CVPR 2023|淘宝视频质量评价算法被顶会收录
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR 2023|淘宝视频质量评价算法被顶会收录相关的知识,希望对你有一定的参考价值。

近日,阿里巴巴大淘宝技术题为《MD-VQA: Multi-Dimensional Quality Assessment for UGC Live Videos》—— 适用于无参考视频质量评价的最新研究成果被计算机视觉领域顶级会议IEEE/CVF Computer Vision and Pattern Recognition Conference 2023(CVPR 2023)成功收录。

CVPR是由IEEE/CVF主办的计算机视觉领域的顶级学术会议,也是中国计算机协会CCF推荐的A类学术会议。该会议每年在世界范围内召开一次,其收录的论文涵盖了图像和视频领域的创新技术和重大成果,是相关领域学术研究与行业发展的风向标。CVPR 2023共收到创纪录的9,155篇投稿(相比2022提升12%),其中有2,360篇论文被接收,接收率为25.78%。此篇被收录论文属于视频质量评价领域,由大淘宝技术和上海交通大学合作完成(共同一作)。
在淘宝,每天有亿级的User-Generated Content (UGC) 等非传统广电视频(包括但不限于短视频、直播等)被生产或播放,其存在明确的无参考视频质量评价的需求,用以对视频质量进行实时监控,确保用户体验。因此,大淘宝音视频技术团队自研了一种针对UGC视频的无参考视频质量评价模型 —— MD-VQA(Multi-Dimensional Video Quality Assessment),综合视频的语义、失真、运动等多维度信息,来衡量视频绝对质量的高低。MD-VQA已经全面应用于包括淘宝直播、逛逛在内的大淘宝视频相关业务,“量化”画质,有效地反应技术迭代带来的体验提升,为大淘宝视频体验提供画质保障。

背景
随着互联网视频化的深入,越来越多的UGC等非传统广电视频(包括但不限于短视频、直播等)在互联网平台上被生产或播放。手淘内容化与互联网内容化的趋势契合,而平台亦希望能够在成本可控的前提下保障尽可能好的视频画质,视频质量评价指标在其中发挥关键作用。相比传统广电视频更多地使用有参考视频质量评价指标,也即要求使用近似无损的源视频作为参考,UGC视频源质量不可控,无法作为理想的无损源,因此无参考视频质量评价方法在短视频和直播视频的评价方面更具备实用价值。
大淘宝音视频技术团队基于淘宝直播、逛逛等内容业务,构建了大规模UGC视频质量评价数据集 —— TaoLive,包含3,762个视频,覆盖不同的内容、失真、和质量,并通过专业的主观标注,获取165,528个视频的主观质量标签。在此之上,大淘宝音视频技术团队自研了一种针对UGC视频的无参考视频质量评价模型 ——MD-VQA(Multi-Dimensional Video Quality Assessment),综合视频的语义、失真、运动等多维度信息,并进行时空域的融合,来衡量视频绝对质量的高低。在公开的视频质量评价数据集LIVE-WC和YT-UGC+,以及TaoLive上,MD-VQA在主流视频质量评价指标SRCC和PLCC上均超过了SOTA(State-Of-The-Art)方法,达到了先进性能。
MD-VQA已经全面应用于包括淘宝直播、逛逛在内的大淘宝内容业务,监控视频业务的大盘画质的变化,快速、精准地筛选出不同画质水位的直播间和短视频,配合淘宝自研S265编码器、视频增强算子集STaoVideo以及《电商直播高画质开播指南》[1] 等,帮助提升平台内容画质。

方法
针对上述问题,我们基于淘宝直播平台的视频,构建了大规模UGC视频质量评价数据集 —— TaoLive,包含3,762个直播视频,覆盖不同的内容和质量,并通过专业的主观打分,获取165,528个主观质量分数的标注数据。与此同时,我们自研了针对UGC视频的无参考视频质量评价模型 —— MD-VQA,综合视频的语义、失真、和运动等多维特征,并进行时空域的融合,来衡量视频绝对质量的高低。
▐ TaoLive数据集
我们从淘宝直播平台筛选了418条视频,覆盖美妆、服饰、珠宝、食品、生活日常等不同内容、以及720p和1080p两个主流分辨率。然后,我们对这些视频进行8种不同失真等级的编码,来模拟实际应用中不同的视频质量,最后共生成3,762条不同内容、不同质量的视频,用来验证我们提出的MD-VQA的模型性能。部分示例视频如图1。

图1. TaoLive数据集示例
在此基础上,我们组织了由44名专家和普通消费者组成(20名男性,24名女性)的主观测评团队,对上述3,762条视频进行主观打分,共生成165,528条主观质量分数的标注数据。然后,我们根据ITU-R BT.500-13 [2] 标准,将标注数据转换为mean opinion score(MOS)分数,作为视频质量的ground-truth(GT)数据。
我们也和业界主流的视频质量评价数据集进行了比较,如表1所示。从表中可以看出,早期(2014-2016)的数据集的规模相对有限,而后续演进的大型数据集,例如KoNViD-1k、YouTube-UGC、LSVQ等则更侧重于In-the-wild的视频内容。在互联网内容平台上流行的“UGC视频结合压缩/传输失真(UGC + Compression)”类型数据集,我们构建的TaoLive数据集在数据规模上具有一定的竞争力,同时更适合于电商场景。

表1. 主流视频质量评价数据集比较
▐ 模型设计
图2示出了所提出的 MD-VQA 模型的框架,包括特征提取模块、特征融合模块、和特征回归模块。具体来说,所提取的视频特征包括多个维度:语义、失真、和运动。特别地,我们利用相邻帧特征之间的绝对误差来反映视频质量在时域上波动。上述得到的多维特征在时空域上被融合,并通过特征回归模块映射到最终的质量分数。
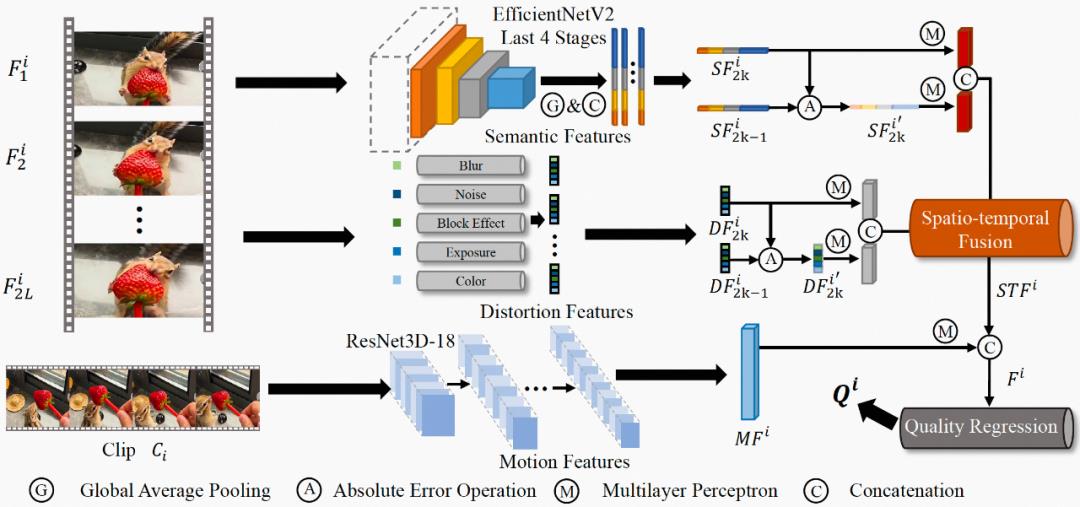
图2. MD-VQA模型的网络架构示例
语义特征提取
视频语义特征通常描述视频中物体的物理特性、物体之间的时空关系、以及物体的内容信息等,属于视频的高维特征,且和视频的低维特征(如亮度、色彩、纹理等)存在很强的关联性。此外,对于不同的视频内容,语义特征的失真对人眼感知到的视频质量有着不同的影响:人眼通畅无法容忍纹理丰富的内容(例如草坪、地毯)的模糊,二队纹理简单的内容(例如天空、墙面)的模糊相对不敏感。综上考虑,我们利用从预训练的EfficientNetV2 [3] 网络最后4层中提取的多维度特征作为帧级的语义特征,如图3公式所示:

图3. 语义特征
其中,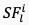 表示从第
表示从第 个视频片段的第帧获取的语义特征,
个视频片段的第帧获取的语义特征, 表示级联算子,
表示级联算子, 表示全局平均池化算子,
表示全局平均池化算子, 表示EfficientNetV2第
表示EfficientNetV2第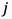 层的特征图,
层的特征图, 表示从
表示从 获取的平均池化特征。
获取的平均池化特征。
失真特征提取
由于UGC视频中普遍存在多种失真,仅使用语义特征来表征视频质量是不充分的。此外,对于不同的压缩质量,失真会呈现不同的状态,例如在压缩质量相对较低时,模糊会比较明显,但噪声也同时被抑制。因此,在考虑高维的语义特征的同时,我们引入了低维的手工(hand-crafted)特征,包括模糊、噪声、块效应、曝光强度、以及色彩,然后将上述特征综合为帧级的失真特征,如图4公式所示:

图4. 失真特征
其中, 表示从第
表示从第 个视频片段的第帧获取的失真特征,
个视频片段的第帧获取的失真特征, 表示失真特征提取算子。
表示失真特征提取算子。
运动特征提取
运动失真通常源自于拍摄时的抖动、或者低码率的视频编码,并且,其无法被视频空域特征(例如前述的语义特征)有效地描述。因此,为了提高模型的准确度,我们利用预训练的ResNet3D-18 [4] 获取帧级的运动特征,如图5公式所示:

图5. 运动特征
其中, 表示从第个视频片段获取的运动特征,
表示从第个视频片段获取的运动特征, 表示运动特征提取算子。
表示运动特征提取算子。
特征融合
根据 [5] 中所述,高质量视频通常具有更小的帧间质量波动,反之亦然。为了量化上述波动,我们使用帧间语义特征和失真特征的绝对误差来衡量帧间质量波动,如图6公式所示:

图6. 相邻帧的语义特征的绝对误差和失真特征的绝对误差
其中, 和
和 分别表示相邻帧的语义特征的绝对误差,以及失真特征的绝对误差。
分别表示相邻帧的语义特征的绝对误差,以及失真特征的绝对误差。
基于此,时空域特征可以利用图7中的公式进行融合:

图7. 时空域特征融合
其中, 表示帧级的时空域特征,
表示帧级的时空域特征, 表示级联算子,
表示级联算子, 表示可学习多层感知机,
表示可学习多层感知机, 表示
表示 的转置,
的转置, 表示可学习的线性映射算子,将
表示可学习的线性映射算子,将 映射到最终的时空域融合特征
映射到最终的时空域融合特征 。
。
最后,上述时空域融合特征 与运动特征
与运动特征 进一步融合,形成最终的时空域融合特征
进一步融合,形成最终的时空域融合特征 ,如图8公式所示:
,如图8公式所示:

图8. 最终的时空域融合特征
特征回归
基于上述时空域融合特征 ,我们利用三层全连接层来回归视频质量,如图9公式所示:
,我们利用三层全连接层来回归视频质量,如图9公式所示:

图9. 全连接层回归视频质量
其中, 表示全连接层,
表示全连接层, 表示视频片段的质量。
表示视频片段的质量。
此外,我们使用均方误差MSE(Mean Squared Error)作为损失函数,如图10公式所示:

图10. 全连接层回归视频质量
其中, 表示mini-batch的视频数量,
表示mini-batch的视频数量, 和
和 分别表示预测的视频质量和实际的视频质量。完整视频的质量可通过对视频片段进行平均池化操作获得。
分别表示预测的视频质量和实际的视频质量。完整视频的质量可通过对视频片段进行平均池化操作获得。

实验
我们在两个公开的视频质量评价数据集LIVE-WC和YouTube-UGC,以及我们自建的TaoLive数据集上,与现有SOTA方法进行了对比。我们使用Spearman Rank Order Correlation Coefficient(SRCC)和Pearson Linear Correlation Coefficient(PLCC)作为指标进行对比。更高的SRCC表示样本间更好的保序性,更高的PLCC表示与标注分数更好地拟合程度。结果如表2所示。

表2. MD-VQA与其他视频质量评价SOTA模型在LIVE-WC、YT-UGC+、和TaoLive数据集的性能比较
从表中可以看出,我们在所测试数据集上的SRCC和PLCC均超过了现有SOTA方法,达到了先进性能。
此外,为了探索不同的特征对模型性能的贡献,我们进行了消融实验(ablation study),如表3和表4所示。

表3. 语义特征SF、失真特征DF、和运动特征MF对于模型性能的贡献比较
从表3中可以看出,语义特征对于模型的领先性贡献最多,而另外两种特征在不同的视频内容(不同数据集)上有不同的表现,符合预期。

表4. 绝对误差(ABS)和特征融合模块(FFM)对于模型性能的贡献比较
从表4中可以看出,绝对误差(ABS)和特征融合模块(FFM)对于模型性能的领先性均有贡献。

总结
为了准确、高效地衡量UGC视频的绝对质量,我们构建了大规模UGC视频质量评价数据集 —— TaoLive。不同于常见的视频质量评价数据集使用高质量视频作为源视频,TaoLive 数据集收集了3,762个UGC源视频,覆盖不同的内容和质量,并通过专业的主观打分,获取165,528个主观质量分数的标注数据。此外,我们提出一个无参考视频质量评价模型 —— MD-VQA,综合视频的语义、失真、和运动等多维特征,并进行时空域的融合,来衡量视频绝对质量的高低。实验结果表明,MD-VQA在主流视频质量评价数据集和评价指标上,均超过了现有方法,达到了先进性能。
MD-VQA已经全面应用于包括淘宝直播、逛逛在内的大淘宝内容业务,监控视频业务的大盘画质的变化,快速、精准地筛选出不同画质水位的直播间和短视频,配合淘宝自研S265编码器、视频增强算子集STaoVideo以及《电商直播高画质开播指南》[1] 等,帮助提升平台内容画质。

参考文献
【1】 “服贸会在京举行|淘宝直播携手佳能佳直播联合发布《电商直播高画质开播指南》让品质直播触手可及”,https://mp.weixin.qq.com/s/2-pC1Z9wH60DHpUkCU-_ng.
【2】 RECOMMENDATION ITU-R BT. Methodology for the subjective assessment of the quality of television pictures. International Telecommunication Union, 2002.
【3】 Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models and faster training. In International Conference on Machine Learning, pages 10096–10106. PMLR, 2021.
【4】 Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatio-temporal 3d cnns retrace the history of 2d cnns and imagenet? In IEEE/CVF CVPR, pages 6546–6555, 2018.
【5】Manish Narwaria, Weisi Lin, and Anmin Liu. Low-complexity video quality assessment using temporal quality variations. IEEE TMM, 14(3):525–535, 2012.

团队介绍
该工作主要在大淘宝技术的音视频技术团队的带领下完成,该团队依托淘宝直播、逛逛、手淘首页信息流等内容业务,致力于打造行业领先的音视频技术。团队成员来自海内外知名高校,先后在MSU世界编码器大赛,NTIRE视频增强超分竞赛这样的领域强相关权威赛事上夺魁,并重视与学界的合作与交流。
这项工作的合作方为上海交通大学张文军教授领衔的图像所团队,是数字电视广播及数字媒体处理与传输领域的主要研究力量之一。面向国家战略性新兴产业,顺应网络化、融合化的发展趋势,近年来开展的重点研究领域包括智能媒体融合网络、视频智能分析处理与传输等。
¤ 拓展阅读 ¤
CVPR2022 | CVPR2022最全整理,CVPR2022下载链接,CVPR2022全部论文代码
CVPR是IEEE Conference on Computer Vision and Pattern Recognition的缩写,即IEEE国际计算机视觉与模式识别会议。该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议。
国际计算机视觉与模式识别会议(CVPR)是IEEE一年一度的学术性会议,会议的主要内容是计算机视觉与模式识别技术。CVPR是世界顶级的计算机视觉会议(三大顶会之一,另外两个是ICCV和ECCV)
CVPR2022还没有开始,我们先回顾CVPR2021
我自己总结持续更新Github上面:https://github.com/Sophia-11/Awesome-CVPR-Paper
CVPR2021最新更新论文
Image-to-image Translation via Hierarchical Style Disentanglement Xinyang Li, Shengchuan Zhang, Jie Hu, Liujuan Cao, Xiaopeng Hong, Xudong Mao, Feiyue Huang, Yongjian Wu, Rongrong Ji https://arxiv.org/abs/2103.01456 https://github.com/imlixinyang/HiSD
FLAVR: Flow-Agnostic Video Representations for Fast Frame Interpolation https://arxiv.org/pdf/2012.08512.pdf https://tarun005.github.io/FLAVR/Code https://tarun005.github.io/FLAVR/
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition Stephen Hausler, Sourav Garg, Ming Xu, Michael Milford, Tobias Fischer https://arxiv.org/abs/2103.01486
Depth from Camera Motion and Object Detection Brent A. Griffin, Jason J. Corso https://arxiv.org/abs/2103.01468
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers https://arxiv.org/pdf/2011.09094.pdf
Multi-Stage Progressive Image Restoration https://arxiv.org/abs/2102.02808 https://github.com/swz30/MPRNet
Weakly Supervised Learning of Rigid 3D Scene Flow https://arxiv.org/pdf/2102.08945.pdf https://arxiv.org/pdf/2102.08945.pdf https://3dsceneflow.github.io/
Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning Mamshad Nayeem Rizve, Salman Khan, Fahad Shahbaz Khan, Mubarak Shah https://arxiv.org/abs/2103.01315
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels https://arxiv.org/abs/2101.05022 https://github.com/naver-ai/relabel_imagenet
Rethinking Channel Dimensions for Efficient Model Design https://arxiv.org/abs/2007.00992 https://github.com/clovaai/rexnet
Coarse-Fine Networks for Temporal Activity Detection in Videos Kumara Kahatapitiya, Michael S. Ryoo https://arxiv.org/abs/2103.01302
A Deep Emulator for Secondary Motion of 3D Characters Mianlun Zheng, Yi Zhou, Duygu Ceylan, Jernej Barbic https://arxiv.org/abs/2103.01261
Fair Attribute Classification through Latent Space De-biasing https://arxiv.org/abs/2012.01469 https://github.com/princetonvisualai/gan-debiasing https://princetonvisualai.github.io/gan-debiasing/
Auto-Exposure Fusion for Single-Image Shadow Removal Lan Fu, Changqing Zhou, Qing Guo, Felix Juefei-Xu, Hongkai Yu, Wei Feng, Yang Liu, Song Wang https://arxiv.org/abs/2103.01255
Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling https://arxiv.org/pdf/2102.06183.pdf https://github.com/jayleicn/ClipBERT
MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing Zhengjue Wang, Hao Zhang, Ziheng Cheng, Bo Chen, Xin Yuan https://arxiv.org/abs/2103.01786
AttentiveNAS: Improving Neural Architecture Search via Attentive https://arxiv.org/pdf/2011.09011.pdf
Diffusion Probabilistic Models for 3D Point Cloud Generation Shitong Luo, Wei Hu https://arxiv.org/abs/2103.01458
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge Francisco Rivera Valverde, Juana Valeria Hurtado, Abhinav Valada https://arxiv.org/abs/2103.01353 http://rl.uni-freiburg.de/research/multimodal-distill
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation https://arxiv.org/abs/2008.00951 https://github.com/eladrich/pixel2style2pixel https://eladrich.github.io/pixel2style2pixel/
Hierarchical and Partially Observable Goal-driven Policy Learning with Goals Relational Graph Xin Ye, Yezhou Yang https://arxiv.org/abs/2103.01350
RepVGG: Making VGG-style ConvNets Great Again https://arxiv.org/abs/2101.03697 https://github.com/megvii-model/RepVGG
Transformer Interpretability Beyond Attention Visualization https://arxiv.org/pdf/2012.09838.pdf https://github.com/hila-chefer/Transformer-Explainability
PREDATOR: Registration of 3D Point Clouds with Low Overlap https://arxiv.org/pdf/2011.13005.pdf https://github.com/ShengyuH/OverlapPredator https://overlappredator.github.io/
以上是关于CVPR 2023|淘宝视频质量评价算法被顶会收录的主要内容,如果未能解决你的问题,请参考以下文章