因果推断笔记——因果图建模之微软开源的dowhy
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了因果推断笔记——因果图建模之微软开源的dowhy相关的知识,希望对你有一定的参考价值。
文章目录
1 dowhy介绍

github地址:microsoft/dowhy
dowhy 文档:DoWhy | An end-to-end library for causal inference
1.1 dowhy的分析流程
参考材料:
因果推断框架 DoWhy 入门
如果有的东西是不可以验证的呢?比如我们的人生,如果当初的你去了不同的城市学校公司,那人生肯定不同了,然而有什么时光倒流的模型吗?
DoWhy使用贝叶斯网络模型框架,用户可以在其中指定他们对数据生成过程的了解以及不了解的信息。为了进行estimation,作者提供了基于potential-outcomes框架的方法,例如匹配,分层和工具变量。
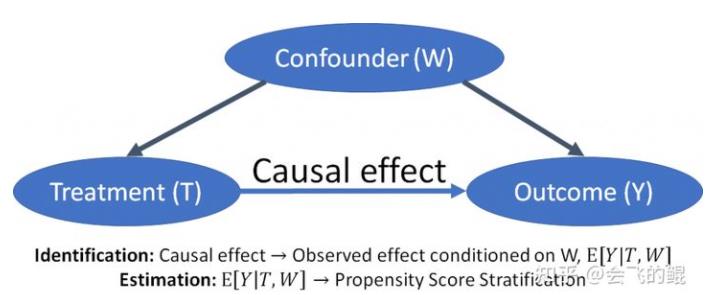
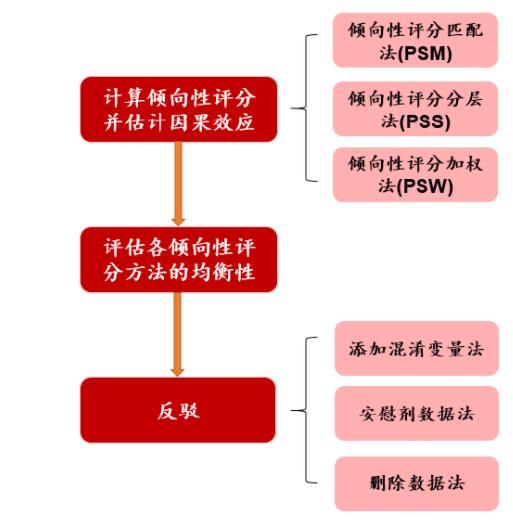
DoWhy 的整个因果推断过程可以划分为四大步骤:
步骤一:「因果图建模」(model):
利用假设(先验知识)对因果推断问题建模,构建基础的因果图,你可以只提供部分图,来表示某些变量的先验知识(即指定其类型),DoWhy 支持自动将剩余的变量视为潜在的混杂因子。
步骤二:「因果图表达式再识别」(identify):
在假设(模型)下识别因果效应的表达式(因果估计量),准则:
- 「后门准则」(Back-door criterion)
- 「前门准则」(Front-door criterion)
- 「工具变量」(Instrumental Variables)
- 「中介-直接或间接结果识别」(Mediation-Direct and indirect effect identification)
步骤三:「因果效应估计」(estimate):
使用统计方法对表达式进行估计,识别之后的估计
- 「基于估计干预分配的方法」
- 基于倾向的分层(Propensity-based Stratification)
- 倾向得分匹配(Propensity Score Matching)
- 逆向倾向加权(Inverse Propensity Weighting)
- 「基于估计结果模型的方法」
- 线性回归(Linear Regression)
- 广义线性模型(Generalized Linear Models)
- 「基于工具变量等式的方法」
- 二元工具/Wald 估计器(Binary Instrument/Wald Estimator)
- 两阶段最小二乘法(Two-stage least squares)
- 非连续回归(Regression discontinuity)
- 「基于前门准则和一般中介的方法」
- 两层线性回归(Two-stage linear regression)
此外,DoWhy 还支持调用外部的估计方法,例如 EconML 与 CausalML。
步骤四:「反驳」(refute)
使用各种鲁棒性检查来验证估计的正确性
- 「添加随机混杂因子」:添加一个随机变量作为混杂因子后估计因果效应是否会改变(期望结果:不会)
- 「安慰剂干预」:将真实干预变量替换为独立随机变量后因果效应是否会改变(期望结果:因果效应归零)
- 「虚拟结果」:将真实结果变量替换为独立随机变量后因果效应是否会改变(期望结果:因果效应归零)
- 「模拟结果」:将数据集替换为基于接近给定数据集数据生成过程的方式模拟生成的数据集后因果效应是否会改变(期望结果:与数据生成过程的效应参数相匹配)
- 「添加未观测混杂因子」:添加一个额外的与干预和结果相关的混杂因子后因果效应的敏感性(期望结果:不过度敏感)
- 「数据子集验证」:将给定数据集替换为一个随机子集后因果效应是否会改变(期望结果:不会)
- 「自助验证」:将给定数据集替换为同一数据集的自助样本后因果效应是否会改变(期望结果:不会)
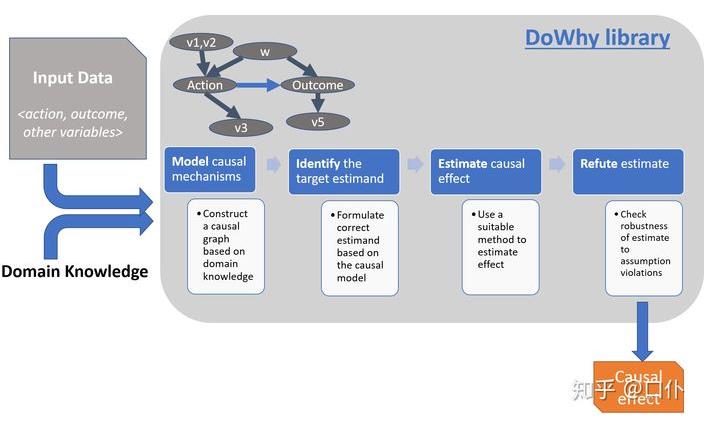
2 案例
参考材料:
因果推断框架 DoWhy 入门
2.1 数据获取与整理
下面将通过一个基于真实世界数据的案例对 DoWhy 的工作流程进行进一步说明。在本例中,我们的研究问题是估计当消费者在预定酒店时,为其分配一间与之前预定过的房间不同的房间对消费者取消当前预定的影响。分析此类问题的金标准是「随机对照试验」(Randomized Controlled Trials),即每位消费者被随机分配到两类干预中的一类:为其分配与之前预定过的房间相同或不同的房间。
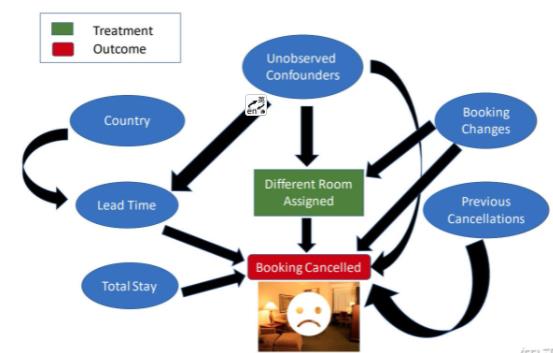
is_cancelled是Y;
干预,treatment/V 是换一个房间;
其他都是混淆变量W
然而,实际上对于酒店来说其不可能进行这样的试验,只能使用历史数据(观察性数据)来进行评估。我们首先导入相关包与数据集:
数据集处理:
import dowhy
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import logging
logging.getLogger("dowhy").setLevel(logging.INFO)
dataset = pd.read_csv('https://raw.githubusercontent.com/Sid-darthvader/DoWhy-The-Causal-Story-Behind-Hotel-Booking-Cancellations/master/hotel_bookings.csv')
dataset.columns
# Total stay in nights
dataset['total_stay'] = dataset['stays_in_week_nights']+dataset['stays_in_weekend_nights']
# Total number of guests
dataset['guests'] = dataset['adults']+dataset['children'] +dataset['babies']
# Creating the different_room_assigned feature
dataset['different_room_assigned']=0
slice_indices =dataset['reserved_room_type']!=dataset['assigned_room_type']
dataset.loc[slice_indices,'different_room_assigned']=1
# Deleting older features
dataset = dataset.drop(['stays_in_week_nights','stays_in_weekend_nights','adults','children','babies'
,'reserved_room_type','assigned_room_type'],axis=1)
dataset.isnull().sum() # Country,Agent,Company contain 488,16340,112593 missing entries
dataset = dataset.drop(['agent','company'],axis=1)
# Replacing missing countries with most freqently occuring countries
dataset['country']= dataset['country'].fillna(dataset['country'].mode()[0])
dataset = dataset.drop(['reservation_status','reservation_status_date','arrival_date_day_of_month'],axis=1)
dataset = dataset.drop(['arrival_date_year'],axis=1)
# Replacing 1 by True and 0 by False for the experiment and outcome variables
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(1,True)
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(0,False)
dataset['is_canceled']= dataset['is_canceled'].replace(1,True)
dataset['is_canceled']= dataset['is_canceled'].replace(0,False)
dataset.dropna(inplace=True) # 新增对NA值的处理
dataset.columns
2.2 如何简单证明变量之间的因果关系
非常简单的看Y ~ X随机抽取中,多少会是相等的,如果100%相等,大概率X-> Y;
如果50%那就不确定有无因果关系
针对目标变量 is_cancelled 与 different_room_assigned ,我们随机选取 1000 次观测查看有多少次上述两个变量的值相同(即可能存在因果关系)
检查的方法:
# different_room_assigned - 518 不确定因果关系
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset.sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
# 预约变化 booking_changes - 492,不确定
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]==0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
2.3 步骤一:因果图建模
import pygraphviz
model= dowhy.CausalModel(
data = dataset,
graph=causal_graph.replace("\\n", " "),
treatment='different_room_assigned',
outcome='is_canceled')
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
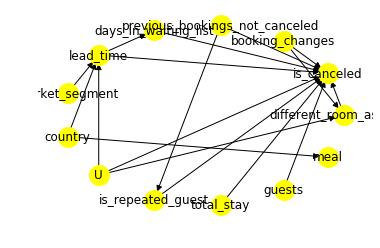
2.4 步骤二:识别
我们称「干预」(Treatment)导致了「结果」(Outcome)当且仅当在其他所有状况不变的情况下,干预的改变引起了结果的改变。因果效应即干预发生一个单位的改变时,结果变化的程度。下面我们将使用因果图的属性来识别因果效应的估计量。
#Identify the causal effect
identified_estimand = model.identify_effect()
print(identified_estimand)
输出结果:
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|days_in_waiting_list,bookin
d[different_room_assigned]
g_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lea
d_time,market_segment,guests,country))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lead_time,market_segment,guests,country,U) = P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lead_time,market_segment,guests,country)
### Estimand : 2
Estimand name: iv
No such variable found!
### Estimand : 3
Estimand name: frontdoor
No such variable found!
这里的输出结果其实满费解的,包含了后门准则检验、前门准则检验、IV工具变量检验三个;
主要的目的是了解当下因果图里面的变量之间的结构关系
- 如果存在后门准则的变量,就跟现在这样,那么说明T-> Y之间有混淆变量是在两者的后门路径上,那么这些W变量都会直接影响T/Y;
- 前门准则,案例中没有,如果有,则说明存在变量是,T -> Z -> Y,是在T-Y的前门路径上,会起到“中介”的效果
2.5 步骤三:估计因果效应
因果效应即干预进行单位改变时结果的变化程度。DoWhy 支持采用各种各样的方法计算因果效应估计量(回归系数),并最终返回单个平均值。
代码如下所示:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_stratification",target_units="ate")
print(estimate)
来看看估计方法method_name有几种类型:
* Propensity Score Matching: "backdoor.propensity_score_matching"
* Propensity Score Stratification: "backdoor.propensity_score_stratification"
* Propensity Score-based Inverse Weighting: "backdoor.propensity_score_weighting"
* Linear Regression: "backdoor.linear_regression"
* Generalized Linear Models (e.g., logistic regression): "backdoor.generalized_linear_model"
* Instrumental Variables: "iv.instrumental_variable"
* Regression Discontinuity: "iv.regression_discontinuity"
倾向性评分法的几种方法都有:PSM / PSS / PSW,
额外的还有线性回归 、 logistic回归、工具变量法等。
target_units因果效应的类型有ATE / ATT/ ATC :
# ATE = Average Treatment Effect
# ATT = Average Treatment Effect on Treated (i.e. those who were assigned a different room)
# ATC = Average Treatment Effect on Control (i.e. those who were not assigned a different room)
估计平均干预效应(ATE),也可以选择估计干预组(ATT)或对照组(ATC)的因果效应
来看一下整体的输出的结果为:
*** Causal Estimate ***
## Identified estimand
Estimand type: nonparametric-ate
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
──────────────────────────(Expectation(is_canceled|days_in_waiting_list,bookin
d[different_room_assigned]
g_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lea
d_time,market_segment,guests,country))
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lead_time,market_segment,guests,country,U) = P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,total_stay,is_repeated_guest,previous_bookings_not_canceled,meal,lead_time,market_segment,guests,country)
## Realized estimand
b: is_canceled~different_room_assigned+days_in_waiting_list+booking_changes+total_stay+is_repeated_guest+previous_bookings_not_canceled+meal+lead_time+market_segment+guests+country
Target units: ate
## Estimate
Mean value: -0.3354060769218102
ate 平均估计效应,估计方法选择的是「倾向得分匹配」,所以的含义是,different_room_assigned = 1 比 different_room_assigned = 0取消的概率,
也就是说,换房间(different_room_assigned = 1 )比不换房间(different_room_assigned = 0 ),取消概率高33.5%
2.6 反驳结果
反驳的过程就是检验最终结果的过程,就跟回归系数还需要P检验一样。
我们需要验证假设的正确性。DoWhy 支持通过各种各样的鲁棒性检查方法来测试假设的正确性。下面进行其中几项测试:
**「添加随机混杂因子」。**如果假设正确,则添加随机的混杂因子后,因果效应不会变化太多。
refute1_results=model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")
print(refute1_results)
Refute: Add a Random Common Cause
Estimated effect:-0.3359905635051836
New effect:-0.3365742386420179 # 基本保持稳定
结果解读:
修改之后的New effect估计量为-0.3365742386420179,与之前的model.estimate_effect估计的Estimated effect为-0.3354060769218102,差不多
**「安慰剂干预」。**将干预替换为随机变量,如果假设正确,因果效应应该接近 0。
refute2_results=model.refute_estimate(identified_estimand, estimate,
method_name="placebo_treatment_refuter")
print(refute2_results)
Refute: Use a Placebo Treatment
Estimated effect:-0.3359905635051836
New effect:-0.00028277666065981027 # 因果效应归零
p value:0.43999999999999995
结果解读:
new effect 结果约等于0,属于正常范围;这种方法含义就是,随便给你整点数,你要是跟这些数字都有关系,那你之前的因果关系就很有问题了。
「数据子集验证」。在数据子集上估计因果效应,如果假设正确,因果效应应该变化不大。
refute3_results=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter")
print(refute3_results)
Refute: Use a subset of data
Estimated effect:-0.3359905635051836
New effect:-0.33647521997465524
p value:0.35
结果解读:
我们的因果模型基本可以通过上述几个测试(即取得预期的结果)。因此,根据估计阶段的结果,我们得出结论:当消费者在预定房间时,为其分配之前预定过的房间( different_room_assigned = 0 )所导致的平均预定取消概率( is_canceled )要比为其分配不同的房间( different_room_assigned = 1 )低 「33%」。
2.7 与普通ML分类模型比较特征重要性
# plot feature importance using built-in function
from xgboost import XGBClassifier
from xgboost import plot_importance
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from matplotlib import pyplot
# split data into X and y
X = dataset_copy # 这里使用的是copy,请自行复制(处理完后的数据)
y = dataset_copy['is_canceled']
X = X.drop(['is_canceled'],axis=1)
# One-Hot Encode the dataset
X = pd.get_dummies(X)
# split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=26)
# fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
# make predictions for test data and evaluate
y_pred = model.predict(X_test)
predictions = [int(value) for value in y_pred] # 注意这里之前用的是round,会报错
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
print(classification_report(y_test, predictions))
给出特征重要性
# plot feature importance
plot_importance(model,max_num_features=20)
pyplot.show()
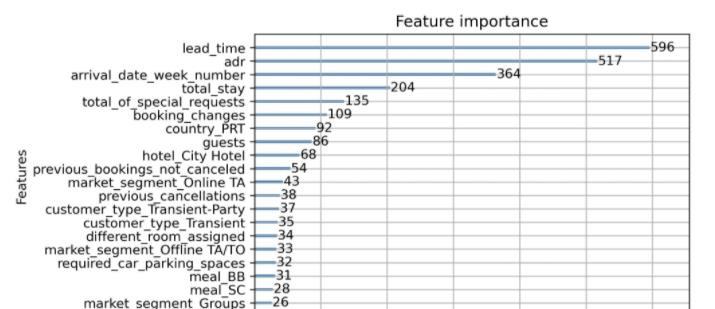
可以看出,different_room_assigned 变量的特征权重并不是非常高,这与我们的因果推断结果有一定的差异性,这也体现了因果推断模型和传统机器学习模型在原理上的差异性,我们需要根据实际的需要来选择最合适的方法。
以上就是 DoWhy 入门的全部内容,总的来看, DoWhy 为因果推断研究提供了一个非常方便的工具,研究人员需要做的就是先对数据进行分析并给出适当的假设(可以是多个),然后将数据输入到 DoWhy 提供的框架中进行自动化估计(需要指定估计方法与估计目标),最后对估计的结果进行鲁棒性测试以验证假设的正确性,即可得出较为合理的因果关系推论。
以上是关于因果推断笔记——因果图建模之微软开源的dowhy的主要内容,如果未能解决你的问题,请参考以下文章