R语言基础-数学&统计&概率&字符串处理函数|自定义函数|流程控制语句
Posted qq_21478261
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言基础-数学&统计&概率&字符串处理函数|自定义函数|流程控制语句相关的知识,希望对你有一定的参考价值。
本文速览

1、R数学函数
函数 解释
abs(x) 绝对值
abs(-4) 返回值为 4
sqrt(x) 平方根
sqrt(25) 返回值为 5,和 25^(0.5)等价
ceiling(x) 不小于 x 的最小整数
ceiling(3.475) 返回值为 4
floor(x) 不大于 x 的最大整数
floor(3.475) 返回值为 3
trunc(x) 向 0 的方向截取的 x 中的整数部分,trunc(5.99)返回值为 5
round(x, digits=n) 将 x 舍入为指定位的小数,round(3.475, digits=2)返回值为 3.48
signif(x, digits=n) 将 x 舍入为指定的有效数字位数,signif(3.475, digits=2)返回值为 3.5
cos(x)、sin(x)、tan(x) 余弦、正弦和正切,cos(2)返回值为–0.416
acos(x)、asin(x)、atan(x) 反余弦、反正弦和反正切,acos(-0.416)返回值为 2
cosh(x)、sinh(x)、tanh(x) 双曲余弦、双曲正弦和双曲正切,sinh(2)返回值为 3.627
acosh(x)、asinh(x)、atanh(x) 反双曲余弦、反双曲正弦和反双曲正切,asinh(3.627)返回值为 2
log(x,base=n) 对 x 取以 n 为底的对数
log(x)
log10(x)
为了方便起见:
• log(x)为自然对数
• log10(x)为常用对数
• log(10)返回值为 2.3026
• log10(10)返回值为 1
exp(x) 指数函数,exp(2.3026)返回值为 102、R统计函数
函数 解释
mean(x) 平均数
mean(c(1,2,3,4)) 返回值为 2.5
median(x) 中位数
median(c(1,2,3,4)) 返回值为 2.5
sd(x) 标准差,sd(c(1,2,3,4)) 返回值为 1.29
var(x) 方差,var(c(1,2,3,4))返回值为 1.67
mad(x) 绝对中位差(median absolute deviation),mad(c(1,2,3,4))返回值为 1.48
quantile(x,probs) 求分位数。其中 x 为待求分位数的数值型向量,probs 为一个由[0,1]之间的概率值组成的数值向量,# 求 x 的 30%和 84%分位点y <- quantile(x, c(.3,.84))
range(x) 求值域,x <- c(1,2,3,4) ,range(x)返回值为 c(1,4)
diff(range(x)) 返回值为 3
sum(x) 求和,sum(c(1,2,3,4))返回值为 10
diff(x, lag=n) 滞后差分,lag 用以指定滞后几项。默认的 lag 值为 1 ,x<- c(1, 5, 23, 29) ,diff(x)返回值为 c(4, 18, 6)
min(x) 求最小值,min(c(1,2,3,4))返回值为 1
max(x) 求最大值,max(c(1,2,3,4))返回值为 4
scale(x,center=TRUE,scale=TRUE) 为数据对象 x 按列进行中心化(center=TRUE)或标准化,(center=TRUE,scale=TRUE);3、R概率函数
概率分布 缩写
Beta分布 beta
二项分布 binom
柯西分布 cauchy
(非中心)卡方分布 chisq
指数分布 exp
F分布 f
Gamma分布 gamma
几何分布 geom
超几何分布 hyper
对数正态分布 lnorm Wilcoxon
Logistic分布 logis
多项分布 multinom
负二项分布 nbinom
正态分布 norm
泊松分布 pois
Wilcoxon符号秩分布 signrank
t分布 t
均匀分布 unif
Weibull分布 weibull
秩和分布 wilcox4、R字符处理函数
函 数 描 述
nchar(x) 计算 x 中的【字符】数量
x <- c("ab", "cde", "fghij")
length(x) 返回值为 3
nchar(x[3]) 返回值为 5
substr(x, start, stop) 提取或替换一个字符向量中的子串
x <- "abcdef"
substr(x, 2, 4)返回值为"bcd"
substr(x, 2, 4) <- "22222"(x 将变成"a222ef")
grep(pattern, x, ignore.case=FALSE, fixed=FALSE) 在 x 中搜索某种模式。
若 fixed=FALSE,则 pattern 为一个正则表达式。若fixed=TRUE,则 pattern 为一个文本字符串。返回值为匹配的下标grep("A",c("b","A","c"),fixed=TRUE)返回值为 2
sub(pattern, replacement,x, ignore.case=FALSE,fixed=FALSE)
在 x 中搜索 pattern,并以文本 replacement 将其替换。
若 fixed=FALSE,则pattern 为一个正则表达式。若 fixed=TRUE,则 pattern 为一个文本字符串。
sub("\\\\s",".","Hello There")返回值为 Hello.There。注意, "\\s"是一个用来查找空白的正则表达式;使用"\\\\s"而不用"\\"的原因是,后者是 R 中的转义字符(参见 1.3.3 节)
strsplit(x, split,fixed=FALSE) 在 split 处分割字符向量 x 中的元素。
若 fixed=FALSE,则 pattern 为一个正则表达式。若 fixed=TRUE,则 pattern 为一个文本字符串
y <- strsplit("abc", "")将返回一个含有 1 个成分、 3 个元素的列表,包含的内容为"a" "b" "c"unlist(y)[2]和 sapply(y, "[", 2)均会返回"b"
paste(…, sep="") 连接字符串,分隔符为 sep
paste("x", 1:3,sep="")返回值为 c("x1", "x2", "x3")
paste("x",1:3,sep="M")返回值为 c("xM1","xM2" "xM3")
paste("Today is", date())返回值为 'Today is Fri Sep 11 13:14:41 2020'
toupper(x) 写转换
toupper("abc") 返回值为"ABC"
tolower(x) 小写转换
tolower("ABC") 返回值为"abc"5、R其他函数
函数 描述
length(x) 对象 x 的长度
x <- c(2, 5, 6, 9)
length(x)返回值为 4
seq(from, to, by) 生成一个序列
indices <- seq(1,10,2)
indices 的值为 c(1, 3, 5, 7, 9)
rep(x, n) 将 x 重复 n 次
y <- rep(1:3, 2)
y 的值为 c(1, 2, 3, 1, 2, 3)
cut(x, n) 将连续型变量 x 分割为有着 n 个水平的因子
使用选项 ordered_result = TRUE 以创建一个有序型因子
pretty(x, n) 创建美观的分割点。通过选取 n+1 个等间距的取整值,将一个连续型变量 x
分割为 n 个区间。绘图中常用
cat(... , file ="myfile", append =FALSE) 连接...中的对象,并将其输出到屏幕上或文件中(如果声明了一个的话)
firstname <- c("Jane")
cat("Hello" ,firstname, "\\n")6、以上函数使用举例
将学生的各科考试成绩组合为单一的成绩衡量指标,基于相对名次(前20%、下20%、等等)给出从A到F的评分,根据学生姓氏和名字的首字母对花名册进行排序。
- 创建data.frame
options(digits=2)#格式化输出,设置小数位数
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
"David Jones", "Janice Markhammer", "Cheryl Cushing",
"Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, Math, Science, English,stringsAsFactors=FALSE)
- 数据标准化
Math,Science,English三科成绩总分不一(均值和标准差相去甚远),直接无法比,使用单位标准差(R中scale函数)来标准化各科成绩。

z <- scale(roster[,2:4])#数学、科学和英语考试的分值不同(均值和标准差相去甚远),使用标准差标准化
z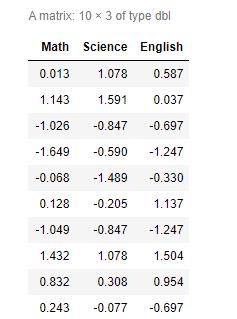
- 求行均值,列合并
score <- apply(z, 1, mean)#通过函数mean()来计算各行的均值以获得综合得分
roster <- cbind(roster, score)#并使用函数cbind(),列合并,将其添加到花名册中
- 求百分位数
#函数quantile()给出了学生综合得分的百分位数。可以看到,成绩为A的分界点为0.74, B的分界点为0.44,等等。
y <- quantile(score, c(.8,.6,.4,.2))
y
- 将score排名
##通过使用逻辑运算符,你可以将学生的百分位数排名重编码为一个新的类别型成绩变量。下面在数据框roster中创建了变量grade。
roster$grade[score >= y[1]] <- "A"#score大于等于80%(0.74)的成绩为A
roster$grade[score < y[1] & score >= y[2]] <- "B"
roster$grade[score < y[2] & score >= y[3]] <- "C"
roster$grade[score < y[3] & score >= y[4]] <- "D"
roster$grade[score < y[4]] <- "F"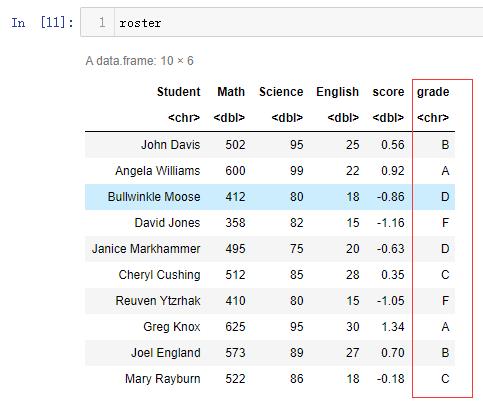
- 以空格为界拆分名字为姓和名
#函数strsplit(),以空格为分隔符将学生姓名拆分为姓氏和名字。 把strsplit()应用到一个字符串组成的向量上会返回一个列表:
name <- strsplit((roster$Student), " ")#以空格为界拆分名字为姓和名
#函数sapply()提取列表中每个成分的第一个元素,放入一个储存名字的向量Firstname,并提取每个成分的第二#个元素,放入一个储存姓氏的向量Lastname。 "["是一个可以提取某个对象的一部分的函数——在这里它是用来提#取列表name各成分中的第一个或第二个元素的。你将使用cbind()把它们添加到花名册中。由于已经不再需要student变量,可以将其丢弃(在下标中使用–1)
Lastname <- sapply(name, "[", 2)
Firstname <- sapply(name, "[", 1)
roster <- cbind(Firstname,Lastname, roster[,-1])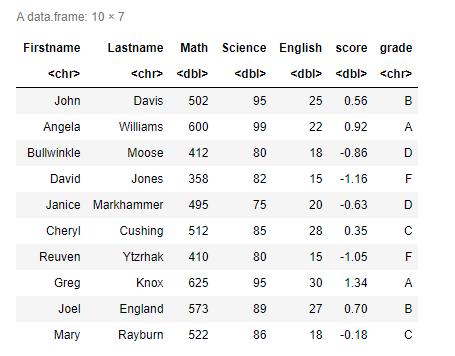
- 函数order()依姓氏和名字对数据集进行排序
roster <- roster[order(Lastname,Firstname),]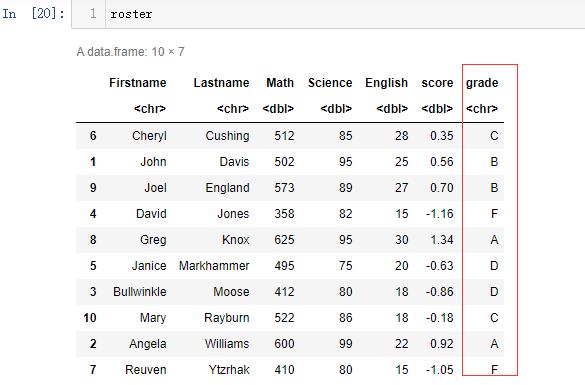
7、R中自定义函数
- 语法
myfunction <- function(arg1, arg2, ... )
statements
return(object)
- example
#此函数应当可以选择性地给出参数统计量(均值和标准差)和非参数统计量(中位数和绝对中位差)
##定义函数function,赋值给mystats
mystats <- function(x, parametric=TRUE, print=FALSE) # print=FALSE默认不输出结果
if (parametric) #if TRUE
center <- mean(x); spread <- sd(x)
else
center <- median(x); spread <- mad(x)
if (print & parametric) #if FALSE
cat("Mean=", center, "\\n", "SD=", spread, "\\n")
else if (print & !parametric) #if TRUE
cat("Median=", center, "\\n", "MAD=", spread, "\\n")
result <- list(center=center, spread=spread)
return(result)
##使用函数mystats
set.seed(1234)
x <- rnorm(500)
y <- mystats(x, parametric=FALSE, print=TRUE) 
8、R中流程控制语句
-
for
#语法:for (var in seq) statement#重复执行statement语句,直到变量不包含在序列seq中
for (i in 1:10) print("666")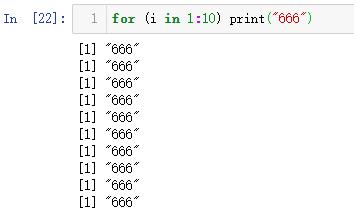
-
while
#语法:while (cond) statement#重复执行statement语句,直到cond不为真为止
i <- 10
while (i > 0) print("666"); i <- i - 1 
-
if
#语法:if (cond) statement
a <- c(1,2,3)
if (is.numeric(a))
print('666')
-
if else
#语法:if (cond) statement1 else statement2
a <- c(1,2,3)
if (is.character(a)) print('666')else print('nono')#if else不在一行报错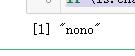
-
ifelse
# 语法:ifelse(cond, statement1, statement2)#cond为TRUE执行statement1 否则执行statement2
ifelse(is.character(a), print('666'),print('nono'))#类似python中三目运算符
-
switch
#switch根据一个表达式的值选择语句执行。语法为:
#switch(expr, ...),类似python字典,给keys,取values
feelings <- c("sad", "afraid")
for (i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
)
参考资料
r-in-action-second-edition
以上是关于R语言基础-数学&统计&概率&字符串处理函数|自定义函数|流程控制语句的主要内容,如果未能解决你的问题,请参考以下文章