因果推断实战:淘宝3D化价值分析小结
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断实战:淘宝3D化价值分析小结相关的知识,希望对你有一定的参考价值。

观察性因果推断方法有很多,文章主要介绍了PSM、贝叶斯概率图、DID这几种方法,可将文章分享的实践方法作为因果推断分析中的一种参考。
背景介绍
▐ 为什么需要因果推断
统计学有一些有趣的‘研究’:太阳黑子与男性自杀率间存在关系;而一个国家的人均巧克力消费量越高,出现诺贝尔奖获得者的比例越大;甚至还有这样的报导:

这些现象揭示了传统统计学的局限性:由于我们不可能对人群是否吃巧克力,属于哪个星座做随机化实验,因此我们得到的数据都是观察性数据,它只能告诉我们数据的相关性,而非因果性。我们观察到了巧克力消费和诺奖数量,星座和违章人数的线性关系,但它没有告诉我们的是,巧克力消费和诺奖数量背后的共同原因可能是经济发达程度;而违章率高的星座在当地人口占比最高。
从对社会和业务更有意义的角度来说,我们想知道的是 ‘怎么做才能提升诺奖的数量’ 或者‘用户点击某功能能否带来加购/留存的提升’,而这样的问题就需要我们探究现象背后的原因,以及量化原因对于结果造成的影响,因果推断应运而生。基于反事实的思想和拟合随机实验的一系列方法,我们能够控制混杂变量,从观察性的数据中得出因果性结论,从而论证业务价值,给出落地建议。
▐ 什么是因果推断
因果推断是一门探究事物之间因果关系的学科,学术界有两个主要框架:因果图模型和潜在结果(Potential Outcome, PO)模型。因果图模型是由Judea Pearl提出,着眼于因果关系的识别;而潜在结果模型是由统计学家 Donald Rubin 在上世纪七十年代所开创的因果推断框架,很多社会科学家常用的工具,比如倾向性得分匹配(Propensity Score Matching)模型和工具变量模型,都可以归类到潜在结果模型。
站在数据分析的角度,潜在结果模型更加通俗易懂。我们使用潜在结果模型来给出因果推断的严谨定义。
基本概念和符号
首先,定义一些基本概念:
干预(treatment)
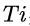 :用来表示用户是否接受了某种干预(being treated),例如是否命中了某个策略,点击了优惠券。
:用来表示用户是否接受了某种干预(being treated),例如是否命中了某个策略,点击了优惠券。潜在结果(potential outcome)
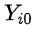 和
和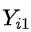 :每个用户i对于是否接受干预分别有两个潜在结果
:每个用户i对于是否接受干预分别有两个潜在结果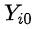 和
和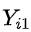 。假设我想要探究高考对于小明收入的影响,那么真实的结果就是小明的高考分数和他的收入。而假设平行世界里有和小明一模一样的小明2号,但他高考少了20分, 那小明的收入和小明2号的收入都被称为潜在结果/反事实结果。只有真实发生的潜在结果是实际存在的。
。假设我想要探究高考对于小明收入的影响,那么真实的结果就是小明的高考分数和他的收入。而假设平行世界里有和小明一模一样的小明2号,但他高考少了20分, 那小明的收入和小明2号的收入都被称为潜在结果/反事实结果。只有真实发生的潜在结果是实际存在的。观察结果(observed outcome) :观察到的、真实发生的潜在结果
混淆变量(confounders)
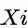 :直观来说(虽然不太严谨),混淆变量是一系列用户特征,越全越好。严格来说,混杂变量需要足够全使得对于一群 混杂变量相同的用户来说,他们的潜在结果
:直观来说(虽然不太严谨),混淆变量是一系列用户特征,越全越好。严格来说,混杂变量需要足够全使得对于一群 混杂变量相同的用户来说,他们的潜在结果 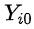 和
和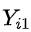 是相互独立的。这个严格的定义其实是因果效应的可识别性的必要条件之一。
是相互独立的。这个严格的定义其实是因果效应的可识别性的必要条件之一。
其次,通过因果推断可以得到什么:
我们从因果推断推出来的,是因果效应。因为数据的缺失,个体的因果效应(Treatment Effect, TE)是不可被识别的,也就是说,个体的因果效应不能用已观测到的数据来表示。但我们可以描述人群的平均因果效应,即个体因果效应的均值(Average treatment effect, ATE)。
根据不同的业务场景,我们可能也想知道受到干预的人群的平均因果效应(Average treatment effect on the Treated, ATT),或者人群某个subgroup(受到干预)的平均因果效应(Conditional Average Treatment Effect, CATE),(Conditional Average Treatment effect on the Treated, CATT)
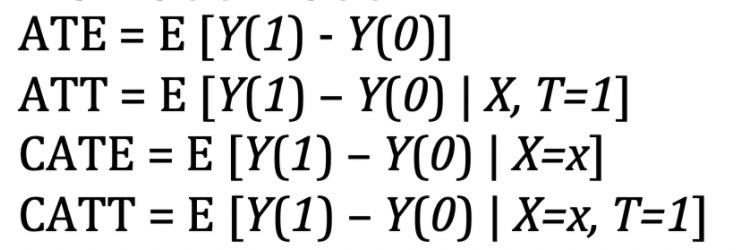
举个例子
以Push投放对内容阅读篇数的影响为例。我们对于ID = 1,2,3的用户投放Push(T=Y),ID为4,5,6的用户则不进行干预。
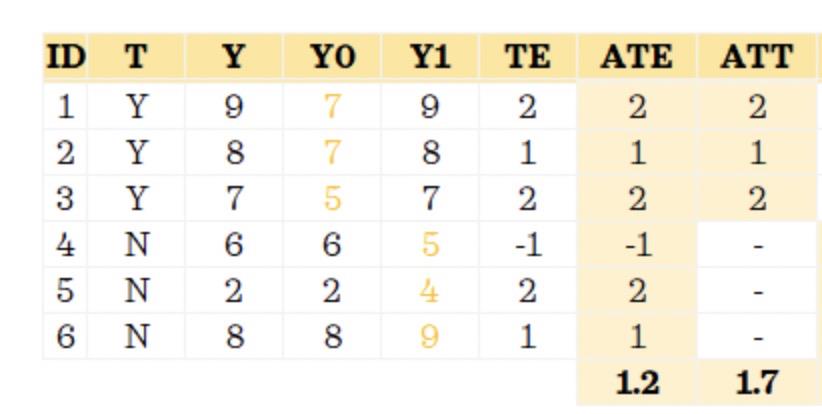
以ID =1的用户为例:假如投放Push后,她的阅读篇数是9(Y1),而假如不投放,她的篇数是7(Y0);这两者都是潜在结果,只有站在上帝视角才能同时看到两个结果
因为我们真的对她投放了push,因此观察到的真实结果就是阅读篇数为9。(‘不投放时篇数为7’这个事实就永远不得而知了)
接下来我们站在“上帝视角”解释一下ATE和ATT的计算。在上帝视角下,我们可以同时观测到每个用户的两个潜在结果,算出两种因果效应分别为ATE=1.2>0 和 ATT=1.7>0。因此,push确实是可以提升用户的阅读篇数的,这个结论就符合常理了。ATE和ATT的具体计算过程如下:
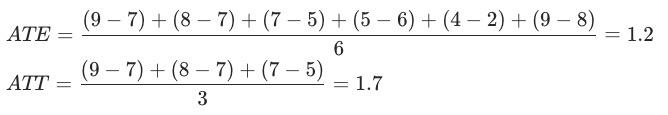
假如我们失去了“上帝视角”,ATE和ATT就没法用上面的公式来计算了,因为对于每一个用户的两个潜在结果,总是有一个是观察不到的。这时候离线因果推断就派上用场啦!
▐ 什么时候用,怎么用?
条件允许的情况下,ab test是最佳的因果推断方法之一。但ab test也有自己的局限性:
ab test不可进行:比如我们不能强迫一组用户‘吸烟’,另一组用户‘不吸烟’去观察吸烟对健康的危害;
ab test成本太高:当线上实验的选择太多,而产品的流量/时间成本是有限时,逐一对每一个实验都进行测试显然不现实,此时通过离线数据进行因果推断可以帮助我们科学地预判不同实验策略的‘前途’,让我们可以优先尝试前途更加光明的实验;
因果推断是通过特定的方法对观察性数据控制混杂变量以拟合随机试验。所有的方法的核心思想,都离不开控制混杂(control confounding variables)。在上文小明高考的例子里,我提到过要寻找‘一模一样的小明2号’,而‘一模一样’的目的就是为了控制混杂变量。只有在控制了两者混杂变量一致,仅有高考分数不同的情况下,我们才能计算高考分数对工资收入的影响。
混杂变量是指对于‘因’和‘果’都有影响的因素,忽视它们会对结果带来致命的偏倚;对小明和小明2号来说,需要控制的混杂变量有:上过的学校,遇见过的老师,自己的学习、睡眠时长,等等等等,因为这些都会影响高考的分数(因),也会影响未来的收入(果)。但是例如小明的头发颜色、身高这种特征并不会对于因果变量有什么影响,无需控制。所以在实践中很关键的一点,就是判断到底需要控制哪些混杂,才能让你认为小明和小明2号是‘同质’的。判断混杂因子并没有一个标准方法,而是需要结合对业务的深度理解。不同的数据类型、场景会有不同的适用方法,下面是一些常见的判断标准和对应方法:
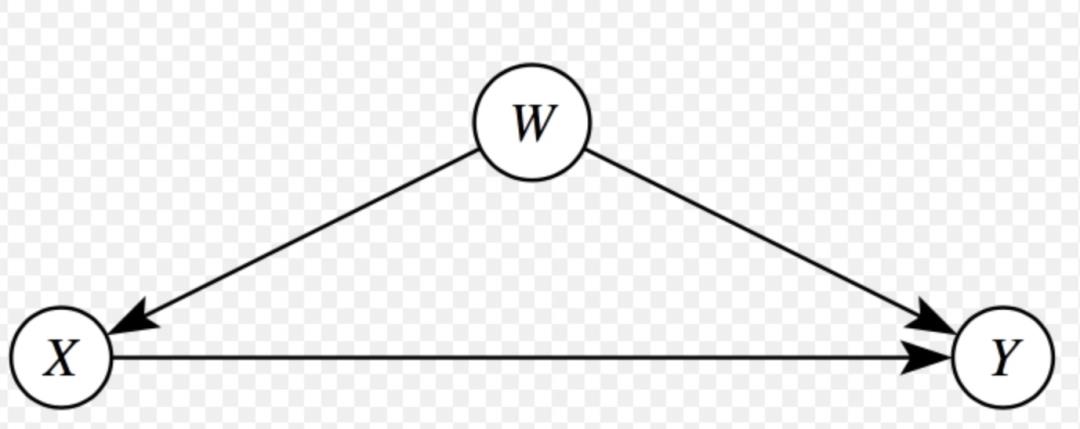
混杂(W)的典型结构:同时作用于X和Y。
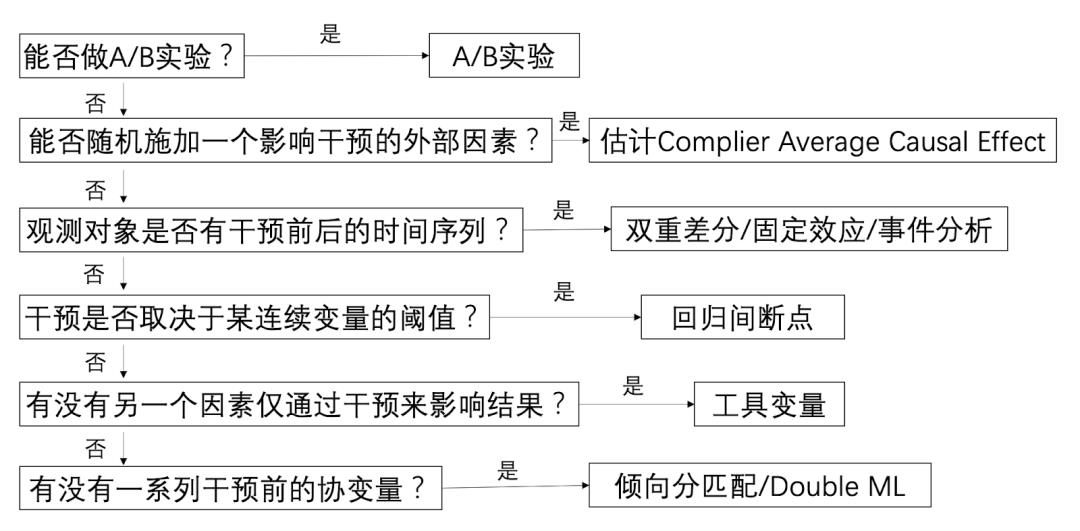
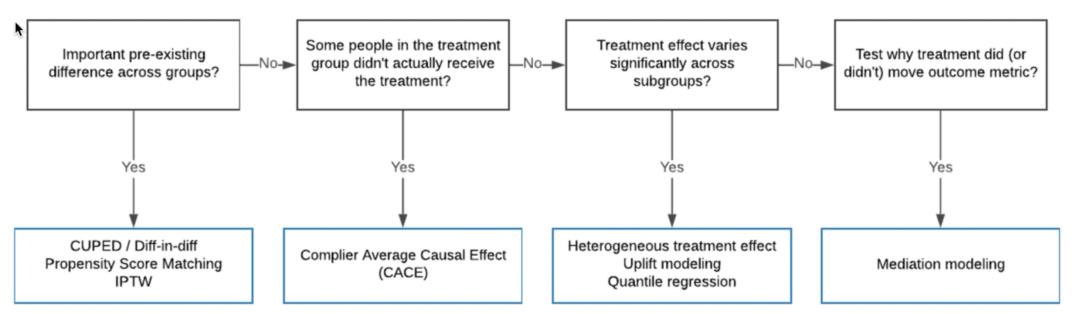
常见方法一览
离线因果推断在淘宝3D化价值分析上的实战
这部分主要介绍大淘宝技术-家装家居数据科学团队在淘宝3D化项目中对项目的价值分析上的实战,通过这一实例帮助大家对因果推断如何运用有更直接的认识。
▐ 业务背景和现状
淘宝3D化为消费者提供多元化的场景导购内容,包括 2D 场景图文,3D 样板间,DIY 样板间等3D沉浸式体验。通过应用3D技术实现沉浸式商品导购体验,影响用户购买决策提升确定性,从而提升整体家装类目的导购转化率以及用户留存。
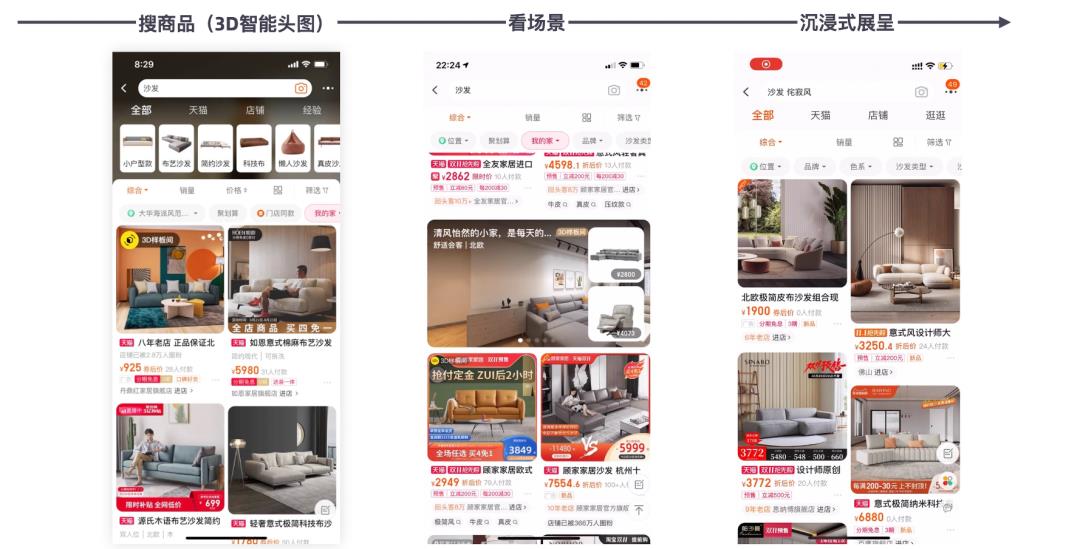
在淘宝搜索页实现场景化
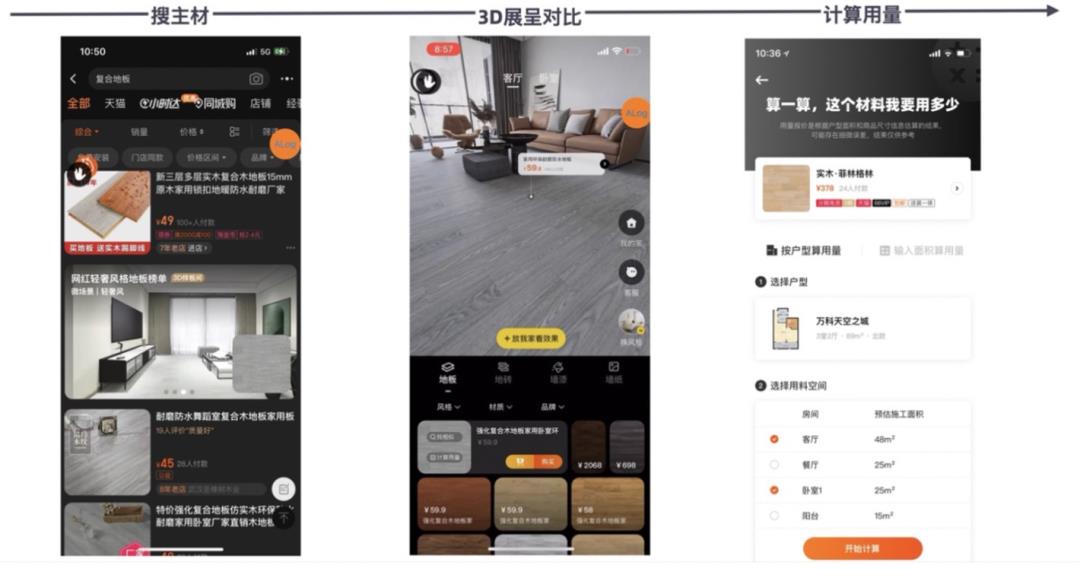
在3D样板间实现客制化
自项目启动以来,业务一直受困于一个问题:3D模型的IPV覆盖率未达预期,增速不佳。3D模型是所有3D化产品的基石,没有模型意味着无法3D化。深入分析原因后发现,商家无法通过‘上模型’获得差异化权益、以及看不到产品的长期效果,共同导致了他们的配合意愿低。因此,验证3D化价值成为了当务之急。通过对价值指标体系,受益方进行拆分,结合业务理解确立了如下的分析框架,并选择了用因果推断来验证不同3D化产品的价值,因为它可以真正回答‘XX产品导致了加购率/成交率提升Y%’这类问题:
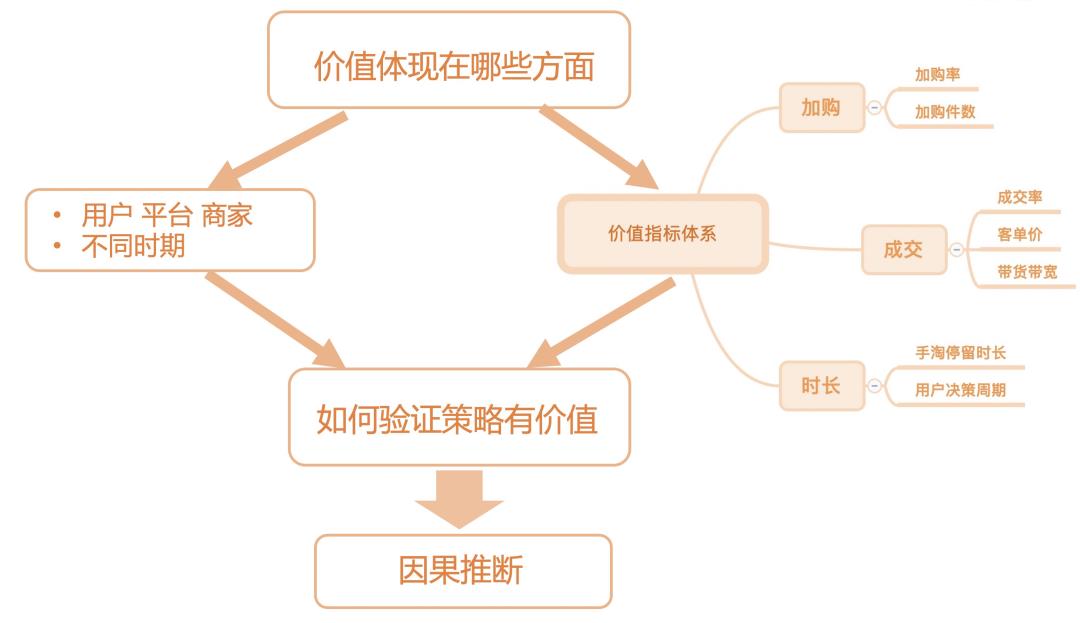
▐ 3D样板间价值分析
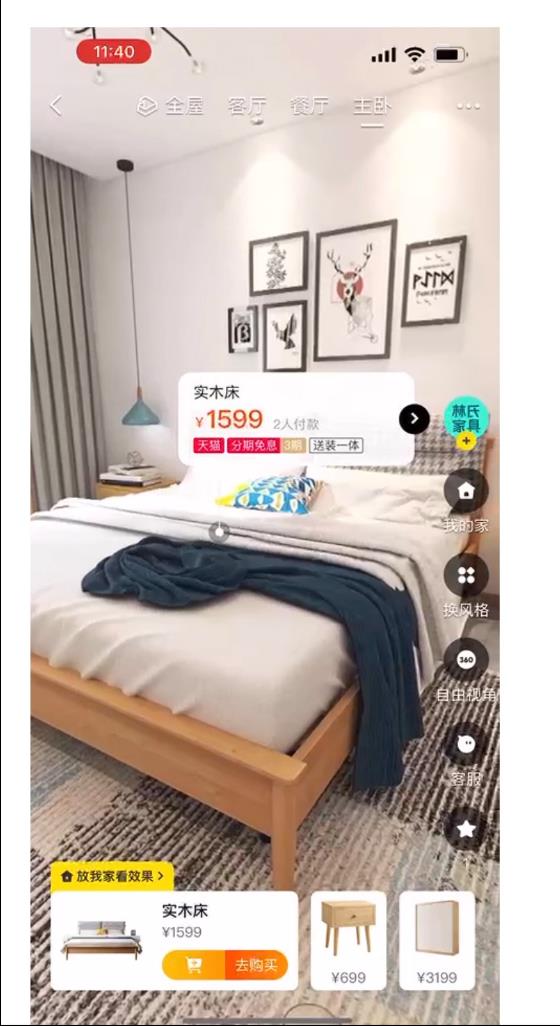
用户可以从商详页,首猜,主搜云卡片等渠道进入样板间,并在样板间内实现多点漫游,换风格,搭配家具,放我家等功能,给用户更场景化,私人化的体验。选取进入3D样板间的用户,利用倾向性得分匹配法(PSM)获取对照组的同质用户,分析用户在各个价值指标的差异。
基于倾向性得分匹配法 - 量化价值:
倾向性得分匹配法:一句话概括,就是匹配分数相同的‘同质’用户。由于在观察研究中,混杂变量较多,无法一一匹配,因此将多个混淆变量用一个综合分数作为表征。通过分数对用户进行匹配,最终得到两组‘同质’人群。
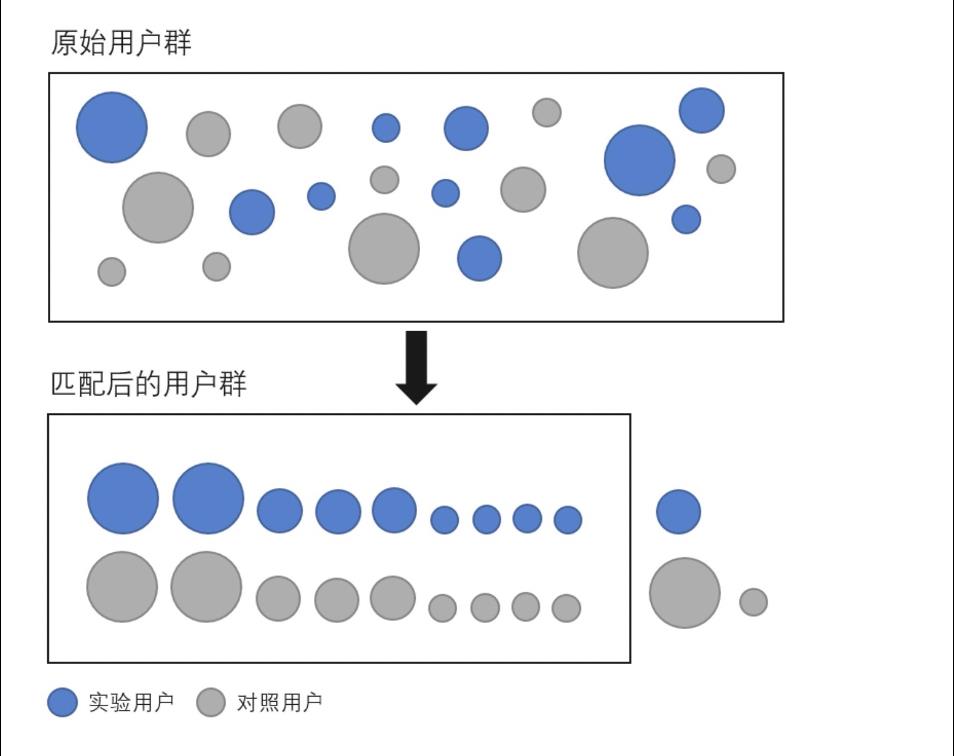
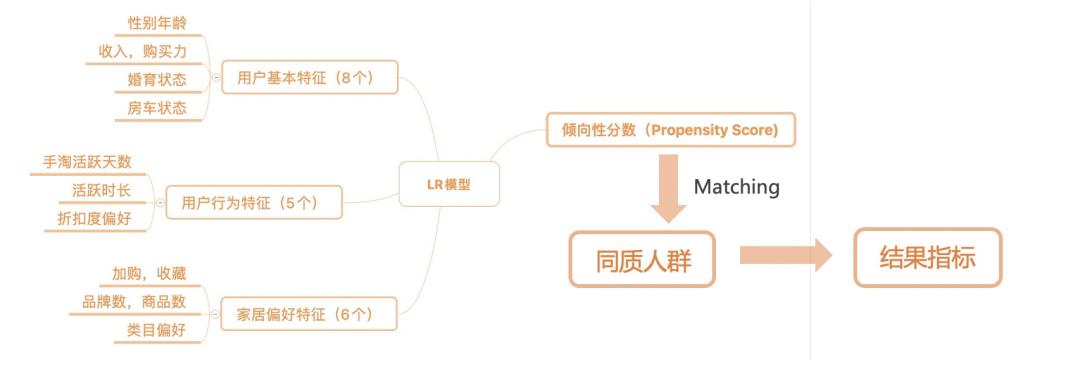
使用20余种用户基本特征,行为特征和家居偏好特征作为混杂因素,应用于匹配模型;
匹配后数据表明,实验组用户的加购率+24.85%,手淘停留时长+27.68%,客单价+29.53%,带货带宽+5.98%,用户决策周期-5.75%
通过PSM的分析结论,我们定量的验证了3D样板间对手淘各项指标的正向价值,进一步的,我们想要挖掘背后是什么因素使得3D样板间产生了这些价值:
基于贝叶斯因果图 - 挖掘产生价值行为:
贝叶斯因果图:计算变量之间的熵增,结合问题结构推理成对变量之间的因果关系;若两个节点间以一个单箭头连接在一起,表示其中一个节点是因,另一个是果。以下图为例,smoking表示吸烟,其概率用P(S)表示;lung Cancer表示肺癌,一个人在吸烟的情况下得肺癌的概率用P(C|S)表示,X-ray表示需要照医学上的X光,肺癌可能会导致需要照X光,吸烟也有可能会导致需要照X光(所以smoking也是X-ray的一个因),所以,因吸烟且得肺癌而需要照X光的概率用P(X|C,S)表示。
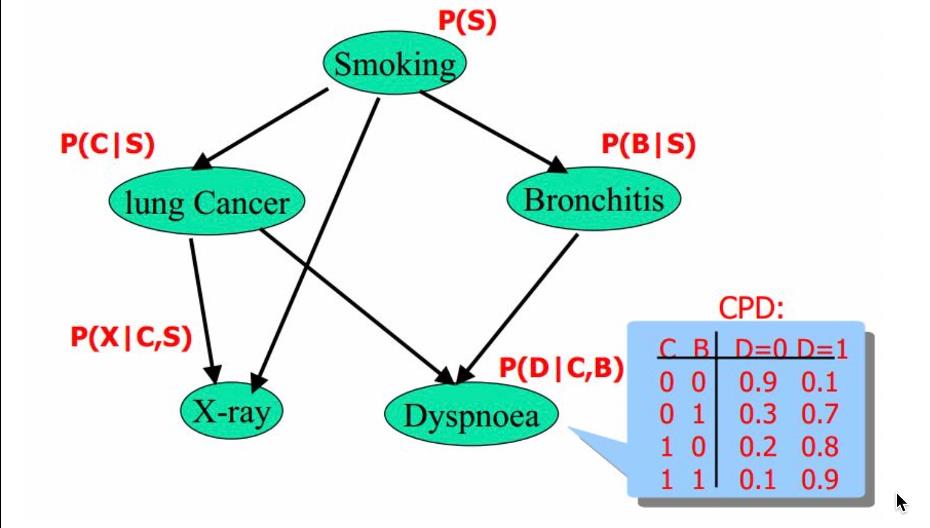
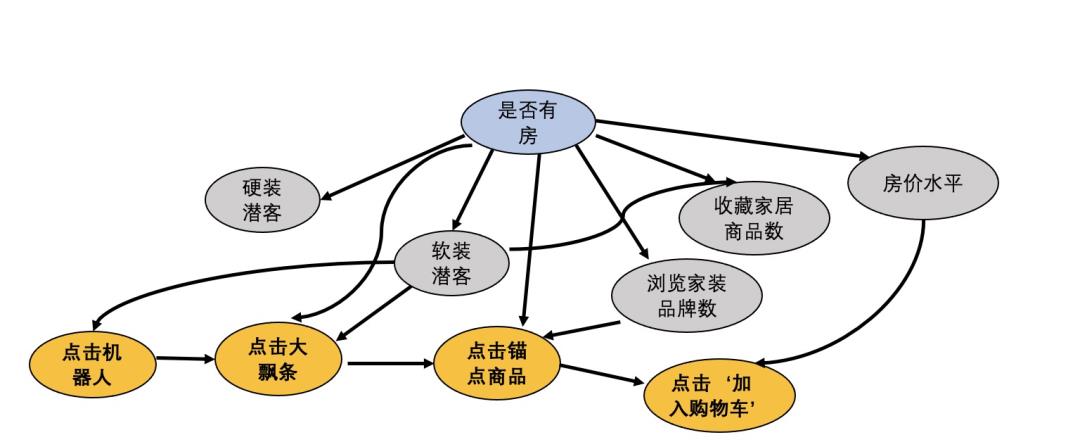
用户在3D样板间里会产生大量复杂行为,包括点击商品锚点、切换场景、切换风格等等,而只有‘点击了商品并完成加购/购买’是完成样板间的价值实现。因此我们通过计算用户行为事件间的贝叶斯概率矩阵,推导出贝叶斯因果图,找到用户关键事件节点的根因行为。
考虑到特征覆盖度和用户使用频次,最终选取了10+样板间内行为特征和20+用户特征&偏好,并据此画出了因果图。大部分的因果链都是符合逻辑的,例如年龄指向结婚,结婚指向生育,收入指向有无房产等。它也揭示了一些有意义的箭头,我们据此给出了一定的建议,比如:
‘有房’标签非常重要 ,是很多样板间内行为特征的‘因’。建议围绕‘有房’特征做好人群圈选,精准投放;
用户对于新手引导的完成度高:新手引导的每一环都被保留在因果图上。但是当前的行为链路止步于‘切换房间’,没有引导用户至点击商品这一重度行为,建议完善;
在新手引导链路改造完成后,在引导完成率不降低的情况下,用户的加购率提升了28.93%。
离线因果推断验证了3D样板间的价值。在分析了对照组人群的运营可落地性后,我们转向了实时线上因果策略输出,从类目,商家,用户多个维度提供运营策略。
PSM输出的对照组人群,由于和实验组‘同质’,也可以被认为是样板间的潜力人群。我们对这一波潜客进行了随机分组,在淘宝搜索页上进行在线实验:
页面中部为主搜云卡片
基于双重差分法 - 计算业务增量价值:
双重差分法:在满足基线期平行趋势假设的基础上,估计策略影响的平均处理效应。以下图为例,两家开在不同地区的店铺A/B,假设店铺A,B 满足平行趋势假设,且A家参与了大促(打广告),B家没有。考虑到时间变量对于两个店铺带来的共同影响,需要求两次差值才能正确估计广告对A带来的效益提升,即所谓双重差分。DID = (A2-A1)-(B2-B1),也可以用模型来拟合DID。
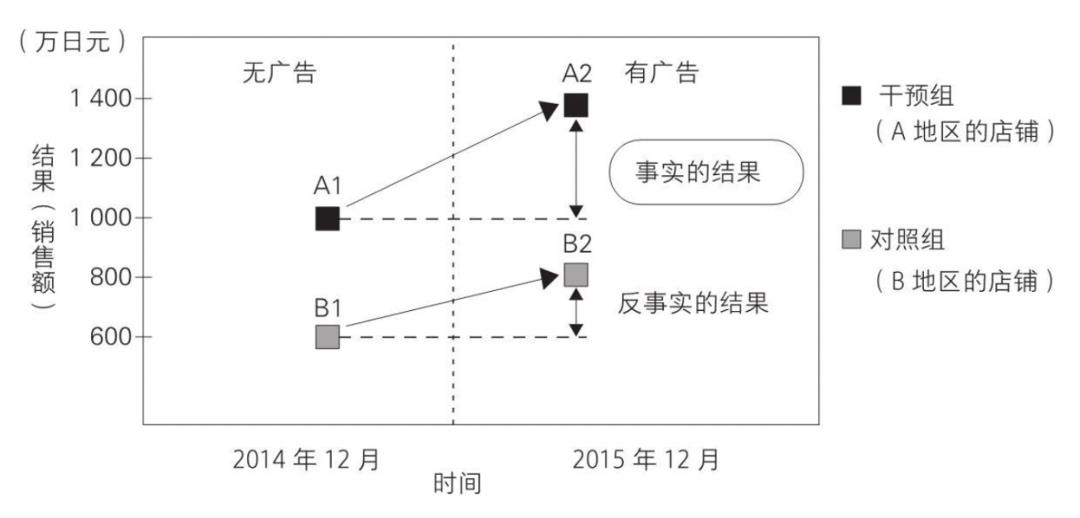
在3D样板间的case中,因为潜客是用PSM挖掘后再随机分组的,所以认为满足平行趋势假设,DID可行;
PSM+DID也是常见的搭配,一起使用可以避开各自的局限性,起到1+1>2的效果;在后续的文章会展开。
通过DID计算线上3周的实验数据表明,加购率提升了6.73%,加购件数提升了1.26件,淘宝时长增长了17.26分钟。
总结
观察性因果推断方法有很多,文章主要介绍了PSM、贝叶斯概率图、DID这几种方法,可将文章分享的实践方法作为因果推断分析中的一种参考。 观察性因果推断仍有许多局限之处,数据驱动产品任重道远。不迷信任何一种算法,多种分析方法论的结合+实际经验方为上策。希望这篇文章可以起到抛砖引玉的作用,引起大家对因果推断的兴趣,引发更多讨论,一起学习、共同成长。也希望可以认识一些正在做因果推断的小伙伴。
参考资料
Judea P, & Dana M.. The Book of Why.
Hernán, M. A., & Robins, J. M. Causal Inference: What If.
王乐. 概率图模型之贝叶斯网络. https://zhuanlan.zhihu.com/p/30139208
有哪些相关性不等于因果性的例子?. (n.d.). https://www.zhihu.com/question/66895407
Caliendo, M., & Kopeinig, S. (2008). Some Practical Guidance for the Implementation of PSM. Journal of Economic Surveys, 31–72(22(1)).
imai, K., Keele, L., Tingley, D., & Yamamoto, T. (2011). Unpacking the Black Box of Causality: Learning about Causal Mechanisms from Experimental and Observational Studies. American Political Science Review, 105(4).
团队介绍
大淘宝技术-家装家居数据科学团队基于淘系全域数据,利用多维分析、归因分析、运筹优化、博弈论、因果推断等分析和挖掘方法,设计合适的分析和算法解决方案,对淘宝,天猫家装家居垂直行业的权益效率提升、用户留存等问题建模分析,实验用户规模及用户粘性的增长。
✿ 拓展阅读

作者|亦歌、行週
编辑|橙子君


以上是关于因果推断实战:淘宝3D化价值分析小结的主要内容,如果未能解决你的问题,请参考以下文章