机器学习分类算法之支持向量机
Posted 王小王-123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习分类算法之支持向量机相关的知识,希望对你有一定的参考价值。
目录
支持向量机算法背景介绍
1995年Cortes和Vapnik首先提出了支持向量机(Support Vector Machine),由于其能够适应小样本的分类,分类速度快等特点,性能不差于人工神经网络,所以在这之后,人们将SVM应用于各个领域。
大量使用SVM模型的论文不断涌现,包括国内和国外支持向量机建立在坚实的统计学理论基础上,是在所有知名的数据挖掘算法中最健壮、最准确的方法之一,具有很好的学习能力和泛化能力。
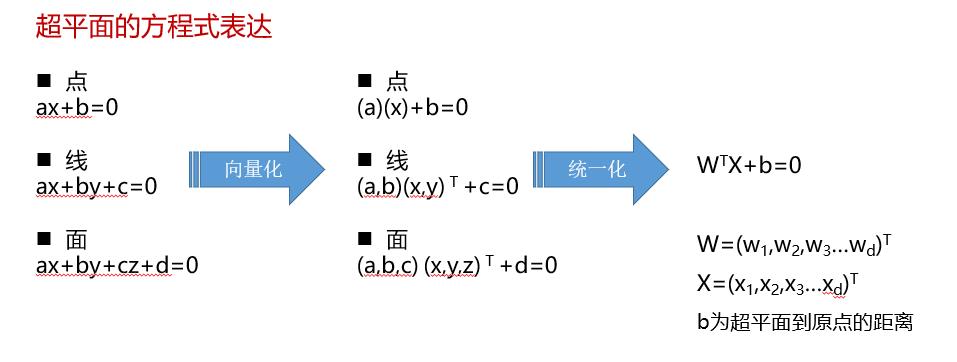
什么是线性可分?
简单说,线性可分就是在多维空间中存在一个超平面(Hyper Plane),可以把样例数据清楚地分成不同类别。二分类就是最典型的线性可分问题。

什么又是超平面?
超平面H是从n维空间到n-1维空间的一个映射子空间,它有一个n维向量和一个实数定义。因为是子空间,所以超平面一定过原点。
利用这种方式,我们可以看到即使再多维的情况下,也可以生成一种超平面用来进行分类

怎么正确理解超平面?
超平面是个纯数学概念,不是物理概念。它是直线中的点、平面中的直线、空间中的平面的推广,只有当维度大于3,才能称为“超”平面。
超平面的本质是自由度比空间维度小1,也即最后一个维度可以因其他维度确定而确定。
超平面的两个性质:
1)方程是线性的: 是空间点的各分量的线性组合
2)方程数量为1
说到这里,可能还是比较的懵逼,到底什么是超平面,超平面又该如何选择呢?我们可以看看下面的这个例子!
下面是一个二分类的问题,对于蓝点和黑点数据,事实上存在很多条直线可以把他们正确地划分开。那么究竟选择哪一条直线最佳呢?

我们发现存在三条特别的超平面(直线)。两条紫色的线分别距离蓝点和黑点最近,而红色的线则和两条紫线的距离相等。我们把两条紫线的距离称作间隔Margin

假如我们设定 g(X)=WTX+b为线性判别函数。对g(X)进行归一化,即令g1(X)=g(X)/c,也即W1=WT /c,b1=b/c,我们可以得到新的左图。
这也是,为什么支持向量机需要使用归一化,可以大幅度的提高模型的效果的原因


约束条件合并
对于上图而言:
1)蓝色样本点(y=+1)必定在直线W1TX+b1=+1上方,也即对所有蓝色样本点数据必定满足: W1TX+b1≥+1
2)黑色样本点(y=-1)必定在直线W1TX+b1=-1下面,也即对所有黑色样本点数据必定满足: W1TX+b1≤-1
我们把以上两个不等式合成一个,即:
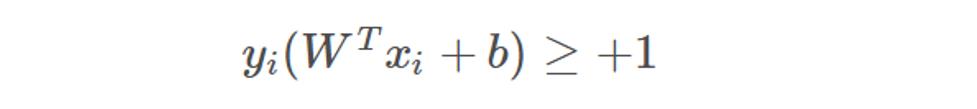
距离超平面最近的这几个样本点满足yi(WTxi+b)=1,它们被称为“支持向量”。虚线称为边界,两条虚线间的距离称为间隔(margin)。而间隔(margin)其实就是两个异类支持向量的差在法向量W方向的投影,故有:


经过了大量的铺垫工作之后,现在我们对支持向量机进行一个定义
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解:

支持向量机的三种情况
线性可分
线性可分指样本数据集可以找到一个线性函数或者超平面一分为二,这样的支持向量机又叫硬间隔(Hard Margin)支持向量机。求解过程如下:
1)使用拉格朗日乘子法得到其对偶问题:
2)分别对W和b求偏导,并令其等于0:
3)将(9)和(10)代回公式(8),消去之前W和b,原问题就转换成了关于α的问题
4)新的目标函数变成如下:
5)这样解出α之后,就可以根据公式(9)求W,进而求偏移量b
6)该过程的KKT条件为:
对于任意的训练样本 (xi,yi):
若 αi=0,则其不会在公式(13)中的求和项中出现,也就是说,它不影响模型的训练;
若 αi>0,则yif(xi)−1=0,也就是 yif(xi)=1,即该样本一定在边界上,是一个支持向量。这里显示出了支持向量机的重要特征:当训练完成后,大部分样本都不需要保留,最终模型只与支持向量有关。

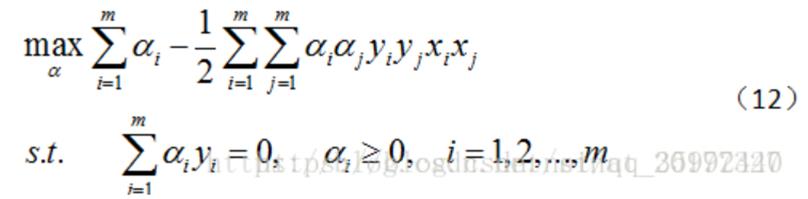
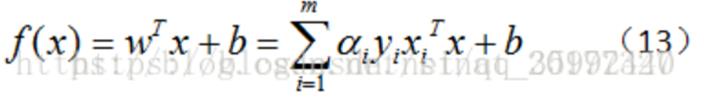

近线性可分
假如数据本身并非线性不可分的,只是因为噪声数据的存在,一些偏离正常位置很远的离群点数据(Outlier),使得数据线性不可分。
为解决这一问题,可以对每个样本点引入一个松弛变量 ξi≥0,使得间隔加上松弛变量大于等于1,这样处理后数据仍然可以实现线性可分,我们称之为近线性可分,这样的支持向量机也叫软间隔(Soft Margin)支持向量机。
这个时候,原问题的约束条件变成了:
同时,对于每一个松弛变量ξi≥0,支付一个代价 ξi≥0,目标函数变为:
其中 C>0为惩罚参数,C值大时对误分类的惩罚增大, C值小时对误分类的惩罚减小,公式(21)包含两层含义:使 ||W||2/2尽量小即间隔尽量大,同时使误分类点的个数尽量小,C是调和两者的系数。
有了公式(21),可以和线性可分支持向量机一样考虑线性支持向量机的学习过程

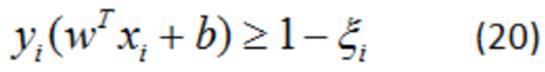

近线性可分求解过程
1)近线性支持向量机的学习问题变成如下凸二次规划问题的求解(原始问题):
2)对其使用拉格朗日函数,利用对偶问题求解,公式(22)的拉格朗日函数为:
其中 αi≥0,μi≥0是拉格朗日乘子。
3)令L(w,b,α,ξ,μ)对w,b,ξ的偏导数为0可得如下:
4)将公式(24)(25)(26)代入公式(23)得对偶问题:
5)上述过程的KKT条件为:
对于任意的训练样本 (xi,yi) ,总有 αi=0 或者yif(xi)−1+ξi=0:
1)若 αi=0,则其不会在公式(13)中的求和项中出现,也就是说,它不影响模型的训练; 2)若 αi>0,则yif(xi)−1+ξi=0,也就是 yif(xi)=1- ξi ,即该样本一定在边界上,是一个支持向量。结果跟线性可分SVM差不多,这个也是SVM算法的一大特色
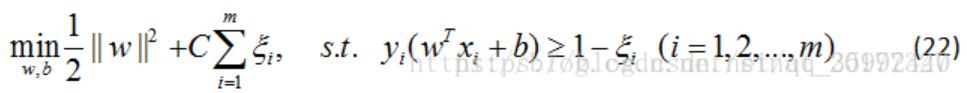
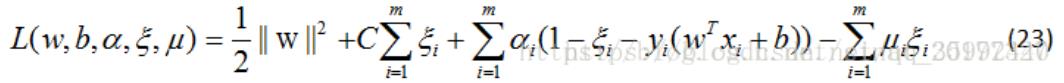

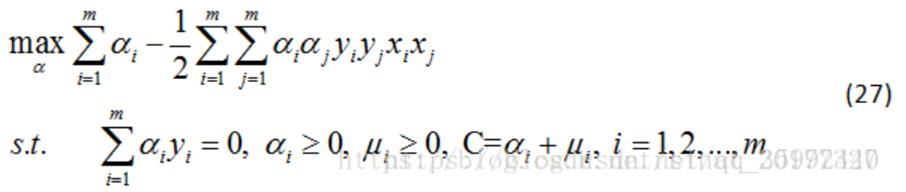

线性不可分
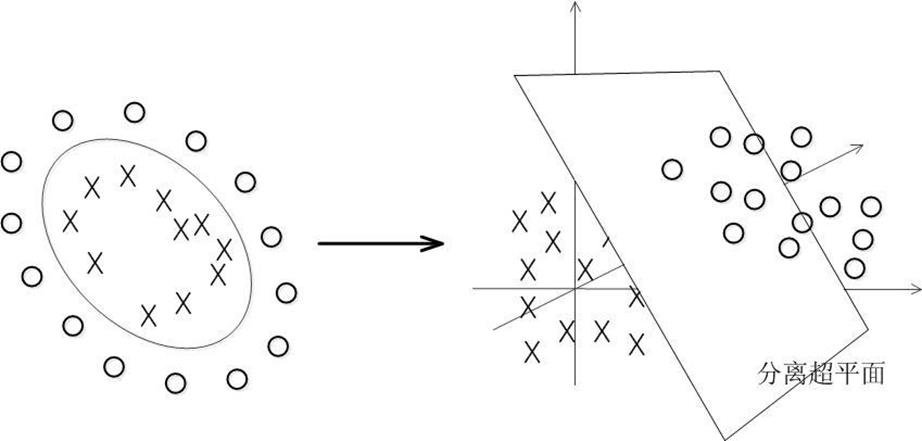
如果数据确实线性不可分,这个时候可以考虑把数据映射到更高维的空间,然后使得转换后的数据变得线性可分。
这个过程中,会引入一个核函数的概念,具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。
通俗易懂的来讲就是在多维空间里面利用多维曲面进行分类
不用核函数的传统方法
如果用原始的方法,那么在用线性学习器学习一个非线性关系,需要选择一个非线性特征集,并且将数据写成新的表达形式,这等价于应用一个固定的非线性映射,将数据映射到特征空间,在特征空间中使用线性学习器,因此,考虑的假设集是这种类型的函数:
这里ϕ:X->F是从输入空间到某个特征空间的映射,这意味着建立非线性学习器分为两步:
1)首先使用一个非线性映射将数据变换到一个特征空间F,
2)然后在特征空间使用线性学习器分类。
但这种方法随着维度的增长,存在很大的问题:
1)我们对一个二维空间构造一个非线性的曲面做映射,选择的新空间是原始空间的所有一阶和二阶的组合,那么会得到五个维度;
2)如果原始空间是三维(一阶、二阶和三阶的组合),那么我们会得到:3(一次)+3(二次交叉)+3(平方)+3(立方)+1(x1*x2*x3)+2*3(交叉,一个一次一个二次,类似x1*x2^2) = 19维的新空间,这个数目是呈指数级爆炸性增长的从而势必这给的计算带来非常大的困难。

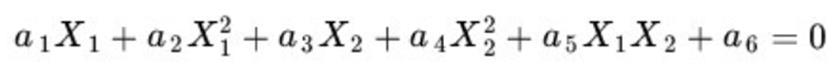
如果遇到无穷维的情况,就更加无从计算了。这个时候我们就必须引入Kernel核函数
核函数Kernel是什么?
核是一个特征空间的隐式映射,比如假定函数K,对所有x,z(-X,满足
核函数与传统的计算方式不同之处:
1、(传统)一个是映射到高维空间中,然后再根据内积的公式进行计算;
2、(核函数) 则直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果。
核函数SVM求解过程
1)令ϕ(x)\\phi (x)ϕ(x)表示将 x 映射后的特征向量,于是划分超平面所对应的的模型:
2)于是有最小化函数:
3)利用拉格朗日乘子法,求对偶问题:
4)若要对公式(16)求解,会涉及到计算 ϕ(xi)Tϕ(xj) 之后的内积,由于特征空间的维数可能很高,甚至是无穷维,因此直接计算 ϕ(xi)Tϕ(xj)通常是困难的,于是想到这样一个函数:
即 xi和xj在特征空间中的内积等于他们在原始样本空间中通过函数 κ(xi,xj) 计算的函数值,于是公式(16)写成如下:
最后得到
其中k(xi,xj)就是核函数,可以根据情况有多种选择





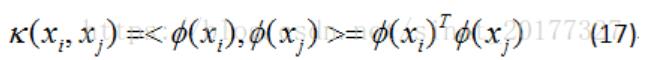



核函数的本质
1、实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(如之前那幅图线性不可分图所示,映射到高维空间后,相关特征便被分开了,也就达到了分类的目的);
2、但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(如上文中19维乃至无穷维的例子)。那咋办呢?
3、此时,核函数就隆重登场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
说到这里,相信差不多应该可以理解了吧,下面再去举一个例子
假设现在你是一个农场主,圈养了一批羊群,但为预防狼群袭击羊群,你需要搭建一个篱笆来把羊群围起来。但是篱笆应该建在哪里呢?你很可能需要依据牛群和狼群的位置建立一个“分类器”,比较下图这几种不同的分类器,我们可以看到SVM完成了一个很完美的解决方案。
显然,我们的SVM胜利了!
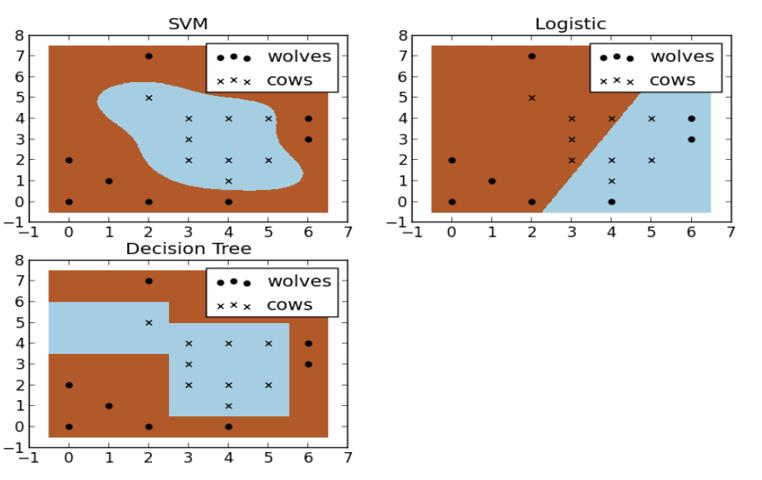
讲了这么多,其实就是在介绍支持向量机的本质,如果你认真的看完之后,你会发现,在支持向量机里面,最重要的两个参数就是C和核函数
支持向量机的优势在于:
( 1) 在高维空间中非常高效。
( 2) 即使在数据维度比样本数量大的情况下仍然有效。
( 3) 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的。
支持向量机的缺点包括:
( 1) 如果特征数量比样本数量大得多, 在选择核函数核函数时要避免过拟合。
( 2) 而且正则化项是非常重要的。
( 3) 支持向量机不直接提供概率估计, 这些都是使用昂贵的五次交叉验算计算的。
注意,这里很重要的,根据你选择的核函数,最终对数据是否需要预处理,下面我们就看看一个实例:
代码实例
导入第三方库
#导入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV #网格搜索
import matplotlib.pyplot as plt#可视化
import seaborn as sns#绘图包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler初次加载模型
# 加载模型
model = SVC()
# 训练模型
model.fit(X_train,y_train)
# 预测值
y_pred = model.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: :.4%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为::.4%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为::.4%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\\n',
classification_report(y_test,y_pred))
这里默认使用的是高斯核,但是我们的数据集范围并没有规约到[0,1]之间,由于数据集最先最好了离散化,所以造成的影响也不是很大,因为这里是初次加载
标准化
# 没有作用
# sc = StandardScaler()
# 标准化【0,1】
# 效果不行
sc=MinMaxScaler()
# sc=MaxAbsScaler()
X_train1 = sc.fit_transform(X_train)
X_test1 = sc.transform(X_test)
X_test1
使用标准化后的数据集进行预测
# 加载模型
model = SVC()
# 训练模型
model.fit(X_train1,y_train)
# 预测值
y_pred = model.predict(X_test1)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: :.4%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为::.4%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为::.4%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\\n',
classification_report(y_test,y_pred))
并不乐观,继续探索
模型调参
from datetime import time
import datetime
# ploy在该例中跑不出来
Kernel = ["linear", "rbf", "sigmoid","poly"]
for kernel in Kernel:
time0 = time()
clf = SVC(kernel=kernel,
gamma="auto",
cache_size=5000, # 允许使用的内存,单位为MB,默认是200M
).fit(X_train, y_train)
print("The accuracy under kernel %s is %f" % (kernel, clf.score(X_test, y_test)))
# print(datetime.datetime.fromtimestamp(time() - time0).strftime("%M:%S:%f"))
优先考虑多项式和高斯核
gamma调参
RBF调参
# 使用rbf,必须要对其进行数据缩放
# 画学习曲线
score = []
gamma_range = np.logspace(-10, 1, 50) # 返回在对数刻度上均匀间隔的数字
for i in gamma_range:
clf = SVC(kernel="rbf", gamma=i, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
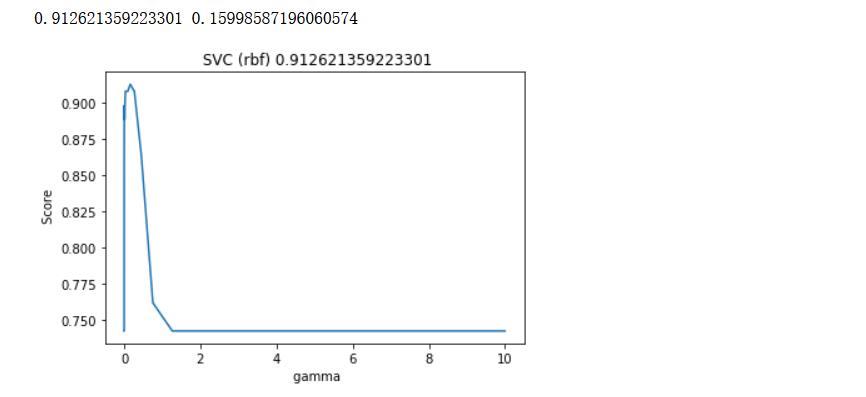
print(max(score), gamma_range[score.index(max(score))])
best_gamma_rbf=gamma_range[score.index(max(score))]
#设置标题
plt. title(f' SVC (rbf) max(score)')
#设置x轴标签
plt. xlabel(' gamma')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(gamma_range, score)
plt.show()
rbf核下的最佳gamma是0.1599......
poly调参
# 画学习曲线,数据不需要处理
score = []
gamma_range = np.logspace(-10, 1, 50) # 返回在对数刻度上均匀间隔的数字
for i in gamma_range:
clf = SVC(kernel="poly", gamma=i, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), gamma_range[score.index(max(score))])
best_gamma_poly=gamma_range[score.index(max(score))]
#设置标题
plt. title(f' SVC (poly) max(score)')
#设置x轴标签
plt. xlabel(' gamma')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(gamma_range, score)
plt.show()
效果上升了,感觉多项式核函数也还不错的

C值调参
# 调线性核函数
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="linear",C=i,cache_size=5000).fit(X_train,y_train)
score.append(clf.score(X_test, y_test))
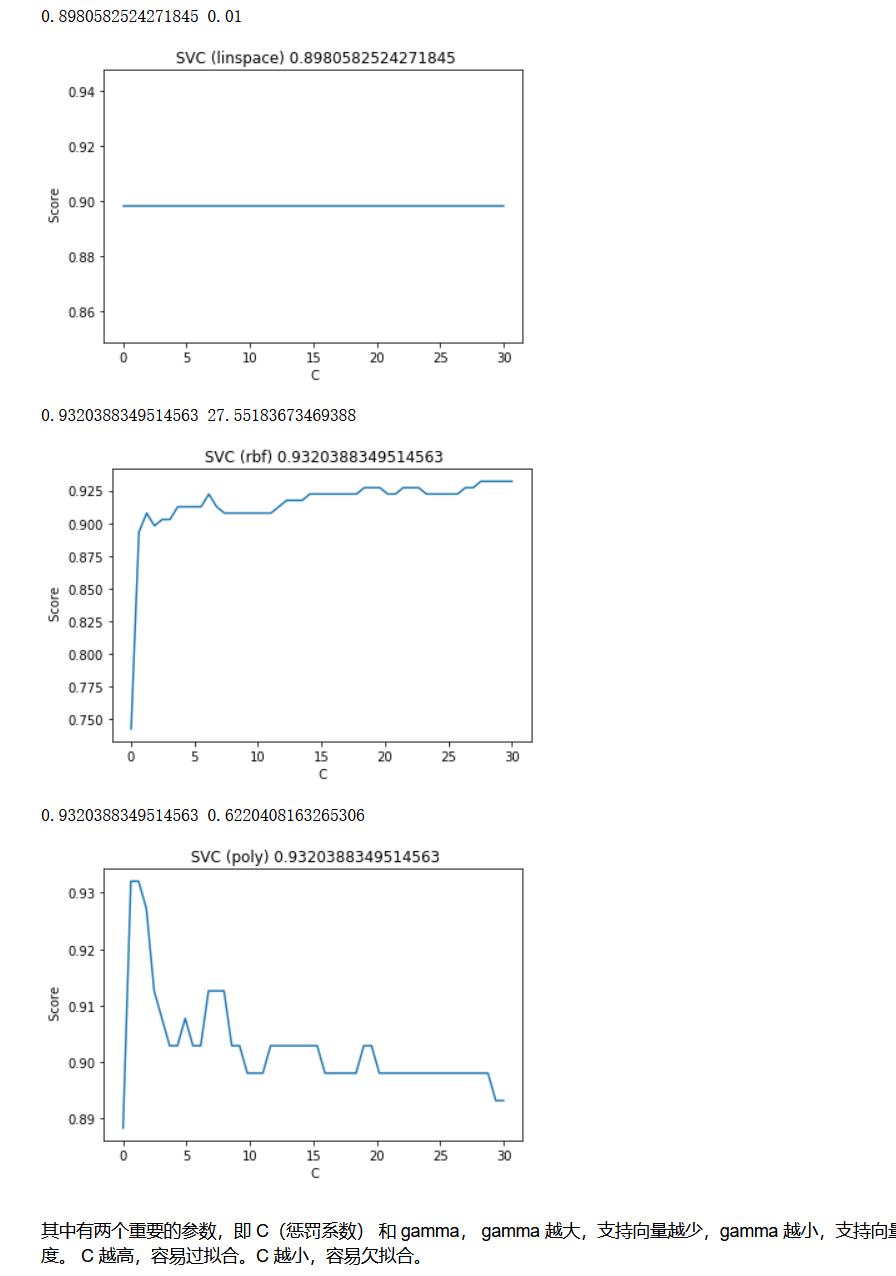
print(max(score), C_range[score.index(max(score))])
best_C_linear=C_range[score.index(max(score))]
#设置标题
plt. title(f' SVC (linspace) max(score)')
#设置x轴标签
plt. xlabel(' C')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(C_range, score)
plt.show()
# 换rbf,并且这里对数据进行了标准化,缩放到0和1之间的
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="rbf", C=i, gamma=0.15998587196060574, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C_rbf=C_range[score.index(max(score))]
#设置标题
plt. title(f' SVC (rbf) max(score)')
#设置x轴标签
plt. xlabel(' C')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(C_range, score)
plt.show()
# 换ploy
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = SVC(kernel="poly", C=i, gamma=0.0339322177189533, cache_size=5000).fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C_poly=C_range[score.index(max(score))]
#设置标题
plt. title(f' SVC (poly) max(score)')
#设置x轴标签
plt. xlabel(' C')
#设置y轴标签
plt. ylabel(' Score')
#添加图例
# plt. legend()
plt.plot(C_range, score)
plt.show()
看起来他们的分数不相上下(RBF和poly),根据他们的学习曲线,还是可以看出不一样的
使用Polynomial kernel进行预测
# 加载模型
model_1 = SVC(C=best_C_poly,gamma=best_gamma_poly,kernel='poly',cache_size=5000,degree=3,probability=True)
# 训练模型
model_1.fit(X_train,y_train)
# 预测值
y_pred = model_1.predict(X_test)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: :.4%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为::.4%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为::.4%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\\n',
classification_report(y_test,y_pred))from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 预测正例的概率
y_pred_prob=model_1.predict_proba(X_test)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()评估指标
ROC曲线AUC面积
模型效果还是不错,可以达到93%的准确率


使用RBF kernel进行预测
# 加载模型
model_2 = SVC(C=best_C_rbf,kernel='rbf',cache_size=5000,probability=True)
# 训练模型
model_2.fit(X_train1,y_train)
# 预测值
y_pred = model_2.predict(X_test1)
'''
评估指标
'''
# 求出预测和真实一样的数目
true = np.sum(y_pred == y_test )
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', y_test.shape[0]-true)
# 评估指标
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('预测数据的准确率为: :.4%'.format(accuracy_score(y_test,y_pred)*100))
print('预测数据的精确率为::.4%'.format(
precision_score(y_test,y_pred)*100))
print('预测数据的召回率为::.4%'.format(
recall_score(y_test,y_pred)*100))
# print("训练数据的F1值为:", f1score_train)
print('预测数据的F1值为:',
f1_score(y_test,y_pred))
print('预测数据的Cohen’s Kappa系数为:',
cohen_kappa_score(y_test,y_pred))
# 打印分类报告
print('预测数据的分类报告为:','\\n',
classification_report(y_test,y_pred))from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 预测正例的概率
y_pred_prob=model_2.predict_proba(X_test1)[:,1]
# y_pred_prob ,返回两列,第一列代表类别0,第二列代表类别1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真阳性标签,就是说是分类里面的好的标签,这个要看你的特征目标标签是0,1,还是1,2
roc_auc = metrics.auc(fpr, tpr) #auc为Roc曲线下的面积
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #横坐标是fpr
plt.ylabel('True Positive Rate') #纵坐标是tpr
plt.title('Receiver operating characteristic example')
plt.show()
效果也还是不错,虽然比poly稍微低一点,但是总体来说还是不错的

总结
本次使用支持向量机进行模型分类预测,并没有对其进行特征筛选,效果也是不错的,因为支持向量机的本质也会根据根据特征进行划分,这里经过测试之后也确实如此。
核支持向量机是非常强大的模型,在各种数据集上的表现都很好。 SVM 允许决策边界很
复杂,即使数据只有几个特征。它在低维数据和高维数据(即很少特征和很多特征)上的
表现都很好,但对样本个数的缩放表现不好。在有多达 10 000 个样本的数据上运行 SVM
可能表现良好,但如果数据量达到 100 000 甚至更大,在运行时间和内存使用方面可能会
面临挑战。
SVM 的另一个缺点是,预处理数据和调参都需要非常小心。这也是为什么如今很多应用
中用的都是基于树的模型,比如随机森林或梯度提升(需要很少的预处理,甚至不需要预
处理)。此外, SVM 模型很难检查,可能很难理解为什么会这么预测,而且也难以将模型
向非专家进行解释。
不过 SVM 仍然是值得尝试的,特别是所有特征的测量单位相似(比如都是像素密度)而
且范围也差不多时。
核 SVM 的重要参数是正则化参数 C、核的选择以及与核相关的参数。虽然我们主要讲的是
RBF 核,但 scikit-learn 中还有其他选择。 RBF 核只有一个参数 gamma,它是高斯核宽度
的倒数。
gamma 和 C 控制的都是模型复杂度,较大的值都对应更为复杂的模型。因此,这
两个参数的设定通常是强烈相关的,应该同时调节。
每文一语
走好当下的每一步便是努力
以上是关于机器学习分类算法之支持向量机的主要内容,如果未能解决你的问题,请参考以下文章