理论基础
Posted 一颗令人操心的vegetable
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理论基础相关的知识,希望对你有一定的参考价值。
目录
数据科学的学科地位
从学科定位上看,数据科学处于三大领域交叠之处,如下维恩图所示:
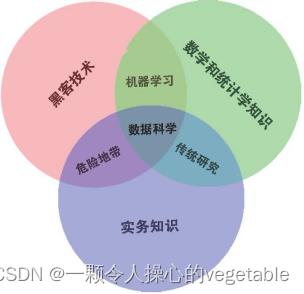
从DrewConway的《数据科学维恩图》的中心部分可看出,数据科学位于统计学、机器学和某一领域知识的交叉之处,具备较为显著的交叉型学科的特点,即数据科学是一门以统计学、机器学习和领域知识为理论基础的新兴学科。同时,从该图的外围可看出,数据科学家需要具备数学与统计学知识、领域实战和黑客精神,说明数据科学不仅需要理论知识和实践经验,而且还涉及黑客精神,即数据科学具有三个基本要素:理论(数学与统计学)、实践(领域实务)和精神(黑客精神)。
(1)数学与统计知识”是数据科学的主要理论基础之一,数据科学与(传统)数学和统计学有所区别。
(2)黑客精神与技能”是数据科学家的主要精神追求和技能要求——大胆创新、喜欢挑战、追求完美和不断改进。
(3)“领域实务知识”是对数据科学家的特殊要求,具有显著的面向领域性,不同的领域其领域实务知识不同。
统计学
统计学与数据科学
统计学是数据科学的主要理论之一。数据科学的理论、方法、技术、和工具往往来源于统计学。
数据科学中常用的统计学知识
1.从行为目的与思维方式看,数据统计方法可以分为两大类---描述统计和推断统计。如下图:
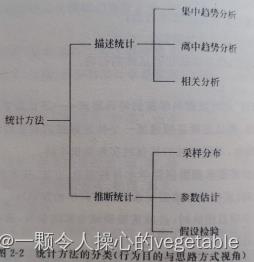
参数估计与假设检验的区别:

2从方法论角度看,基于统计的数据分析方法又可分为两个不同的层次——基本分析方法和元分析方法。如下图:
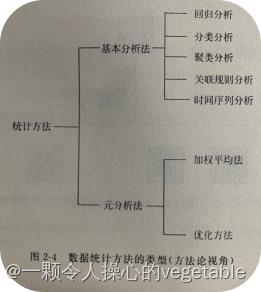
数据科学视角下的统计学
1.不是随机样本,而是全体数据
2.不是精确性,而是混杂性
3.不是因果关系,而是相关关系
机器学习
机器学习与数据库
机器学习为数据科学中充分发挥计算机的自动数据处理能力,拓展人的数据处理能力以及实现人机协同数据处理提供了重要手段。
机器学习的基本思路如下图:
数据科学中常用的机器学习知识
机器学习为数据科学中充分发挥计算机的自动数据处理能力,拓展人的数据处理能力以及实现人机协同数据处理提供了重要手段。
(1)基于实例学习
机器学习为数据科学中充分发挥计算机的自动数据处理能力,拓展人的数据处理能力以及实现人机协同数据处理提供了重要手段。
KNN(K近邻)算法、局部加权回归法
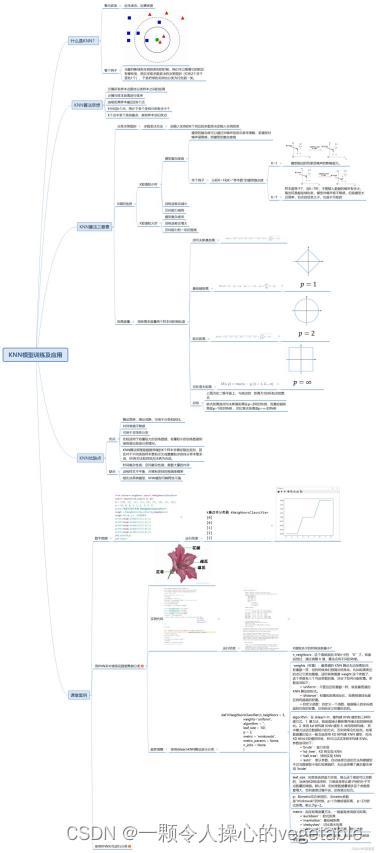
(2)概念学习
从有关某个布尔函数的输入输出训练样本中推算出该布尔函数。
FIND-S算法
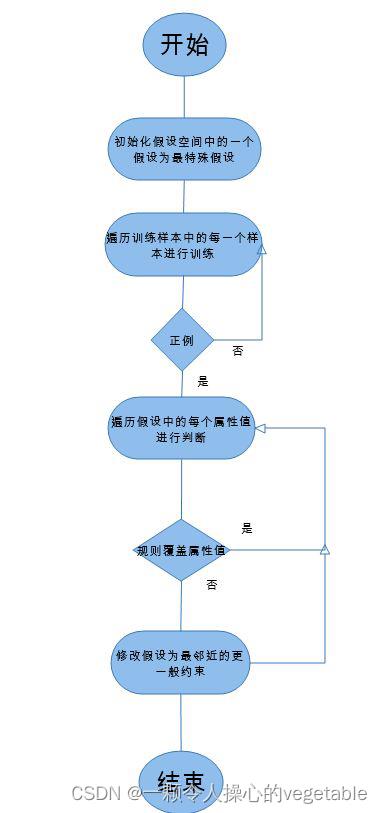
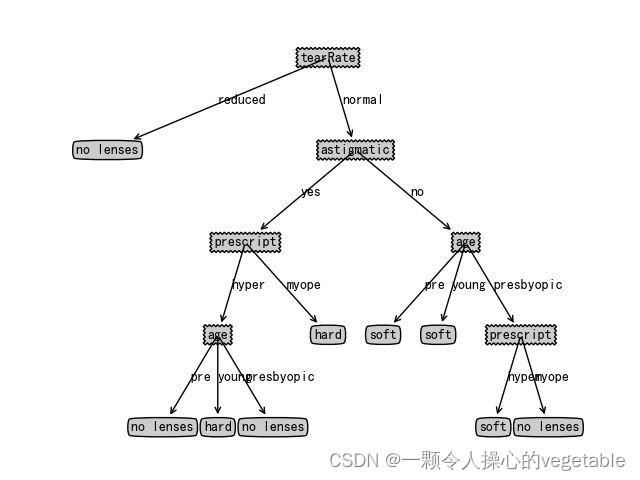
(3)决策树学习
本质是一种逼近离散值目标函数的过程。决策树代表的是一种分类过程。
其中:
根节点:代表分类的开始
叶节点:代表一个实例的结束
中间节点:代表相应实例的某一属性
节点之间的边:代表某一个属性的属性值
从根节点到叶节点的每条路径:代表一个具体的实例,同一个路径上的所有所有属性之间是“逻辑与”关系。
ID3算法
(4)人工神经网络学习
人工神经元是人工神经网络的最基本的组成部分。
人工神经网络中的神经元之间的连接方式对于选择具体学习算法具有重要影响。根据连接方式的不同,通常把人工神经网络分为无反馈的向前神经网络和相互连接型网络(反馈网络)。在人工神经网络中,实现人工神经元的方法有很多种,如感知器、线性单元和Sigmoid单元等。
深度学习
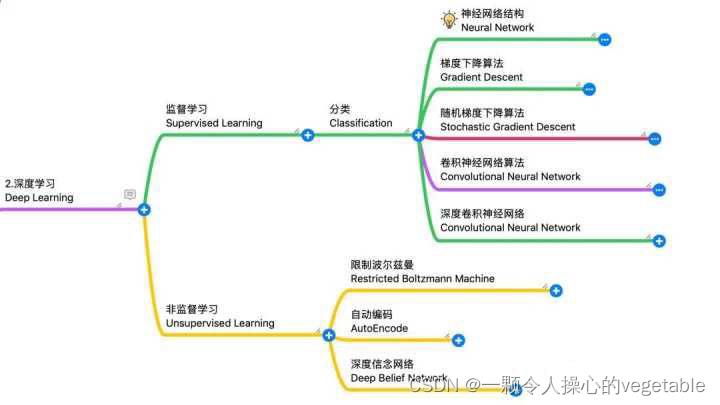
(5)贝叶斯学习
贝叶斯学习是一种以贝叶斯法则为基础的,并通过概率手段进行学习的方法。
朴素贝叶斯分类器
(6)遗传算法
遗传算法主要研究“从候选假设空间中搜索出最佳假设”。此处,“最佳假设”指“适应度”指标为最优的假设。
遗传算法借鉴的生物进化的三个基本原则:适者生存、两性繁衍及突变,分别对应遗传算法的三个基本算子:选择、交叉和突变。
遗传算法:GA算法
(7)分析学习
使用先验知识来分析或解释每个训练样本,以推理出样本的哪些特征与目标函数相关或不相关。因此,这些假设能使机器学习系统比单独依靠数据进行泛化有更高的精度。
(8)增强学习
主要研究的是如何协助自治Agent(机器人)的学习活动,进而达到选择最优动作的目的。
监督学习、无监督学习和半监督学习
数据科学视角下的机器学习
机器学习领域所面临的主要挑战有:
(1)过拟合
(2)维度灾难
(3)特征工程
(4)算法的可扩展性
(5)模型集成
数据可视化
1、视觉是人类获得信息的最主要途径。
2、相对于统计分析,数据可视化的主要优势:
(1)数据可视化处理可以洞察统计分析无法发现的结构和细节。
(2)数据可视化处理结果的解读对用户知识水平的要求较低。
3、可视化能够帮助人们提高理解与处理数据的效率。
 创作打卡挑战赛
创作打卡挑战赛
 赢取流量/现金/CSDN周边激励大奖
赢取流量/现金/CSDN周边激励大奖
以上是关于理论基础的主要内容,如果未能解决你的问题,请参考以下文章