关于 Kubernetes集群性能监控(kube-prometheus-stack/Metrics Server)的一些笔记
Posted 山河已无恙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于 Kubernetes集群性能监控(kube-prometheus-stack/Metrics Server)的一些笔记相关的知识,希望对你有一定的参考价值。
写在前面
- 学习
K8s涉及,整理笔记记忆 - 博文偏实战,内容涉及:
- 集群核心指标(
Core Metrics)监控工具Metrics Server的简介 Metrics Server的安装Demo- 集群自定义指标(
Custom Metrics)监控平台简介:PrometheusGrafanaNodeExporter
- 通过
helm(kube-prometheus-stack)安装监控平台的Demo
- 集群核心指标(
带着凡世的梦想,将污秽的灵魂依偎在纯洁的天边。它们是所有流浪、追寻、渴望与乡愁的永恒象征。 ——赫尔曼·黑塞《彼得.卡门青》
Kubernetes集群性能监控管理
Kubernetes平台搭建好后,了解Kubernetes平台及在此平台上部署的应用的运行状况,以及处理系统主要告誓及性能瓶颈,这些都依赖监控管理系统。
Kubernetes的早期版本依靠Heapster来实现完整的性能数据采集和监控功能,Kubernetes从1.8版本开始,性能数据开始以Metrics APl的方式提供标准化接口,并且从1.10版本开始将Heapster替换为MetricsServer。
在Kubernetes新的监控体系中:Metrics Server用于提供核心指标(Core Metrics) ,包括Node, Pod的CPU和内存使用指标。对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
监控节点状态,我们使用docker的话可以通过docker stats.
┌──[root@vms81.liruilongs.github.io]-[~]
└─$docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
781c898eea19 k8s_kube-scheduler_kube-scheduler-vms81.liruilongs.github.io_kube-system_5bd71ffab3a1f1d18cb589aa74fe082b_18 0.15% 23.22MiB / 3.843GiB 0.59% 0B / 0B 0B / 0B 7
acac8b21bb57 k8s_kube-controller-manager_kube-controller-manager-vms81.liruilongs.github.io_kube-system_93d9ae7b5a4ccec4429381d493b5d475_18 1.18% 59.16MiB / 3.843GiB 1.50% 0B / 0B 0B / 0B 6
fe97754d3dab k8s_calico-node_calico-node-skzjp_kube-system_a211c8be-3ee1-44a0-a4ce-3573922b65b2_14 4.89% 94.25MiB / 3.843GiB 2.39% 0B / 0B 0B / 4.1kB 40
那使用k8s的话,我们可以通过Metrics Server监控Pod和Node的CPU和内存资源使用数据
Metrics Server:集群性能监控平台
Metrics Server在部署完成后,将通过Kubernetes核心API Server 的/apis/metrics.k8s.io/v1beta1路径提供Pod和Node的监控数据。
安装Metrics Server
Metrics Server源代码和部署配置可以在GitHub代码库
curl -Ls https://api.github.com/repos/kubernetes-sigs/metrics-server/tarball/v0.3.6 -o metrics-server-v0.3.6.tar.gz
相关镜像
docker pull mirrorgooglecontainers/metrics-server-amd64:v0.3.6
镜像小伙伴可以下载一下,这里我已经下载好了,直接上传导入镜像
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible all -m copy -a "src=./metrics-img.tar dest=/root/metrics-img.tar"
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible all -m shell -a "systemctl restart docker "
192.168.26.82 | CHANGED | rc=0 >>
192.168.26.83 | CHANGED | rc=0 >>
192.168.26.81 | CHANGED | rc=0 >>
通过docker命令导入镜像
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ansible all -m shell -a "docker load -i /root/metrics-img.tar"
192.168.26.83 | CHANGED | rc=0 >>
Loaded image: k8s.gcr.io/metrics-server-amd64:v0.3.6
192.168.26.81 | CHANGED | rc=0 >>
Loaded image: k8s.gcr.io/metrics-server-amd64:v0.3.6
192.168.26.82 | CHANGED | rc=0 >>
Loaded image: k8s.gcr.io/metrics-server-amd64:v0.3.6
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$
修改metrics-server-deployment.yaml
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$mv kubernetes-sigs-metrics-server-d1f4f6f/ metrics
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$cd metrics/
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics]
└─$ls
cmd deploy hack OWNERS README.md version
code-of-conduct.md Gopkg.lock LICENSE OWNERS_ALIASES SECURITY_CONTACTS
CONTRIBUTING.md Gopkg.toml Makefile pkg vendor
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics]
└─$cd deploy/1.8+/
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$ls
aggregated-metrics-reader.yaml metrics-apiservice.yaml resource-reader.yaml
auth-delegator.yaml metrics-server-deployment.yaml
auth-reader.yaml metrics-server-service.yaml
这里修改一些镜像获取策略,因为Githup上的镜像拉去不下来,或者拉去比较麻烦,所以我们提前上传好
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$vim metrics-server-deployment.yaml
31 - name: metrics-server
32 image: k8s.gcr.io/metrics-server-amd64:v0.3.6
33 #imagePullPolicy: Always
34 imagePullPolicy: IfNotPresent
35 command:
36 - /metrics-server
37 - --metric-resolution=30s
38 - --kubelet-insecure-tls
39 - --kubelet-preferred-address-types=InternalIP
40 volumeMounts:
运行资源文件,创建相关资源对象
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$kubectl apply -f .
查看pod列表,metrics-server创建成功
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-78d6f96c7b-79xx4 1/1 Running 2 3h15m
calico-node-ntm7v 1/1 Running 1 12h
calico-node-skzjp 1/1 Running 4 12h
calico-node-v7pj5 1/1 Running 1 12h
coredns-545d6fc579-9h2z4 1/1 Running 2 3h15m
coredns-545d6fc579-xgn8x 1/1 Running 2 3h16m
etcd-vms81.liruilongs.github.io 1/1 Running 1 13h
kube-apiserver-vms81.liruilongs.github.io 1/1 Running 2 13h
kube-controller-manager-vms81.liruilongs.github.io 1/1 Running 4 13h
kube-proxy-rbhgf 1/1 Running 1 13h
kube-proxy-vm2sf 1/1 Running 1 13h
kube-proxy-zzbh9 1/1 Running 1 13h
kube-scheduler-vms81.liruilongs.github.io 1/1 Running 5 13h
metrics-server-bcfb98c76-gttkh 1/1 Running 0 70m
通过kubectl top nodes命令测试,
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$kubectl top nodes
W1007 14:23:06.102605 102831 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
vms81.liruilongs.github.io 555m 27% 2025Mi 52%
vms82.liruilongs.github.io 204m 10% 595Mi 15%
vms83.liruilongs.github.io 214m 10% 553Mi 14%
┌──[root@vms81.liruilongs.github.io]-[~/ansible/metrics/deploy/1.8+]
└─$
Prometheus+Grafana+NodeExporter:集群监控平台
在各个计算节点上部署NodeExporter采集CPU、内存、磁盘及IO信息,并将这些信息传输给监控节点上的Prometheus服务器进行存储分析,通过Grafana进行可视化监控,
Prometheus
Prometheus是一款开源的监控解决方案,由SoundCloud公司开发的开源监控系统,是继Kubernetes之后CNCF第2个孵化成功的项目,在容器和微服务领域得到了广泛应用,能在监控Kubernetes平台的同时监控部署在此平台中的应用,它提供了一系列工具集及多维度监控指标。Prometheus依赖Grafana实现数据可视化。
Prometheus的主要特点如下:
- 使用
指标名称及键值对标识的多维度数据模型。 - 采用灵活的
查询语言PromQL。 - 不依赖
分布式存储,为自治的单节点服务。 - 使用
HTTP完成对监控数据的拉取。 - 支持通过
网关推送时序数据。 - 支持多种图形和
Dashboard的展示,例如Grafana。
Prometheus生态系统由各种组件组成,用于功能的扩充:
| 组件 | 描述 |
|---|---|
| Prometheus Server | 负责监控数据采集和时序数据存储,并提供数据查询功能。 |
| 客户端SDK | 对接Prometheus的开发工具包。 |
| Push Gateway | 推送数据的网关组件。 |
| 第三方Exporter | 各种外部指标收集系统,其数据可以被Prometheus采集 |
| AlertManager | 告警管理器。 |
| 其他辅助支持工具 | – |
Prometheus的核心组件Prometheus Server的主要功能包括:
从
Kubernetes Master获取需要监控的资源或服务信息;从各种Exporter抓取(Pull)指标数据,然后将指标数据保存在时序数据库(TSDB)中;向其他系统提供HTTP API进行查询;提供基于PromQL语言的数据查询;可以将告警数据推送(Push)给AlertManager,等等。
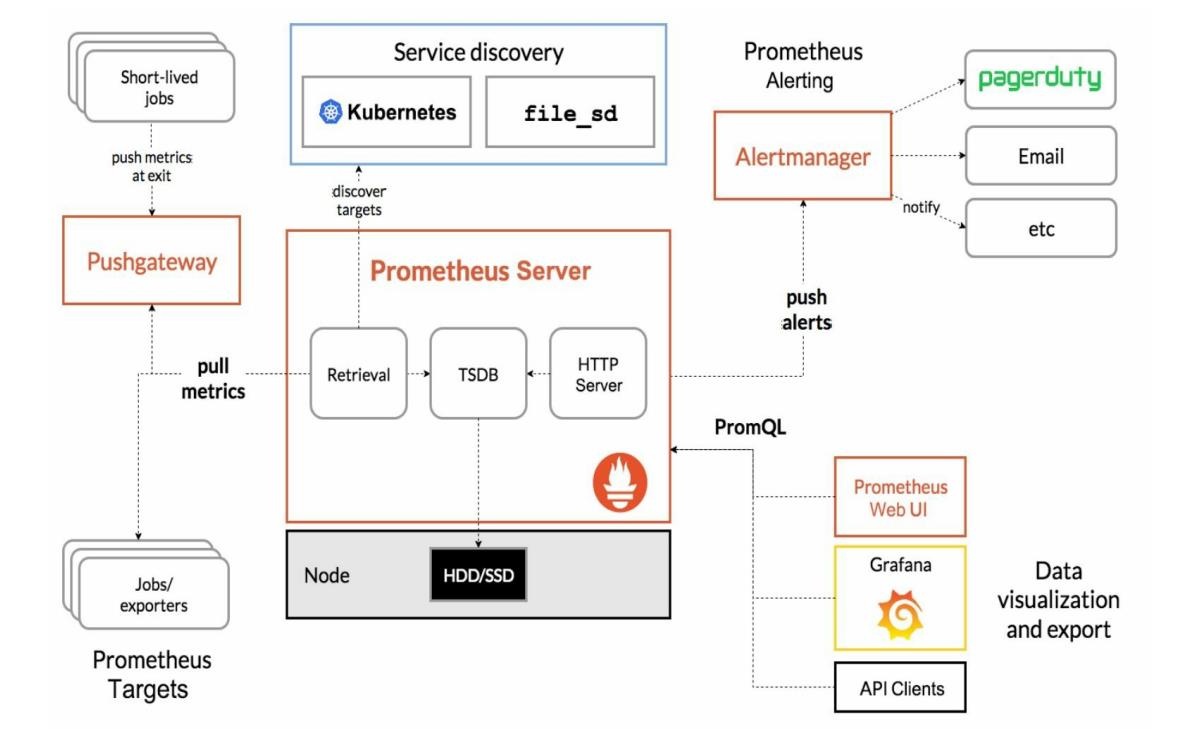
Prometheus的系统架构:
NodeExporter
NodeExporter主要用来采集服务器CPU、内存、磁盘、IO等信息,是机器数据的通用采集方案。只要在宿主机上安装NodeExporter和cAdisor容器,通过Prometheus进行抓取即可。它同Zabbix的功能相似.
Grafana
Grafana是一个Dashboard工具,用Go和JS开发,它是一个时间序列数据库的界面展示层,通过SQL命令查询出Metrics并将结果展示出来。它能自定义多种仪表盘,可以轻松实现覆盖多个Docker的宿主机监控信息的展现。
搭建Prometheus+Grafana+NodeExporter平台
这里我们通过
helm的方式搭建,简单方便快捷,运行之后,相关的镜像都会创建成功.下面是创建成功的镜像列表。
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-liruilong-kube-prometheus-alertmanager-0 2/2 Running 0 61m
liruilong-grafana-5955564c75-zpbjq 3/3 Running 0 62m
liruilong-kube-prometheus-operator-5cb699b469-fbkw5 1/1 Running 0 62m
liruilong-kube-state-metrics-5dcf758c47-bbwt4 1/1 Running 7 (32m ago) 62m
liruilong-prometheus-node-exporter-rfsc5 1/1 Running 0 62m
liruilong-prometheus-node-exporter-vm7s9 1/1 Running 0 62m
liruilong-prometheus-node-exporter-z9j8b 1/1 Running 0 62m
prometheus-liruilong-kube-prometheus-prometheus-0 2/2 Running 0 61m
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$
环境版本
我的K8s集群版本
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$kubectl get nodes
NAME STATUS ROLES AGE VERSION
vms81.liruilongs.github.io Ready control-plane,master 34d v1.22.2
vms82.liruilongs.github.io Ready <none> 34d v1.22.2
vms83.liruilongs.github.io Ready <none> 34d v1.22.2
hrlm版本
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$helm version
version.BuildInfoVersion:"v3.2.1", GitCommit:"fe51cd1e31e6a202cba7dead9552a6d418ded79a", GitTreeState:"clean", GoVersion:"go1.13.10"
prometheus-operator(旧名字)安装出现的问题
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$helm search repo prometheus-operator
NAME CHART VERSION APP VERSION DESCRIPTION
ali/prometheus-operator 8.7.0 0.35.0 Provides easy monitoring definitions for Kubern...
azure/prometheus-operator 9.3.2 0.38.1 DEPRECATED Provides easy monitoring definitions...
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$helm install liruilong ali/prometheus-operator
Error: failed to install CRD crds/crd-alertmanager.yaml: unable to recognize "": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$helm pull ali/prometheus-operator
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$
解决办法:新版本安装
直接下载kube-prometheus-stack(新)的chart包,通过命令安装:
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$ls
index.yaml kube-prometheus-stack-30.0.1.tgz liruilonghelm liruilonghelm-0.1.0.tgz mysql mysql-1.6.4.tgz
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
解压chart包kube-prometheus-stack-30.0.1.tgz
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$tar -zxf kube-prometheus-stack-30.0.1.tgz
创建新的命名空间
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$cd kube-prometheus-stack/
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl create ns monitoring
namespace/monitoring created
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl config set-context $(kubectl config current-context) --namespace=monitoring
Context "kubernetes-admin@kubernetes" modified.
进入文件夹,直接通过helm install liruilong .安装
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$ls
Chart.lock charts Chart.yaml CONTRIBUTING.md crds README.md templates values.yaml
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$helm install liruilong .
kube-prometheus-admission-create对应Pod的相关镜像下载不下来问题
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$kubectl get pods
NAME READY STATUS RESTARTS AGE
liruilong-kube-prometheus-admission-create--1-bn7x2 0/1 ImagePullBackOff 0 33s
查看pod详细信息,发现是谷歌的一个镜像国内无法下载
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$kubectl describe pod liruilong-kube-prometheus-admission-create--1-bn7x2
Name: liruilong-kube-prometheus-admission-create--1-bn7x2
Namespace: monitoring
Priority: 0
Node: vms83.liruilongs.github.io/192.168.26.83
Start Time: Sun, 16 Jan 2022 02:43:07 +0800
Labels: app=kube-prometheus-stack-admission-create
app.kubernetes.io/instance=liruilong
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/part-of=kube-prometheus-stack
app.kubernetes.io/version=30.0.1
chart=kube-prometheus-stack-30.0.1
controller-uid=2ce48cd2-a118-4e23-a27f-0228ef6c45e7
heritage=Helm
job-name=liruilong-kube-prometheus-admission-create
release=liruilong
Annotations: cni.projectcalico.org/podIP: 10.244.70.8/32
cni.projectcalico.org/podIPs: 10.244.70.8/32
Status: Pending
IP: 10.244.70.8
IPs:
IP: 10.244.70.8
Controlled By: Job/liruilong-kube-prometheus-admission-create
Containers:
create:
Container ID:
Image: k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.0@sha256:f3b6b39a6062328c095337b4cadcefd1612348fdd5190b1dcbcb9b9e90bd8068
Image ID:
Port: <none>
Host Port:
。。。。。。。。。。。。。。。。。。。。。。。。。。。
在dokcer仓库里找了一个类似的,通过 kubectl edit修改
image: k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.0 替换为 : docker.io/liangjw/kube-webhook-certgen:v1.1.1
或者也可以修改配置文件从新install(记得要把sha注释掉)
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$ls
index.yaml kube-prometheus-stack kube-prometheus-stack-30.0.1.tgz liruilonghelm liruilonghelm-0.1.0.tgz mysql mysql-1.6.4.tgz
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create]
└─$cd kube-prometheus-stack/
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$ls
Chart.lock charts Chart.yaml CONTRIBUTING.md crds README.md templates values.yaml
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$cat values.yaml | grep -A 3 -B 2 kube-webhook-certgen
enabled: true
image:
repository: docker.io/liangjw/kube-webhook-certgen
tag: v1.1.1
#sha: "f3b6b39a6062328c095337b4cadcefd1612348fdd5190b1dcbcb9b9e90bd8068"
pullPolicy: IfNotPresent
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$helm del liruilong;helm install liruilong .
之后其他的相关pod正常创建中
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl get pods
NAME READY STATUS RESTARTS AGE
liruilong-grafana-5955564c75-zpbjq 0/3 ContainerCreating 0 27s
liruilong-kube-prometheus-operator-5cb699b469-fbkw5 0/1 ContainerCreating 0 27s
liruilong-kube-state-metrics-5dcf758c47-bbwt4 0/1 ContainerCreating 0 27s
liruilong-prometheus-node-exporter-rfsc5 0/1 ContainerCreating 0 28s
liruilong-prometheus-node-exporter-vm7s9 0/1 ContainerCreating 0 28s
liruilong-prometheus-node-exporter-z9j8b 0/1 ContainerCreating 0 28s
kube-state-metrics这个pod的镜像也没有拉取下来。应该也是相同的原因
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-liruilong-kube-prometheus-alertmanager-0 2/2 Running 0 3m35s
liruilong-grafana-5955564c75-zpbjq 3/3 Running 0 4m46s
liruilong-kube-prometheus-operator-5cb699b469-fbkw5 1/1 Running 0 4m46s
liruilong-kube-state-metrics-5dcf758c47-bbwt4 0/1 ImagePullBackOff 0 4m46s
liruilong-prometheus-node-exporter-rfsc5 1/1 Running 0 4m47s
liruilong-prometheus-node-exporter-vm7s9 1/1 Running 0 4m47s
liruilong-prometheus-node-exporter-z9j8b 1/1 Running 0 4m47s
prometheus-liruilong-kube-prometheus-prometheus-0 2/2 Running 0 3m34s
同样 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0 这个镜像没办法拉取
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl describe pod liruilong-kube-state-metrics-5dcf758c47-bbwt4
Name: liruilong-kube-state-metrics-5dcf758c47-bbwt4
Namespace: monitoring
Priority: 0
Node: vms82.liruilongs.github.io/192.168.26.82
Start Time: Sun, 16 Jan 2022 02:59:53 +0800
Labels: app.kubernetes.io/component=metrics
app.kubernetes.io/instance=liruilong
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=kube-state-metrics
app.kubernetes.io/part-of=kube-state-metrics
app.kubernetes.io/version=2.3.0
helm.sh/chart=kube-state-metrics-4.3.0
pod-template-hash=5dcf758c47
release=liruilong
Annotations: cni.projectcalico.org/podIP: 10.244.171.153/32
cni.projectcalico.org/podIPs: 10.244.171.153/32
Status: Pending
IP: 10.244.171.153
IPs:
IP: 10.244.171.153
Controlled By: ReplicaSet/liruilong-kube-state-metrics-5dcf758c47
Containers:
kube-state-metrics:
Container ID:
Image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
Image ID:
Port: 8080/TCP
。。。。。。。。。。。。。。。。。。。。。。
同样的,我们通过docker仓库找一下相同的,然后通过kubectl edit pod修改一下
k8s.gcr.io/kube-state-metrics/kube-state-metrics 替换为: docker.io/dyrnq/kube-state-metrics:v2.3.0
可以先在节点机上拉取一下
┌──[root@vms81.liruilongs.github.io]-[~/ansible]
└─$ ansible node -m shell -a "docker pull dyrnq/kube-state-metrics:v2.3.0"
192.168.26.82 | CHANGED | rc=0 >>
v2.3.0: Pulling from dyrnq/kube-state-metrics
e8614d09b7be: Pulling fs layer
53ccb90bafd7: Pulling fs layer
e8614d09b7be: Verifying Checksum
e8614d09b7be: Download complete
e8614d09b7be: Pull complete
53ccb90bafd7: Verifying Checksum
53ccb90bafd7: Download complete
53ccb90bafd7: Pull complete
Digest: sha256:c9137505edaef138cc23479c73e46e9a3ef7ec6225b64789a03609c973b99030
Status: Downloaded newer image for dyrnq/kube-state-metrics:v2.3.0
docker.io/dyrnq/kube-state-metrics:v2.3.0
192.168.26.83 | CHANGED | rc=0 >>
v2.3.0: Pulling from dyrnq/kube-state-metrics
e8614d09b7be: Pulling fs layer
53ccb90bafd7: Pulling fs layer
e8614d09b7be: Verifying Checksum
e8614d09b7be: Download complete
e8614d09b7be: Pull complete
53ccb90bafd7: Verifying Checksum
53ccb90bafd7: Download complete
53ccb90bafd7: Pull complete
Digest: sha256:c9137505edaef138cc23479c73e46e9a3ef7ec6225b64789a03609c973b99030
Status: Downloaded newer image for dyrnq/kube-state-metrics:v2.3.0
docker.io/dyrnq/kube-state-metrics:v2.3.0
修改完之后,会发现所有的pod都创建成功
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-liruilong-kube-prometheus-alertmanager-0 2/2 Running 0 61m
liruilong-grafana-5955564c75-zpbjq 3/3 Running 0 62m
liruilong-kube-prometheus-operator-5cb699b469-fbkw5 1/1 Running 0 62m
liruilong-kube-state-metrics-5dcf758c47-bbwt4 1/1 Running 7 (32m ago) 62m
liruilong-prometheus-node-exporter-rfsc5 1/1 Running 0 62m
liruilong-prometheus-node-exporter-vm7s9 1/1 Running 0 62m
liruilong-prometheus-node-exporter-z9j8b 1/1 Running 0 62m
prometheus-liruilong-kube-prometheus-prometheus-0 2/2 Running 0 61m
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$
然后我们需要修改liruilong-grafana SVC的类型为NodePort,这样,物理机就可以访问了
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 33m
liruilong-grafana ClusterIP 10.99.220.121 <none> 80/TCP 34m
liruilong-kube-prometheus-alertmanager ClusterIP 10.97.193.228 <none> 9093/TCP 34m
liruilong-kube-prometheus-operator ClusterIP 10.101.106.93 <none> 443/TCP 34m
liruilong-kube-prometheus-prometheus ClusterIP 10.105.176.19 <none> 9090/TCP 34m
liruilong-kube-state-metrics ClusterIP 10.98.94.55 <none> 8080/TCP 34m
liruilong-prometheus-node-exporter ClusterIP 10.110.216.215 <none> 9100/TCP 34m
prometheus-operated ClusterIP None <none> 9090/TCP 33m
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack]
└─$kubectl edit svc liruilong-grafana
service/liruilong-grafana edited
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 35m
liruilong-grafana NodePort 10.99.220.121 <none> 80:30443/TCP 36m
liruilong-kube-prometheus-alertmanager ClusterIP 10.97.193.228 <none> 9093/TCP 36m
liruilong-kube-prometheus-operator ClusterIP 10.101.106.93 <none> 443/TCP 36m
liruilong-kube-prometheus-prometheus ClusterIP 10.105.176.19 <none> 9090/TCP 36m
liruilong-kube-state-metrics ClusterIP 10.98.94.55 <none> 8080/TCP 36m
liruilong-prometheus-node-exporter ClusterIP 10.110.216.215 <none> 9100/TCP 36m
prometheus-operated ClusterIP None <none> 9090/TCP 35m
| 物理机访问 |
|---|
 |
通过secrets解密获取用户名密码
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get secrets | grep grafana
liruilong-grafana Opaque 3 38m
liruilong-grafana-test-token-q8z8j kubernetes.io/service-account-token 3 38m
liruilong-grafana-token-j94p8 kubernetes.io/service-account-token 3 38m
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get secrets liruilong-grafana -o yaml
apiVersion: v1
data:
admin-password: cHJvbS1vcGVyYXRvcg==
admin-user: YWRtaW4=
ldap-toml: ""
kind: Secret
metadata:
annotations:
meta.helm.sh/release-name: liruilong
meta.helm.sh/release-namespace: monitoring
creationTimestamp: "2022-01-15T18:59:40Z"
labels:
app.kubernetes.io/instance: liruilong
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: grafana
app.kubernetes.io/version: 8.3.3
helm.sh/chart: grafana-6.20.5
name: liruilong-grafana
namespace: monitoring
resourceVersion: "1105663"
uid: c03ff5f3-deb5-458c-8583-787f41034469
type: Opaque
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get secrets liruilong-grafana -o jsonpath='.data.admin-user'| base64 -d
adminbase64: 输入无效
┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-helm-create/kube-prometheus-stack/templates]
└─$kubectl get secrets liruilong-grafana -o jsonpath='.data.admin-password'| base64 -d
prom-operatorbase64: 输入无效
得到用户名密码:admin/prom-operator
| 正常登录,查看监控信息 |
|---|
 |
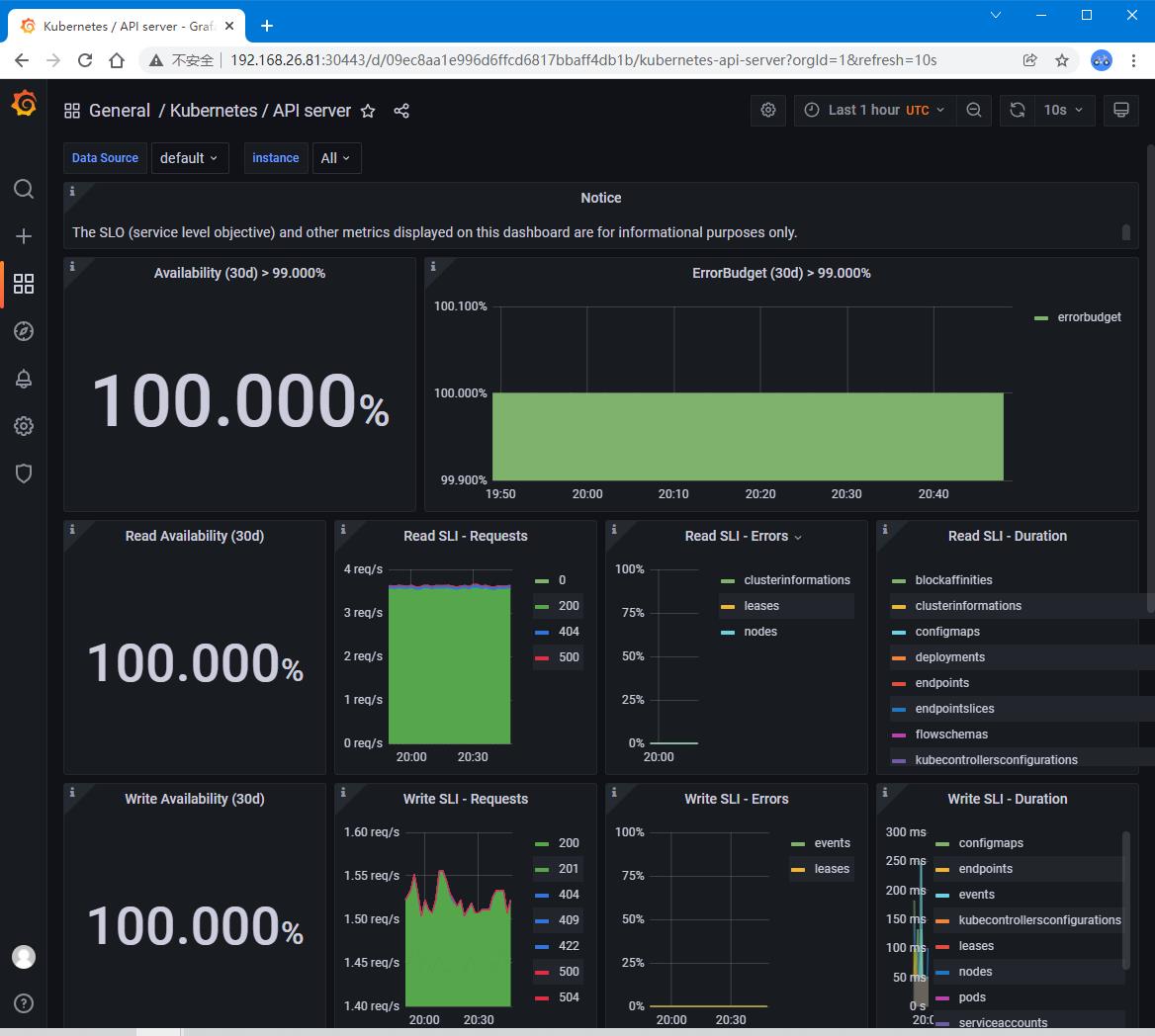 |
以上是关于关于 Kubernetes集群性能监控(kube-prometheus-stack/Metrics Server)的一些笔记的主要内容,如果未能解决你的问题,请参考以下文章
使用 Prometheus + Grafana 对 Kubernetes 进行性能监控的实践
如何用原生Prometheus监控大规模Kubernetes集群
使用Heapster和Splunk监控Kubernetes运行性能