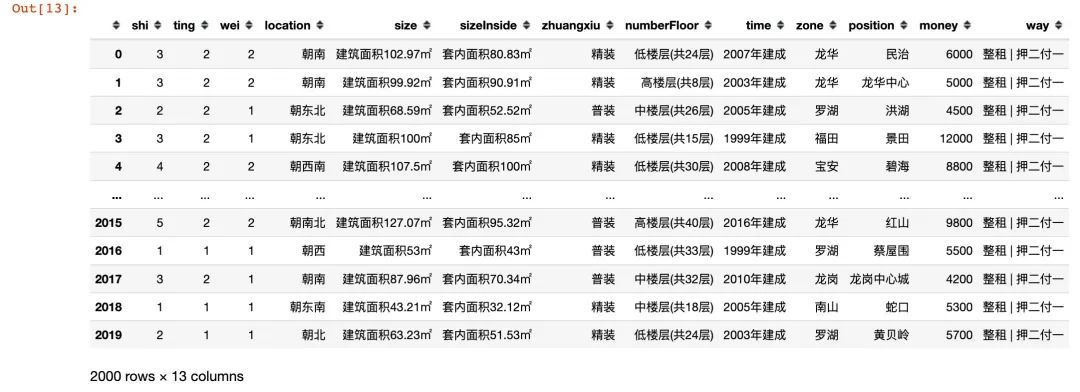
location
统计每个location下面出现的数量:
In [14]:
df["location"].value_counts()Out[14]:
朝南 552
朝南北 284
朝东南 241
朝北 241
朝西南 174
朝西北 142
朝东北 140
朝东 132
朝西 92
朝东西 2
Name: location, dtype: int64In [15]:
不同朝向下租金的价格分布:
fig = px.violin(df,y="money",color="location")
fig.show()
按照常识,房子在南北朝向的时候价格比东西朝向会更贵。在这里我们取每个朝向下的最大值:
# 不同朝向下的均值:
price = (df.groupby("location")["money"].max()
.reset_index()
.sort_values("money")
.reset_index(drop=True))
price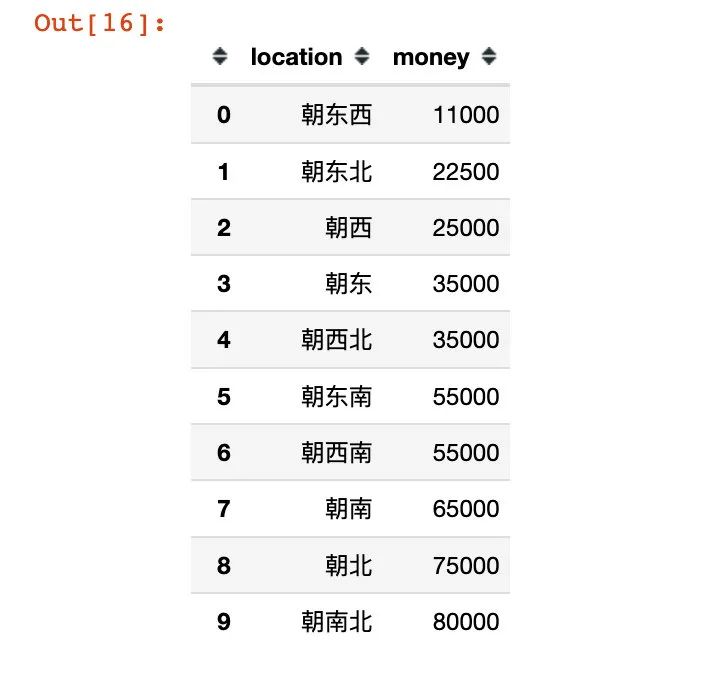
注意:然后根据朝向的索引号大小进行编码:朝东西-0;朝东北-1;朝南北-9
这点是和第二次分析中不同的点。第二次分析根据价格分布的小提琴图自定义的编码顺序
# 第二弹中编码自定义:location = ["朝东西","朝东北","朝西","朝西北","朝东","朝西南","朝东南","朝南","朝北","朝南北"]
location = price["location"].tolist()
location_dict =
for n, i in enumerate(location):
location_dict[i] = n+1 # 编码从1开始
df["location"] = df["location"].map(location_dict)
df.head()
size和sizeInside
建筑面积和套内面积的处理:从原数据中提取出数字和小数点部分。提供两种方法
In [18]:
df.dtypesOut[18]:
shi object
ting object
wei object
location int64
size object
sizeInside object
zhuangxiu object
numberFloor object
time object
zone object
position object
money int64
way object
dtype: objectIn [19]:
# 1、通过切割的方式来提取
df["size"] = df["size"].apply(lambda x: x.split("面积")[1].split("㎡")[0])
df.head()
# 2、使用正则的方式提取
df["sizeInside"] = df["sizeInside"].str.extract(r'面积(?P<sizeInside>[\\d.]+)')
df.head()
zhuangxiu
装修方式的不同通过自定义的硬编码。
In [21]:
df["zhuangxiu"].value_counts()Out[21]:
精装 1172
普装 747
豪装 62
毛坯 19
Name: zhuangxiu, dtype: int64主观意义上的思路:毛坯的等级最低,豪装最高,所以在这里直接采用自定义的硬编码方式:
In [22]:
# 硬编码
zhuangxiu = "毛坯":1,"普装":2, "精装":3, "豪装":4
zhuangxiuOut[22]:
'毛坯': 1, '普装': 2, '精装': 3, '豪装': 4In [23]:
df["zhuangxiu"] = df["zhuangxiu"].map(zhuangxiu)numberFloor
楼层的高低对价格的影响也是挺大的。下面分析中低高楼层和价格money之间的关系:
In [24]:
# 提取中低高楼层
df["numberFloor"] = df["numberFloor"].apply(lambda x: x.split("(")[0])
df.head()
# 中低高楼层和价格money之间的关系
fig = px.violin(df,y="money",color="numberFloor")
fig.show()
采用独热码的形式进行编码:通过get_dummie函数来实现
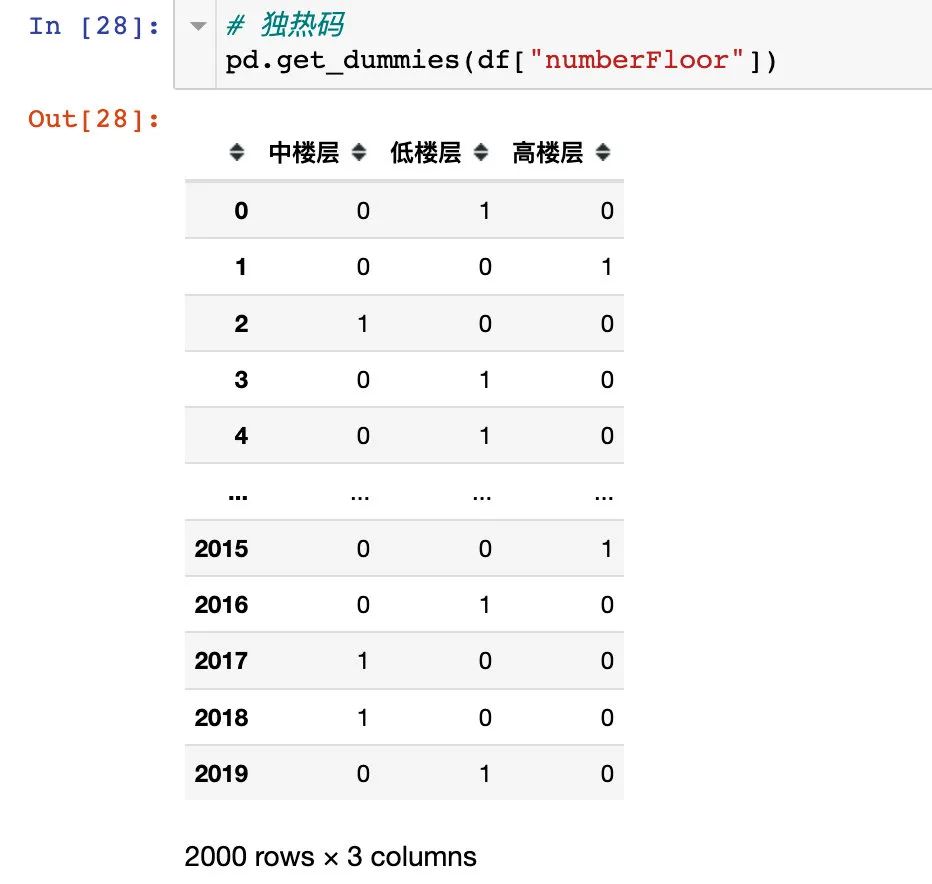
# 中高低楼层采用独热码的形式
df = (df.join(pd.get_dummies(df["numberFloor"]))
.rename(columns="中楼层":"middleFloor",
"低楼层":"lowFloor",
"高楼层":"highFloor"))
df.drop("numberFloor", axis=1, inplace=True)
df.head()
time
小区房子的建成时间处理:
In [30]:
df["time"].value_counts()
# 部分结果
2003年建成 133 # 数量
2005年建成 120
2006年建成 114
2004年建成 111
2010年建成 104
2007年建成 101
2016年建成 94
2008年建成 92
2002年建成 79
2015年建成 78从原数据中提取出具体的年份信息:

转成数值型,并且求出和2022年的时间间隔:
# time转成数值型
df["time"] = df["time"].astype("float")
# 建成时间和当前年份的时间间隔
df["time"] = 2022 - df["time"]
df.head()
zone+position
行政区域和具体的位置对价格的影响
In [33]:
df["zone"].value_counts()Out[33]:
龙岗 548
福田 532
龙华 293
南山 218
宝安 173
罗湖 167
光明 32
坪山 31
盐田 5
大鹏新区 1
Name: zone, dtype: int64In [34]:
fig = px.violin(df,y="money",color="zone")
fig.show()
将zone和position进行合并,并且计算每个具体位置下的价格均值,根据均值的大小进行编码:
df["zone_position"] = df["zone"] + "_" + df["position"]
zone_position_mean = (df.groupby("zone_position")["money"].mean()
.reset_index()
.sort_values("money",ascending=True,ignore_index=True)) # 升序排列
zone_position_mean
zone_position = zone_position_mean["zone_position"].tolist()
zone_position_dict =
for n, i in enumerate(zone_position):
zone_position_dict[i] = n+1
df["zone_position"] = df["zone_position"].map(zone_position_dict)
df.drop(["zone","position"],axis=1,inplace=True) # 原地删除
df.head()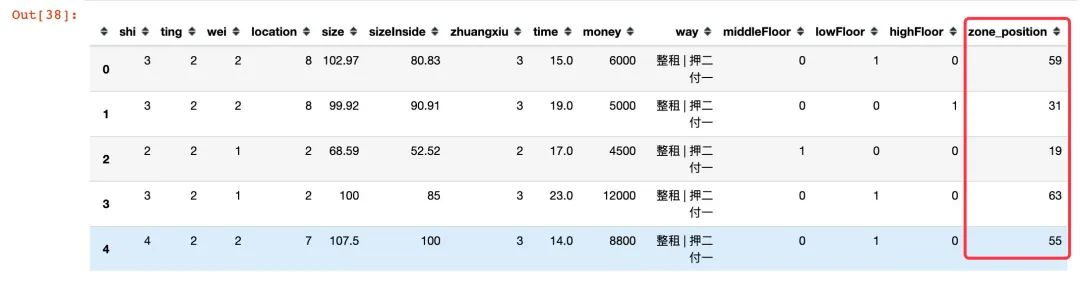
way
不同的租房方式,在这里只提取两个信息:整租与合租
In [39]:
fig = px.violin(df,y="money",color="way")
fig.show()不同租房方式对价格的影响:很明显押一付一和押二付一是最常见的方式

提取整租和合租,并实施类型编码:
# 整租-合租
df["way"] = df["way"].apply(lambda x: x.split(" ")[0])
df["way"] = df["way"].map("整租":1,"合租":0)
df["way"].value_counts() # 1-整租 0-合租
我们发现:绝大部分的都是整租,极少数是合租。这两类样本是不均衡的,后面会实施采样处理。
采样处理
上面提到整租与合租的样本数是极不均衡的,在这里实施上采样,增加合租的数量,保证二者相同:
采样前:

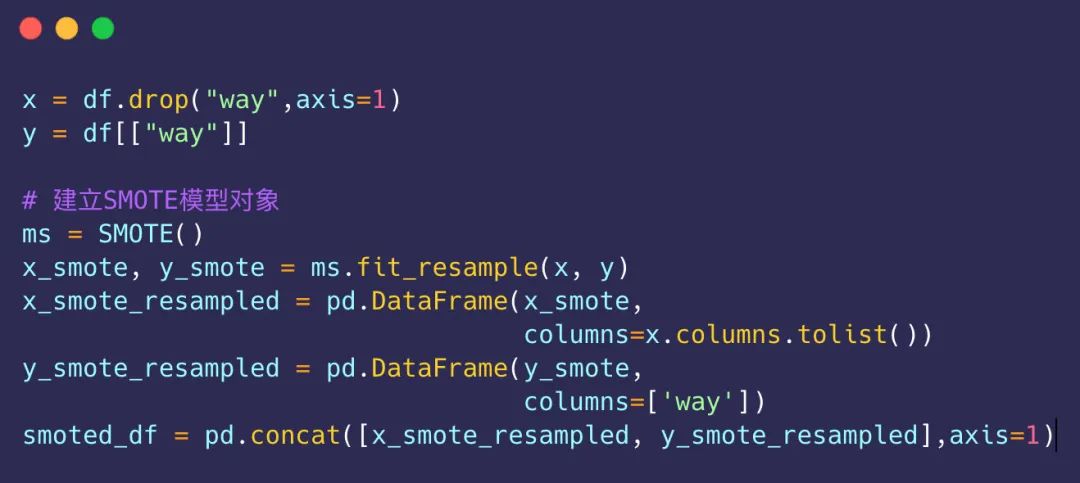
采样后:

类型转换
上面对不同字段进行了预处理和编码,发现有些字段的类型需要转换:

col1 = ["shi","ting","wei","time"]
for i in col1:
smoted_df[i] = smoted_df[i].apply(lambda x: round(x))
col2 = ["size", "sizeInside"]
for i in col2:
smoted_df[i] = smoted_df[i].astype(float)全部变成了数值型:

建模
下面是对数据smoted_df数据进行建模:
特征和标签
X = smoted_df.drop("money",axis=1) # 特征
y = smoted_df["money"] # 标签切分数据
from sklearn.model_selection import train_test_split
# 8-2的比例
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=44)数据标准化
mean = X_train.mean(axis=0)
X_train -= mean
std = X_train.std(axis=0)
X_train /= std
# 测试集:使用训练集的均值和标准差来归一化
X_test -= mean
X_test /= std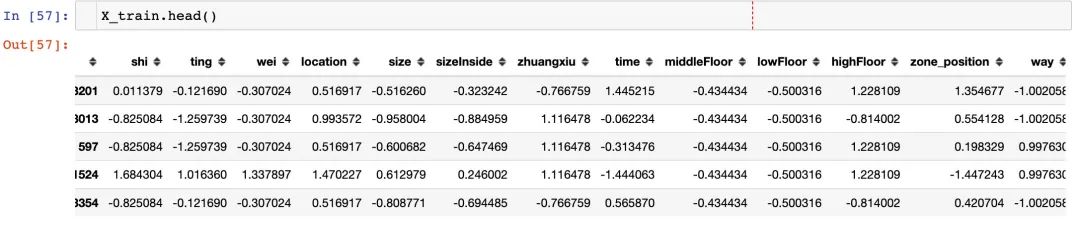
一般神经网路中的数据都要求比较小,在这里对同因变量统一转成以万为单位的数据:
In [58]:
y_train = y_train / 10000
y_test = y_test / 10000
y_train[:5]Out[58]:
3201 0.6000
3013 0.2154
597 0.5000
1524 0.4300
3354 0.1737
Name: money, dtype: float64构建网络
训练集的样本总共是3000+,我们在这里采用了一个很小的网络,只有两个隐藏层,每层64个单元。
网络的最后一层只有一个单元,没有其他激活函数,是一个比较纯粹的线性层。
In [59]:
model = models.Sequential()
model.add(tf.keras.layers.Dense(64,
activation="relu",
input_shape=(X_train.shape[1],)))
model.add(tf.keras.layers.Dense(64,
activation="relu"))
model.add(tf.keras.layers.Dense(1))编译网络
在这个建模中,损失函数loss采用的是mse:均方误差mean squared error,预测值和目标实际值的差的平方,
监控的指标为mae:平均绝对误差mean absolute error,表示的是预测值和目标实际值之差的绝对值,
In [60]:
model.compile(optimizer="rmsprop", # 优化器
loss="mse", # 损失函数
metrics=["mae"] # 评估指标:平均绝对误差
)网络架构
查看整个网络的基本架构
In [61]:

训练网络
引入5折交叉验证:从训练数据集中划分出一定的验证数据集
In [62]:
k = 5
number_val = len(X_train) // k # 验证数据集的大小
number_epochs = 20
all_mae_scores = []
all_loss_scores = []
for i in range(k):
# 只取i到i+1部分作为验证集
vali_X = X_train[i * number_val: (i+1) * number_val]
vali_y = y_train[i * number_val: (i+1)*number_val]
# 训练集
part_X_train = np.concatenate([X_train[:i * number_val],
X_train[(i+1) * number_val:]],
axis=0
)
part_y_train = np.concatenate([y_train[:i * number_val],
y_train[(i+1) * number_val:]],
axis=0
)
# 模型训练
history = model.fit(part_X_train,
part_y_train,
epochs=number_epochs
# 传入验证集的数据
validation_data=(vali_X, vali_y),
batch_size=300,
verbose=0 # 0-静默模式 1-日志模式
)
mae_history = history.history["mae"]
loss_history = history.history["loss"]
all_mae_scores.append(mae_history)
all_loss_scores.append(loss_history)网络指标
# 每个轮次中的平均值
average_mae = [np.mean([x[i] for x in all_mae_scores]) for i in range(number_epochs)]
average_loss = [np.mean([x[i] for x in all_loss_scores]) for i in range(number_epochs)]
# 每个轮次(20轮)的均值
average_mae
# 结果
[0.14793895035982133,
0.12548727840185164,
0.1141199067234993,
0.1111918956041336,
0.10730082243680954,
0.10863531827926635,
0.10383812189102173,
0.10521284639835357,
0.10574782490730286,
0.10005746781826019,
0.10514769405126571,
0.10096234679222107,
0.10278342366218567,
0.0960465505719185,
0.10629244297742843,
0.09704757779836655,
0.09838753342628478,
0.10160793513059616,
0.0998133972287178,
0.09991184771060943]loss和mae的整体均值如下:
# 整体均值
print("mae的均值:",np.mean(average_mae))
print("loss的均值:",np.mean(average_loss))
mae的均值: 0.1068765591084957
loss的均值: 0.058070002682507026mae 约为0.1,表示预测值和实际值的相差约为1000元(单位为万)
模型评估
通过evaluate函数对模型进行评估,传入测试集中的数据:
In [65]:
model.evaluate(X_test, y_test)
25/25 [==============================] - 0s 3ms/step - loss: 0.0696 - mae: 0.1295Out[65]:
[0.06960742175579071, 0.12945905327796936]可以看到loss的取值0.0696,mae取值约为0.1295,表示预测值和实际值之间相差0.1295万元,大约1295元
loss-mae可视化
# 损失绘图
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = average_loss
mae_values = average_mae
epochs = range(1,len(loss_values) + 1)
plt.plot(epochs, # 循环轮数
loss_values, # loss取值
"r",
label="loss"
)
plt.plot(epochs,
mae_values,
"b",
label="mae"
)
plt.title("Loss and Mae")
plt.xlabel("Epochs")
plt.legend()
plt.show()
引入正则
主要是两个方面:添加L1或者L2正则项、添加Dropout层和实施早停EarlyStopping策略。
本文中采用引入L2正则项:

mae的均值: 0.11811128027737142
loss的均值: 0.07401402860879899新生成的loss-mae可视化:
# 损失绘图
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = average_loss
mae_values = average_mae
epochs = range(1,len(loss_values) + 1)
# 训练
plt.plot(epochs, # 循环轮数
loss_values,
"r", # 红色
label="loss"
)
plt.plot(epochs,
mae_values,
"b",
label="mae"
)
plt.title("Loss and Mae")
plt.xlabel("Epochs")
plt.legend()
plt.show()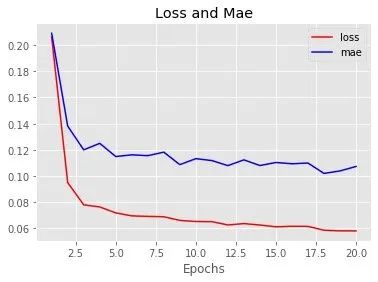
重新预测
In [69]:
model.evaluate(X_test, y_test)
25/25 [==============================] - 0s 3ms/step - loss: 0.0634 - mae: 0.1101Out[69]:
[0.06338492780923843, 0.110066257417202]
# 优化前 [0.06960742175579071, 0.12945905327796936]在引入正则项之后,模型得到优化:loss和mae都有一定的下降。mae变成了0.11,预测值和真实值相差约1100元。
小结
本文从一份网络爬取的租房数据出发,从数据基本信息探索、缺失值处理、特征工程、样本不均衡处理、基于Keras的深度学习模型搭建以及优化等多个步骤进行建模分析,完成了对租房数据价格的预测分析,并且最终的误差控制在了1100元左右。
在对模型添加了正则项之后,模型的loss和mae都得到了一定的优化~
总结
在写3篇文章的总结内容之前先贴上爬虫的代码,只需要修改请求头即可运行:
1、爬虫代码
下面提供两种不同方式的租房数据爬虫源码:
import pandas as pd
import numpy as np
import json
from lxml import etree
import requests
import xlwt
import re
import time1、基于xpath的爬虫代码(全网爬取100页)
笔者近期再次调试可以直接运行

2、基于正则解析的爬取(单页爬取并解析)
最近笔者又用正则表达式进行了字段的解析:
import pandas as pd
import numpy as np
import requests
import re
url = "https://shenzhen.leyoujia.com/zf/?n=1"
headers = "User-Agent": "个人请求头" # 更换请求头即可
# 返回的是解析内容
response = requests.get(url=url, headers=headers).content.decode('utf-8', 'ignore')解析不同的字段

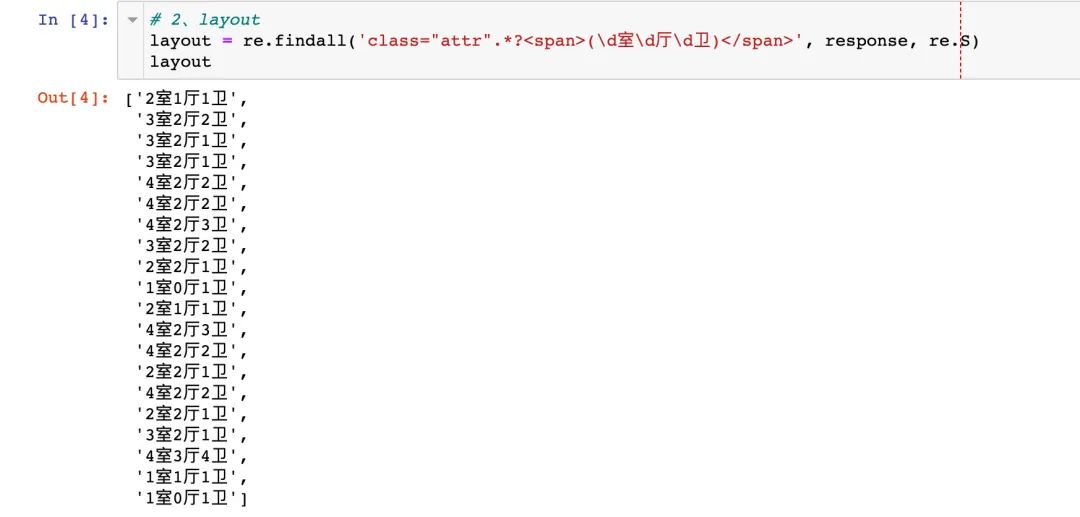

其他字段的正则解析表达式:


整理不易,点赞三连↓
以上是关于数据项目总结 - 租房数据分析(完整篇)的主要内容,如果未能解决你的问题,请参考以下文章