十大视频场景化应用工具+五大视频领域冠军顶会算法重磅开源!
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十大视频场景化应用工具+五大视频领域冠军顶会算法重磅开源!相关的知识,希望对你有一定的参考价值。

>> 导读
随着短视频的快速发展以及安全管理的需求不断增多,视频领域的相关技术应用包括视频智能标签、智能教练、智能剪辑、智能安全管理、文本视频检索、视频精彩片段提取、视频智能封面正逐渐成为人们生活中的重要部分。
以视频相关业务为例,短视频网站希望能迅速给每个新作品打上标签并推送给合适的用户,剪辑人员希望从比赛视频中便捷地提取精彩比赛片段集锦,教练员希望系统分析运动员的动作并进行技术统计和分析,安全管理部门也希望能精准地进行视频内容审核比如实时识别违规行为,编辑人员希望通过文本检索相关的视频片段作为新闻素材,广告或推荐网站希望为视频生成更加美观的封面提升转化率。这些业务对传统的人工处理方式是很大的挑战。
视频理解是通过 AI 技术让机器理解视频内容,如今在短视频、推荐、搜索、广告,安全管理等领域有着广泛的应用和研究价值,像动作定位与识别、视频打标签、文本视频检索、视频内容分析之类的任务都可以通过视频理解技术搞定。
PaddleVideo 是百度自主研发的产业级深度学习开源开放平台飞桨的视频开发套件,包含视频领域众多模型算法和产业案例,本次开源主要升级点如下:
发布10个视频领域产业级应用案例,涵盖体育、互联网、医疗、媒体和安全等行业。
首次开源5个冠军/顶会/产业级算法,包含视频-文本学习、视频分割、深度估计、视频-文本检索、动作识别/视频分类等技术方向。
配套丰富的文档和教程,更有直播课程和用户交流群,可以与百度资深研发工程师一起讨论交流。
十大视频场景化应用
工具详解
飞桨 PaddleVideo 基于体育行业中足球/篮球/乒乓球/花样滑冰等场景,开源出一套通用的体育类动作识别框架;针对互联网和媒体场景开源了基于知识增强的大规模多模态分类打标签、智能剪辑和视频拆条等解决方案;针对安全、教育、医疗等场景开源了多种检测识别案例。百度智能云结合飞桨深度学习技术也形成了一系列深度打磨的产业级多场景动作识别、视频智能分析和生产以及医疗分析等解决方案。
1、足球场景:
开源 FootballAction 精彩片段智能剪辑解决方案
FootballAction 基于行为识别 PP-TSM 模型、视频动作定位 BMN 模型和序列模型 AttentionLSTM 组合得到,不仅能准确识别出动作的类型,而且能精确定位出该动作发生的起止时间。目前能识别的动作类别有8个,包含:背景、进球、角球、任意球、黄牌、红牌、换人、界外球。准确率超过90%。

2、篮球场景:
开源 BasketballAction 精彩片段智能剪辑解决方案
篮球案例 BasketballAction 整体框架与 FootballAction 类似,共包含7个动作类别,分别为:背景、进球-三分球、进球-两分球、进球-扣篮、罚球、跳球,准确率超过90%。

3、乒乓球场景:
开源大规模数据训练的动作分类模型
在百度 Create 2021(百度 AI 开发者大会)上,PaddleVideo 联合北京大学一同发布的乒乓球动作进行识别模型,基于超过 500G 的比赛视频构建了标准的训练数据集,标签涵盖发球、拉、摆短等8个大类动作。其中起止回合准确率达到了97%以上,动作识别也达到了80%以上。

4、花样滑冰动作识别
使用姿态估计算法提取关节点数据,最后将关节点数据输入时空图卷积网络 ST-GCN 模型中进行动作分类,可以实现30种动作的分类。飞桨联合 CCF(中国计算机学会)举办了花样滑冰动作识别大赛,吸引了300家高校与200家企业超过3800人参赛,冠军方案比基线方案精度提升了12个点,比赛 top3 方案已经开源。
|
|


5、知识增强的视频大规模/多模态分类打标签
在视频内容分析方向,飞桨开源了基础的 VideoTag 和多模态的 MultimodalVideoTag。VideoTag 支持3000个源于产业实践的实用标签,具有良好的泛化能力,非常适用于国内大规模短视频分类场景的应用,标签准确率达到89%。
MultimodalVideoTag 模型基于真实短视频业务数据,融合文本、视频图像、音频三种模态进行视频多模标签分类,相比纯视频图像特征,能显著提升高层语义标签效果。模型提供一级标签25个,二级标签200+个,标签准确率超过85%。
|
|

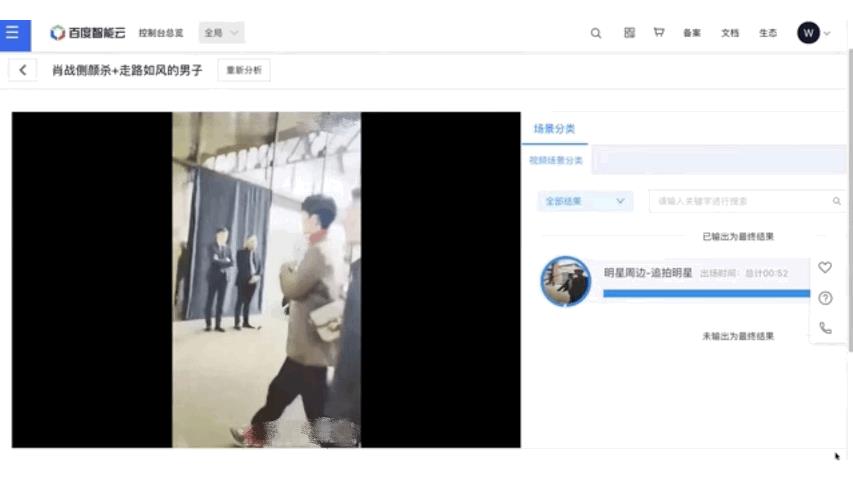
6、视频内容智能生产
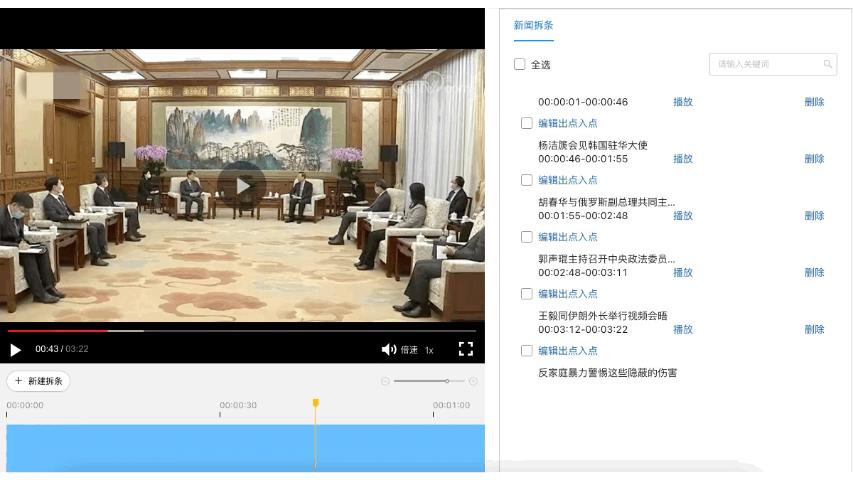
在视频智能生产方向,主要目标是辅助内容创作者对视频进行二次编辑。飞桨开源了基于 PP-TSM 的视频质量分析模型,可以实现新闻视频拆条和视频智能封面两大生产应用解决方案,其中新闻拆条是广电媒体行业的编辑们的重要素材来源;智能封面在直播、互娱等泛互联网行业的点击率和推荐效果方面发挥重要作用。
7、视频交互式标注工具开源
飞桨开源了基于 MA-Net 的交互式视频分割(interactive VOS)工具,提供少量的人工监督信号来实现较好的分割结果,可以仅靠标注简单几帧完成全视频标注,之后可通过多次和视频交互而不断提升视频分割质量,直至对分割质量满意。

8、基于时空动作检测单模型实现87类通用行为识别
飞桨基于时空动作检测模型实现了识别多种人类行为的方案,利用视频多帧时序信息解决传统检测单帧效果差的问题,从数据处理、模型训练、模型测试到模型推理,可以实现 AVA 数据集中80个动作和自研的7个异常行为(挥棍、打架、踢东西、追逐、争吵、快速奔跑、摔倒)的识别。模型的效果远超目标检测方案。
|
|


9、无人机检测
禁飞领域无人机检测有如下挑战:
(1)无人机目标微小,观测困难。
(2)无人机移动速度多变。
(3)无人机飞行环境复杂,可能被建筑、树木遮挡。
针对以上挑战,飞桨开源了无人机检测模型,以实现在众多复杂环境中对无人机进行检测。
|
|


10、医疗影像的分类鉴别
基于公开的 3D-MRI 脑影像数据库,浙江大学医学院附属第二医院和百度研究院开源了帕金森 3D-MRI 脑影像的分类鉴别项目,数据集包括 neurocon、taowu、PPMI 和 OASIS-1 等公开数据集,囊括帕金森患者(PD)与正常(Con)共378个 case。提供 2D 及 3D 基线模型和4种分类模型以及 3D-MRI 脑影像的预训练模型。其中 PP-TSN 和 PP-TSM 取得了超过91%的准确度和超过97.5%的 AUC,而 TimeSformer 实现了最高准确度也超过92.3%。

五大冠军、顶会算法开源
百度研究院首次开源自研冠军、顶会算法
1、CVPR 2020 顶会论文:
多模态预训练模型 ActBERT 首次开源
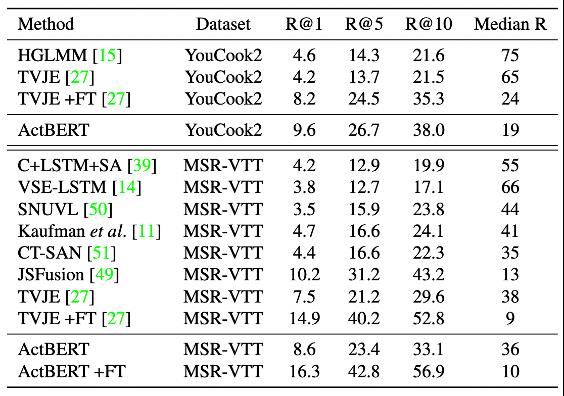
ActBERT 是融合了视频、图像和文本的多模态预训练模型,它使用一种全新的纠缠编码模块从三个来源进行多模态特征学习,以增强两个视觉输入和语言之间的互动功能。该纠缠编码模块,在全局动作信息的指导下,对语言模型注入了视觉信息,并将语言信息整合到视觉模型中。纠缠编码器动态选择合适的上下文以促进目标预测。简单来说,纠缠编码器利用动作信息催化局部区域与文字的相互关联。在文本视频检索、视频描述、视频问答等5个下游任务上,ActBERT 均明显优于其他方法。下表展示了 ActBERT 模型在文本视频检索数据集 MSR-VTT 上的性能表现。
2、CVPR 2021 顶会论文:
文本视频检索模型 T2VLAD 首次开源
随着各种互联网视频尤其是短视频的火热,文本视频检索在近段时间获得了学术界和工业界的广泛关注。特别是在引入多模态视频信息后,如何精细化地配准局部视频特征和自然语言特征成为一大难点。T2VLAD 采用一种高效的全局-局部的对齐方法,自动学习文本和视频信息共享的语义中心,并对聚类后的局部特征做对应匹配,避免了复杂的计算,同时赋予了模型精细化理解语言和视频局部信息的能力。
此外,T2VLAD 直接将多模态的视频信息(声音、动作、场景、speech、OCR、人脸等)映射到同一空间,利用同一组语义中心来做聚类融合,计算同一中心的视频和文本特征的局部相似度,这在一定程度上解决了多模态信息难以综合利用的问题。T2VLAD 在三个标准的 Text-Video Retrieval Dataset 上均取得了优异的性能。

3、CVPR2020视频分割模型 MA-Net 首次开源
视频目标分割(VOS)是计算机视觉领域的一个基础任务,有很多重要的应用场景,如视频编辑、场景理解及自动驾驶等。交互式视频目标分割由用户在视频的某一帧中给目标物体简单的标注(比如在目标物体上画几条简单的线),就能够通过算法获得整个视频中该目标物体的分割结果,用户可以通过多次和视频交互而不断提升视频分割质量,直到用户对分割质量满意。
由于交互式视频分割需要用户多次和视频交互,因此,需要兼顾算法的时效性和准确性。MA-Net 使用一个统一的框架进行交互和传播来生成分割结果,保证了算法的时效性。另外, MA-Net 通过记忆存储的方式,将用户多轮交互的信息存储并更新,提升了视频分割的准确性。下表展示了模型在 DAVIS2017 数据集上性能表现。

4、首次开源 ECCV 2020 Spotlight 视频分割模型 CFBI、CVPR2021 视频目标分割国际竞赛中,基于 CFBI 设计的解决方案在两项任务上夺得了冠军
在视频目标分割领域中,半监督领域在今年来备受关注。给定视频中第一帧或多个参考帧中的目标标定,半监督方法需要精确跟踪并分割出目标物体在整个视频中的掩模。以往的视频目标分割方法都专注于提取给定的前景目标的鲁棒特征,但这在遮挡、尺度变化以及背景中存在相似物体的等等复杂场景下是十分困难的。基于此,我们重新思考了背景特征的重要性,并提出了前背景整合式的视频目标分割方法(CFBI)。
CFBI 以对偶的形式同时提取目标的前景与背景特征,并通过隐式学习的方法提升前背景特征之间的对比度,以提高分割精度。基于 CFBI,我们进一步将多尺度匹配和空洞匹配的策略引入视频目标中,并设计了更为鲁棒且高效的框架,CFBI+。
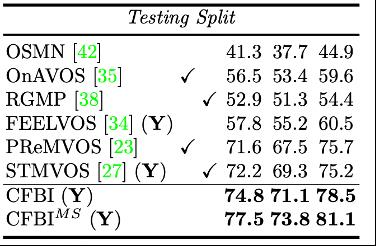
CFBI 系列方法在视频目标分割领域上保持着单模型最高精度的记录。特别地,百度研究院的单模型性能优于旷视清华团队在 CVPR2020 视频目标分割国际竞赛上融合三个强力模型的结果。在今年刚刚结束的 CVPR2021 视频目标分割国际竞赛中,基于 CFBI 设计的解决方案在两项任务上夺得了冠军。下表展示了 CFBI 模型在 DAVIS-2017 数据集上的表现。
5、ICCV 2021 无监督单目深度估计模型 ADDS 首次开源
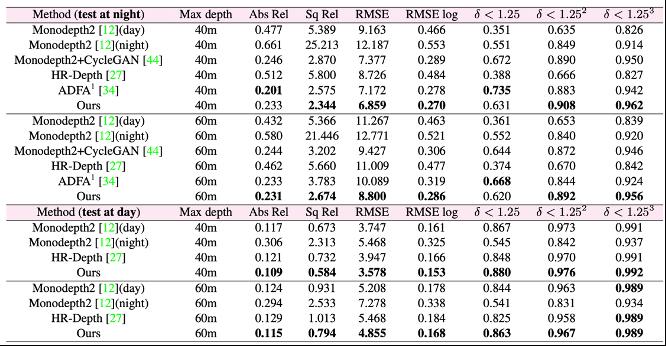
ADDS 是基于白天和夜晚图像的自监督单目深度估计模型,其利用了白天和夜晚的图像数据互补性质,减缓了昼夜图像较大的域偏移以及照明变化对深度估计的精度带来的影响,在具有挑战性的牛津 RobotCar 数据集上实现了全天图像的最先进的深度估计结果。下表展示了 ADDS 模型在白天和夜间数据集上的测试性能表现。
是不是干货满满,心动不如行动,大家可以直接前往 Github 地址获得完整开源项目代码,记得 Star 收藏支持一下哦:
https://github.com/PaddlePaddle/PaddleVideo
精彩课程预告
1.17~1.21日每晚20:15~21:30,飞桨联合百度智能云、百度研究院数十位高工为大家带来直播讲解,剖析行业痛点问题,深入解读体育、互联网、医疗、媒体等行业应用案例及产业级视频技术方案,并带来手把手项目实战。扫码或点击“阅读原文”进行报名,我们直播间不见不散~
扫码报名直播课,加入技术交流群


更多相关内容,请参阅以下内容
官网地址:
https://www.paddlepaddle.org.cn
项目地址:
GitHub:
https://github.com/PaddlePaddle/PaddleVideo
参考文献
1.ActBERT: Learning Global-Local Video-Text Representations , Linchao Zhu, Yi Yang
2.T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval, Xiaohan Wang, Linchao Zhu, Yi Yang
3.Memory Aggregation Networks for Efficient Interactive Video Object Segmentation, Jiaxu Miao, Yunchao Wei, Yi Yang
4.Collaborative Video Object Segmentation by Foreground-Background Integration, Zongxin Yang, Yunchao Wei, Yi Yang
5.Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation, Liu, Lina and Song, Xibin and Wang, Mengmeng and Liu, Yong and Zhang, Liangjun
点击“阅读原文”即可快速报名~
以上是关于十大视频场景化应用工具+五大视频领域冠军顶会算法重磅开源!的主要内容,如果未能解决你的问题,请参考以下文章