大数据需要学什么?
Posted uncledata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据需要学什么?相关的知识,希望对你有一定的参考价值。
注意本文非广告,阅读时间四分钟左右,适合大数据入门级读者阅读
大数据需要学习什么?很多人问过我这个问题。每一次回答完都觉得自己讲得太片面了,总是没有一个合适的契机去好好总结这些内容,直到开始写这篇东西。大数据是近五年兴起的行业,发展迅速,很多技术经过这些年的迭代也变得比较成熟了,同时新的东西也不断涌现,想要保持自己竞争力的唯一办法就是不断学习。
思维导图
下面的是我整理的一张思维导图,内容分成几大块,包括了分布式计算与查询,分布式调度与管理,持久化存储,大数据常用的编程语言等等内容,每个大类下有很多的开源工具,这些就是作为大数据程序猿又爱又恨折腾得死去活来的东西了。
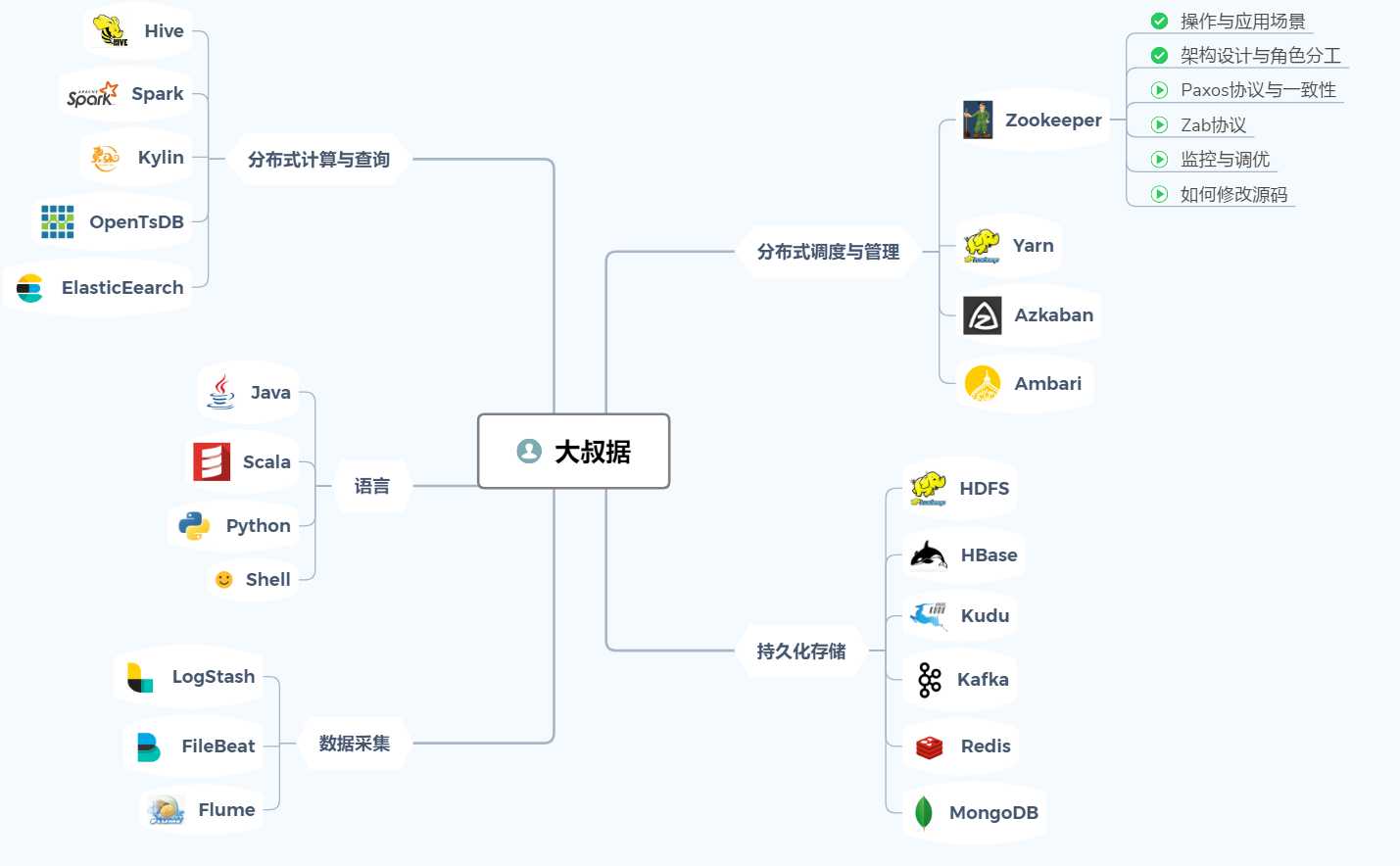
大数据需要的语言
Java
java可以说是大数据最基础的编程语言,据我这些年的经验,我接触的很大一部分的大数据开发都是从Jave Web开发转岗过来的(当然也不是绝对我甚至见过产品转岗大数据开发的,逆了个天)。
- 一是因为大数据的本质无非就是海量数据的计算,查询与存储,后台开发很容易接触到大数据量存取的应用场景
- 二就是java语言本事了,天然的优势,因为大数据的组件很多都是用java开发的像HDFS,Yarn,Hbase,MR,Zookeeper等等,想要深入学习,填上生产环境中踩到的各种坑,必须得先学会java然后去啃源码。
说到啃源码顺便说一句,开始的时候肯定是会很难,需要对组件本身和开发语言都有比较深入的理解,熟能生巧慢慢来,等你过了这个阶段,习惯了看源码解决问题的时候你会发现源码真香。
Scala
scala和java很相似都是在jvm运行的语言,在开发过程中是可以无缝互相调用的。Scala在大数据领域的影响力大部分都是来自社区中的明星Spark和kafka,这两个东西大家应该都知道(后面我会有文章多维度介绍它们),它们的强势发展直接带动了Scala在这个领域的流行。
Python和Shell
shell应该不用过多的介绍非常的常用,属于程序猿必备的通用技能。python更多的是用在数据挖掘领域以及写一些复杂的且shell难以实现的日常脚本。
分布式计算
什么是分布式计算?分布式计算研究的是如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多服务器进行处理,最后把这些计算结果综合起来得到最终的结果。
举个栗子,就像是组长把一个大项目拆分,让组员每个人开发一部分,最后将所有人代码merge,大项目完成。听起来好像很简单,但是真正参与过大项目开发的人一定知道中间涉及的内容可不少。
比如这个大项目如何拆分?任务如何分配?每个人手头已有工作怎么办?每个人能力不一样怎么办?每个人开发进度不一样怎么办?开发过程中组员生病要请长假他手头的工作怎么办?指挥督促大家干活的组长请假了怎么办?最后代码合并过程出现问题怎么办?项目延期怎么办?项目最后黄了怎么办?
仔细想想上面的夺命十连问,其实每一条都是对应了分布式计算可能会出现的问题,具体怎么对应大家思考吧我就不多说了,其实已经是非常明显了。也许有人觉得这些问题其实在多人开发的时候都不重要不需要特别去考虑怎么办,但是在分布式计算系统中不一样,每一个都是非常严重并且非常基础的问题,需要有很好的解决方案。
最后提一下,分布式计算目前流行的工具有:
- 离线工具Spark,MapReduce等
- 实时工具Spark Streaming,Storm,Flink等
这几个东西的区别和各自的应用场景我们之后再聊。
分布式存储
传统的网络存储系统采用的是集中的存储服务器存放所有数据,单台存储服务器的io能力是有限的,这成为了系统性能的瓶颈,同时服务器的可靠性和安全性也不能满足需求,尤其是大规模的存储应用。
分布式存储系统,是将数据分散存储在多台独立的设备上。采用的是可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
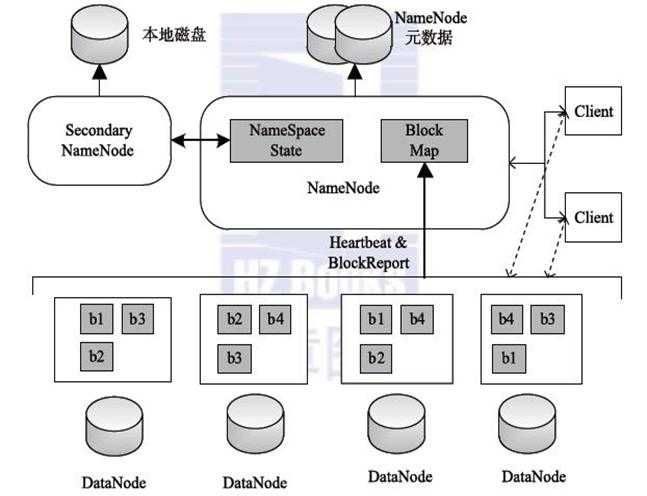
上图是hdfs的存储架构图,hdfs作为分布式文件系统,兼备了可靠性和扩展性,数据存储3份在不同机器上(两份存在同一机架,一份存在其他机架)保证数据不丢失。由NameNode统一管理元数据,可以任意扩展集群。
主流的分布式数据库有很多hbase,mongoDB,GreenPlum,redis等等等等,没有孰好孰坏之分,只有合不合适,每个数据库的应用场景都不同,其实直接比较是没有意义的,后续我也会有文章一个个讲解它们的应用场景原理架构等。
分布式调度与管理
现在人们好像都很热衷于谈"去中心化",也许是区块链带起的这个潮流。但是"中心化"在大数据领域还是很重要的,至少目前来说是的。
- 分布式的集群管理需要有个组件去分配调度资源给各个节点,这个东西叫yarn;
- 需要有个组件来解决在分布式环境下"锁"的问题,这个东西叫zookeeper;
- 需要有个组件来记录任务的依赖关系并定时调度任务,这个东西叫azkaban。
当然这些“东西”并不是唯一的,其实都是有很多替代品的,我这里只举了几个比较常用的例子。
说两句
回答完这个问题,准备说点其他的。最近想了很久,准备开始写一系列的文章,记录这些年来的所得所想,感觉内容比较多不知从哪里开始,就画了文章开头的思维导图确定了大的方向,大家都知道大数据的主流技术变化迭代很快,不断会有新的东西加入,所以这张图里内容也会根据情况不断添加。细节的东西我会边写边定,大家也可以给我一些建议,我会根据写的内容实时更新这张图以及下面的目录。
关于分组
上面的大数据组件分组其实是比较纠结的,特别是作为一个有强迫症的程序猿,有些组件好像放在其他组也可以,而且我又不想要分太多的组看起来会很乱,所以上面这张图的分组方式会稍主观一些。分组方式肯定不是绝对的。
举个例子,像kafka这种消息队列一般不会和其它的数据库或者像HDFS这种文件系统放在一起,但是它们同样都具备有分布式持久化存储的功能,所以就把它们放在一块儿了;还有openTsDB这种时序数据库,说是数据库实际上只是基于HBase上的一个应用,我觉得这个东西更侧重于查询和以及用何种方式存储,而不在于存储本身,所以就主观地放在了“分布式计算与查询”这一类,还有OLAP的工具也同样放在了这一组。
同样的情况还存在很多,大家有异议也可以说出来讨论下。
目的
大家都知道大数据的技术日新月异,作为一个程序猿想要保持竞争力就必须得不断地学习。写这些文章的目的比较简单,一是可以当做一个笔记,梳理知识点;二是希望能帮到一些人了解学习大数据。每一篇的篇幅不会太长,阅读时间控制在5到10分钟。我的公众号大叔据,会同步更新。喜欢看公众号文章的同学可以关注下,文章的篇幅不会太长,不会占用你太多的阅读时间,每天花一点时间学习,长期积累总是会有收获的。

以上是关于大数据需要学什么?的主要内容,如果未能解决你的问题,请参考以下文章