女生如果学大数据怎么样?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了女生如果学大数据怎么样?相关的知识,希望对你有一定的参考价值。
首先,女生是适合学习大数据技术的,而且大数据行业内有很多岗位比较适合女生从事,比如数据整理、存储、分析等岗位都是不错的选择,但是由于大数据的知识体系比较复杂,所以学习起来也具有一定的难度。大数据领域的岗位可以简单地划分为两大类,一类是研发型岗位,或者叫做创新型岗位,另一类是应用型岗位,或者叫技能型岗位。研发型岗位的难度比较大,往往需要从业者具有扎实的知识基础,同时要掌握一系列研究方法,对于工作环境也有相对较高的要求,比如需要较强的算力和数据支撑。
目前大数据领域的研发级岗位往往对于从业者的学历有较高的要求,不少人通过读研获得了研发级岗位,目前有不少女生在读研时,会选择大数据相关方向。从2019年的秋招来看,大数据领域的岗位相对比较多,可以选择的空间也比较大。
相对于研发级岗位来说,应用级岗位的学习难度要相对低很多,即使没有计算机知识基础,经过一个系统的学习过程,往往也能够从事一些大数据领域的岗位,比如数据采集、数据清洗、数据分析等岗位都比较适合女生来从事。
所以,在选择学习大数据知识的时候,应该根据自身的知识基础和能力特点来选择学习路线。 参考技术A 大数据开发总体来说知识体系是非常庞大的,对于零基础小伙伴来讲,想要学好大数据开发技术不是一件容易的事,但是在学习大数据开发方面并没有男女之分,而且有很多企业还是比较喜欢女程序员的,毕竟女程序员在找bug的时候相对于男程序员来说比较细心些。
但是,想要学好大数据开发技术,不仅需要一定的编程基础,还需要有较强的思维逻辑能力,可能在思维逻辑能力方面,女生会有些欠缺,不过不用担心,小伙伴可以去大数据培训班系统的去学习开发技术知识,好的思维逻辑能力是慢慢培养起来的,并不是每个人刚出生就有这么强的思维逻辑能力。
小伙伴想要通过大数据培训班学习开发技术知识,首先是要选择一家比较靠谱的大数据培训班,小伙伴在选择大数据培训班的时候,要实地考察了解,多家对比,理性选择适合自己的大数据培训班,在学习大数据开发技术的过程中,小伙伴要通过不断的探索找到适合自己的学习方法。
1.基础知识的积累过程对初学大数据开发的小伙伴来说是非常重要的,因此,小伙伴在积累基础知识的过程中,要端正自己的学习态度,脚踏实地的去学习相关大数据开发技术的基础知识。
2.项目实战案例练习的重要性,小伙伴可以看到企业在招聘人才的时候,往往都比较重视真实项目开发经验,所以小伙伴在学习大数据开发过程中,要不断的去练习相关项目案例,在练习过程中,不仅能让小伙伴更深入的理解相关大数据开发技术知识,还能积累一些项目实战经验。
3.在大数据培训班学习开发技术知识过程中,小伙伴不要闭门造车,要多和老师、同学进行交流,在交流过程中去学习别人的编程思路,将自己所学到的融合到自己的编程思维当中,在学习过程中慢慢培养自身编程思维。 参考技术B 女生学大数据三大劣势
一、天分劣势
往往我们会以为IT行业压力大,逻辑代码繁杂,男生思想逻辑好,抗压才能强,合适做顺序员。但实践上整个IT行业自身都没有性别限制,女生心思细腻有耐烦,对细节愈加注重,特别是数据方面更要求精确性,女工程师接手项目BUG也少,女生学大数据专业很罕见,并且工作更受欢送。
二、项目劣势
大数据开发、剖析等全是客户的重要项目,单方沟通显得非常重要,社会遍及对女性容纳度较高,不只是由于女性给人更亲切的觉得,并且女工程师在项目细节上会做得更贴心,客户称心度也就更高,项目修正的次数也会增加。如今很多互联网大厂都倾向于招聘有才能的女工程师,关于技术要求甚至还能够放宽松,进公司再锤炼。
三、性别劣势
IT行业不管是软件开发还是数据工程师,目前依然是男性占大大都,这样一个环境,一旦有女生参加,本来活跃的气氛也会变得轻松生动,女生就成了这个圈子里的配角,会备受关注,只需表现还不错,很容易就能够升职加薪。但是在大数据行业中,一直还是要以技术说话,要先把技术学好了,然后再进入职场。 参考技术C 女生可以学习大数据,不论男生还是女生都可以经过系统的学习之后达到大数据开发所需要具备的技能要求,所以男女都是可以学习的。
大数据学习方向分别为:Java基础、JavaEE核心、Hadoop生态体系、Spark生态体系、项目实战+机器学习。
第一阶段Java基础,主要知识点有:Java基础语法、面向对象编程、常用类和工具类、集合框架体系、异常处理机制、文件和IO流、移动开户管理系统、多线程、枚举和垃圾回收、反射、JDK新特性、通讯录系统。
第二阶段JavaEE核心,主要知识点有:前端技术、数据库、JDBC技术、服务器端技术、Maven、Spring、SpringBoot、Git。
第三阶段Hadoop生态体系,主要知识点有:Linux、Hadoop、ZooKeeper、Hive HBase、Phoenix、Impala、Kylin、Flume、Sqoop&DataX、Kafka、Oozie&Azkaban Hue、智慧农业数仓分析平台。
第四阶段Spark生态体系,主要知识点有:Scala、Spark、交通领域汽车流量监控项目、Flink。
第五阶段项目实战+机器学习,主要知识点有:高铁智能检测系统、电信充值、中国天气网、机器学习。 参考技术D 如果你是感兴趣,那还是挺不错的,其实大学的专业并不是说你适不适合,而是说,你敢不敢兴趣,学不学的进去
大数据学习之小白如何学大数据?(详细篇)
大数据这个话题热度一直高居不下,不仅是国家政策的扶持,也是科技顺应时代的发展。想要学习大数据,我们该怎么做呢?大数据学习路线是什么?先带大家了解一下大数据的特征以及发展方向。
大数据的三个发展方向,平台搭建/优化/运维/监控、大数据开发/设计/架构、数据分析/挖掘。
先说一下大数据的4V特征:
数据量大,TB->PB
数据类型繁多,结构化、非结构化文本、日志、视频、图片、地理位置等;
商业价值高,但是这种价值需要在海量数据之上,通过数据分析与机器学习更快速的挖掘出来;
处理时效性高,海量数据的处理需求不再局限在离线计算当中。
现如今,正式为了应对大数据的这几个特点,开源的大数据框架越来越多,越来越强,再列举一些常见的:
文件存储:hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
……
上面有30多种吧,别说精通了,全部都会使用的,估计也没几个。
详细讲讲第二个方向(开发/设计/架构),这个方向相当容易找工作。
大数据学习群142973723
第一章:初识Hadoop
1.1 学会百度与Google
不论遇到什么问题,先试试搜索并自己解决。
Google首选,翻不过去的,就用百度吧。
1.2 参考资料首选官方文档
特别是对于入门来说,官方文档永远是首选文档。
相信搞这块的大多是文化人,英文凑合就行,实在看不下去的,请参考第一步。
1.3 先让Hadoop跑起来
Hadoop可以算是大数据存储和计算的开山鼻祖,现在大多开源的大数据框架都依赖Hadoop或者与它能很好的兼容。
关于Hadoop,你至少需要搞清楚以下是什么:
Hadoop 1.0、Hadoop 2.0
MapReduce、HDFS
NameNode、DataNode
JobTracker、TaskTracker
Yarn、ResourceManager、NodeManager
自己搭建Hadoop,请使用第一步和第二步,能让它跑起来就行。
建议先使用安装包命令行安装,不要使用管理工具安装。
1.4 试试使用Hadoop
HDFS目录操作命令;
上传、下载文件命令;
提交运行MapReduce示例程序;
打开Hadoop WEB界面,查看Job运行状态,查看Job运行日志。
知道Hadoop的系统日志在哪里。
1.5 你该了解它们的原理了
MapReduce:如何分而治之;
HDFS:数据到底在哪里,什么是副本;
Yarn到底是什么,它能干什么;
NameNode到底在干些什么;
ResourceManager到底在干些什么;
1.6 自己写一个MapReduce程序
请仿照WordCount例子,自己写一个(照抄也行)WordCount程序,
打包并提交到Hadoop运行。
你不会Java?Shell、Python都可以,有个东西叫Hadoop Streaming。
如果你认真完成了以上几步,恭喜你,你的一只脚已经进来了。
第二章:更高效的WordCount
2.1 学点SQL吧
你知道数据库吗?你会写SQL吗?
如果不会,请学点SQL吧。
2.2 SQL版WordCount
在1.6中,你写(或者抄)的WordCount一共有几行代码?
例如:
SELECT word,COUNT(1) FROM wordcount GROUP BY word;
这便是SQL的魅力,编程需要几十行,甚至上百行代码,这一句就搞定;使用SQL处理分析Hadoop上的数据,方便、高效、易上手、更是趋势。不论是离线计算还是实时计算,越来越多的大数据处理框架都在积极提供SQL接口。
2.3 SQL On Hadoop之Hive
什么是Hive?官方给的解释是:
The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
为什么说Hive是数据仓库工具,而不是数据库工具呢?有的朋友可能不知道数据仓库,数据仓库是逻辑上的概念,底层使用的是数据库,数据仓库中的数据有这两个特点:最全的历史数据(海量)、相对稳定的;所谓相对稳定,指的是数据仓库不同于业务系统数据库,数据经常会被更新,数据一旦进入数据仓库,很少会被更新和删除,只会被大量查询。而Hive,也是具备这两个特点,因此,Hive适合做海量数据的数据仓库工具,而不是数据库工具。

2.4 安装配置Hive
请参考1.1和 1.2 完成Hive的安装配置。可以正常进入Hive命令行。
2.5 试试使用Hive
请参考1.1和 1.2 ,在Hive中创建wordcount表,并运行2.2中的SQL语句。
在Hadoop WEB界面中找到刚才运行的SQL任务。
看SQL查询结果是否和1.4中MapReduce中的结果一致。
2.6 Hive是怎么工作的
明明写的是SQL,为什么Hadoop WEB界面中看到的是MapReduce任务?
2.7 学会Hive的基本命令
创建、删除表;
加载数据到表;
下载Hive表的数据;
请参考1.2,学习更多关于Hive的语法和命令。
如果你已经按照《写给大数据开发初学者的话》中第一章和第二章的流程认真完整的走了一遍,那么你应该已经具备以下技能和知识点:
0和Hadoop2.0的区别;
MapReduce的原理(还是那个经典的题目,一个10G大小的文件,给定1G大小的内存,如何使用Java程序统计出现次数最多的10个单词及次数);
HDFS读写数据的流程;向HDFS中PUT数据;从HDFS中下载数据;
自己会写简单的MapReduce程序,运行出现问题,知道在哪里查看日志;
会写简单的SELECT、WHERE、GROUP BY等SQL语句;
Hive SQL转换成MapReduce的大致流程;
Hive中常见的语句:创建表、删除表、往表中加载数据、分区、将表中数据下载到本地;
从上面的学习,你已经了解到,HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。
那么问题来了,海量数据如何到HDFS上呢?
第三章:把别处的数据搞到Hadoop上
此处也可以叫做数据采集,把各个数据源的数据采集到Hadoop上。
3.1 HDFS PUT命令
这个在前面你应该已经使用过了。
put命令在实际环境中也比较常用,通常配合shell、python等脚本语言来使用。
建议熟练掌握。
3.2 HDFS API
HDFS提供了写数据的API,自己用编程语言将数据写入HDFS,put命令本身也是使用API。
实际环境中一般自己较少编写程序使用API来写数据到HDFS,通常都是使用其他框架封装好的方法。比如:Hive中的INSERT语句,Spark中的saveAsTextfile等。
建议了解原理,会写Demo。
3.3 Sqoop
Sqoop是一个主要用于Hadoop/Hive与传统关系型数据库Oracle/MySQL/SQLServer等之间进行数据交换的开源框架。
就像Hive把SQL翻译成MapReduce一样,Sqoop把你指定的参数翻译成MapReduce,提交到Hadoop运行,完成Hadoop与其他数据库之间的数据交换。
自己下载和配置Sqoop(建议先使用Sqoop1,Sqoop2比较复杂)。
了解Sqoop常用的配置参数和方法。
使用Sqoop完成从MySQL同步数据到HDFS;
使用Sqoop完成从MySQL同步数据到Hive表;
PS:如果后续选型确定使用Sqoop作为数据交换工具,那么建议熟练掌握,否则,了解和会用Demo即可。
3.4 Flume
Flume是一个分布式的海量日志采集和传输框架,因为“采集和传输框架”,所以它并不适合关系型数据库的数据采集和传输。
Flume可以实时的从网络协议、消息系统、文件系统采集日志,并传输到HDFS上。
因此,如果你的业务有这些数据源的数据,并且需要实时的采集,那么就应该考虑使用Flume。
下载和配置Flume。
使用Flume监控一个不断追加数据的文件,并将数据传输到HDFS;
PS:Flume的配置和使用较为复杂,如果你没有足够的兴趣和耐心,可以先跳过Flume。
3.5 阿里开源的DataX
之所以介绍这个,是因为我们公司目前使用的Hadoop与关系型数据库数据交换的工具,就是之前基于DataX开发的,非常好用。
现在DataX已经是3.0版本,支持很多数据源。
你也可以在其之上做二次开发。
PS:有兴趣的可以研究和使用一下,对比一下它与Sqoop。
第四章:把Hadoop上的数据搞到别处去
前面介绍了如何把数据源的数据采集到Hadoop上,数据到Hadoop上之后,便可以使用Hive和MapReduce进行分析了。那么接下来的问题是,分析完的结果如何从Hadoop上同步到其他系统和应用中去呢?
其实,此处的方法和第三章基本一致的。
4.1 HDFS GET命令
把HDFS上的文件GET到本地。需要熟练掌握。
4.2 HDFS API
同3.2.
4.3 Sqoop
同3.3.
使用Sqoop完成将HDFS上的文件同步到MySQL;
使用Sqoop完成将Hive表中的数据同步到MySQL;
4.4 DataX
同3.5.
你应该已经具备以下技能和知识点:
知道如何把已有的数据采集到HDFS上,包括离线采集和实时采集;
你已经知道sqoop(或者还有DataX)是HDFS和其他数据源之间的数据交换工具;
你已经知道flume可以用作实时的日志采集。
从前面的学习,对于大数据平台,你已经掌握的不少的知识和技能,搭建Hadoop集群,把数据采集到Hadoop上,使用Hive和MapReduce来分析数据,把分析结果同步到其他数据源。
接下来的问题来了,Hive使用的越来越多,你会发现很多不爽的地方,特别是速度慢,大多情况下,明明我的数据量很小,它都要申请资源,启动MapReduce来执行。
第五章:快一点吧,我的SQL
其实大家都已经发现Hive后台使用MapReduce作为执行引擎,实在是有点慢。
因此SQL On Hadoop的框架越来越多,按我的了解,最常用的按照流行度依次为SparkSQL、Impala和Presto.
这三种框架基于半内存或者全内存,提供了SQL接口来快速查询分析Hadoop上的数据。关于三者的比较,请参考1.1.
我们目前使用的是SparkSQL,至于为什么用SparkSQL,原因大概有以下吧:
使用Spark还做了其他事情,不想引入过多的框架;
Impala对内存的需求太大,没有过多资源部署;
5.1 关于Spark和SparkSQL
什么是Spark,什么是SparkSQL。
Spark有的核心概念及名词解释。
SparkSQL和Spark是什么关系,SparkSQL和Hive是什么关系。
SparkSQL为什么比Hive跑的快。
5.2 如何部署和运行SparkSQL
Spark有哪些部署模式?
如何在Yarn上运行SparkSQL?
使用SparkSQL查询Hive中的表。
PS: Spark不是一门短时间内就能掌握的技术,因此建议在了解了Spark之后,可以先从SparkSQL入手,循序渐进。
第六章:一夫多妻制
请不要被这个名字所诱惑。其实我想说的是数据的一次采集、多次消费。
在实际业务场景下,特别是对于一些监控日志,想即时的从日志中了解一些指标(关于实时计算,后面章节会有介绍),这时候,从HDFS上分析就太慢了,尽管是通过Flume采集的,但Flume也不能间隔很短就往HDFS上滚动文件,这样会导致小文件特别多。
为了满足数据的一次采集、多次消费的需求,这里要说的便是Kafka。
6.1 关于Kafka
什么是Kafka?
Kafka的核心概念及名词解释。
6.2 如何部署和使用Kafka
使用单机部署Kafka,并成功运行自带的生产者和消费者例子。
使用Java程序自己编写并运行生产者和消费者程序。
Flume和Kafka的集成,使用Flume监控日志,并将日志数据实时发送至Kafka。
这时,使用Flume采集的数据,不是直接到HDFS上,而是先到Kafka,Kafka中的数据可以由多个消费者同时消费,其中一个消费者,就是将数据同步到HDFS。
你应该已经具备以下技能和知识点:
为什么Spark比MapReduce快。
使用SparkSQL代替Hive,更快的运行SQL。
使用Kafka完成数据的一次收集,多次消费架构。
自己可以写程序完成Kafka的生产者和消费者。
从前面的学习,你已经掌握了大数据平台中的数据采集、数据存储和计算、数据交换等大部分技能,而这其中的每一步,都需要一个任务(程序)来完成,各个任务之间又存在一定的依赖性,比如,必须等数据采集任务成功完成后,数据计算任务才能开始运行。如果一个任务执行失败,需要给开发运维人员发送告警,同时需要提供完整的日志来方便查错。
第七章:越来越多的分析任务
不仅仅是分析任务,数据采集、数据交换同样是一个个的任务。这些任务中,有的是定时触发,有点则需要依赖其他任务来触发。当平台中有几百上千个任务需要维护和运行时候,仅仅靠crontab远远不够了,这时便需要一个调度监控系统来完成这件事。调度监控系统是整个数据平台的中枢系统,类似于AppMaster,负责分配和监控任务。
7.1 Apache Oozie
-
Oozie是什么?有哪些功能?
-
Oozie可以调度哪些类型的任务(程序)?
-
Oozie可以支持哪些任务触发方式?
- 安装配置Oozie。
7.2 其他开源的任务调度系统
Azkaban:
light-task-scheduler:
Zeus:
等等……
第八章:我的数据要实时
在第六章介绍Kafka的时候提到了一些需要实时指标的业务场景,实时基本可以分为绝对实时和准实时,绝对实时的延迟要求一般在毫秒级,准实时的延迟要求一般在秒、分钟级。对于需要绝对实时的业务场景,用的比较多的是Storm,对于其他准实时的业务场景,可以是Storm,也可以是Spark Streaming。当然,如果可以的话,也可以自己写程序来做。大数据学习群142973723
8.1 Storm
-
什么是Storm?有哪些可能的应用场景?
-
Storm由哪些核心组件构成,各自担任什么角色?
-
Storm的简单安装和部署。
- 自己编写Demo程序,使用Storm完成实时数据流计算。
8.2 Spark Streaming
-
什么是Spark Streaming,它和Spark是什么关系?
-
Spark Streaming和Storm比较,各有什么优缺点?
- 使用Kafka + Spark Streaming,完成实时计算的Demo程序。
至此,你的大数据平台底层架构已经成型了,其中包括了数据采集、数据存储与计算(离线和实时)、数据同步、任务调度与监控这几大模块。接下来是时候考虑如何更好的对外提供数据了。
第九章:我的数据要对外
通常对外(业务)提供数据访问,大体上包含以下方面:
离线:比如,每天将前一天的数据提供到指定的数据源(DB、FILE、FTP)等;离线数据的提供可以采用Sqoop、DataX等离线数据交换工具。
实时:比如,在线网站的推荐系统,需要实时从数据平台中获取给用户的推荐数据,这种要求延时非常低(50毫秒以内)。
根据延时要求和实时数据的查询需要,可能的方案有:HBase、Redis、MongoDB、ElasticSearch等。
OLAP分析:OLAP除了要求底层的数据模型比较规范,另外,对查询的响应速度要求也越来越高,可能的方案有:Impala、Presto、SparkSQL、Kylin。如果你的数据模型比较规模,那么Kylin是最好的选择。
即席查询:即席查询的数据比较随意,一般很难建立通用的数据模型,因此可能的方案有:Impala、Presto、SparkSQL。
这么多比较成熟的框架和方案,需要结合自己的业务需求及数据平台技术架构,选择合适的。原则只有一个:越简单越稳定的,就是最好的。
第十章:逼格高的机器学习
关于这块,大讲台老师只是简单介绍一下了。
在我们的业务中,遇到的能用机器学习解决的问题大概这么三类:
分类问题:包括二分类和多分类,二分类就是解决了预测的问题,就像预测一封邮件是否垃圾邮件;多分类解决的是文本的分类;
聚类问题:从用户搜索过的关键词,对用户进行大概的归类。
推荐问题:根据用户的历史浏览和点击行为进行相关推荐。
大多数行业,使用机器学习解决的,也就是这几类问题。
入门学习线路: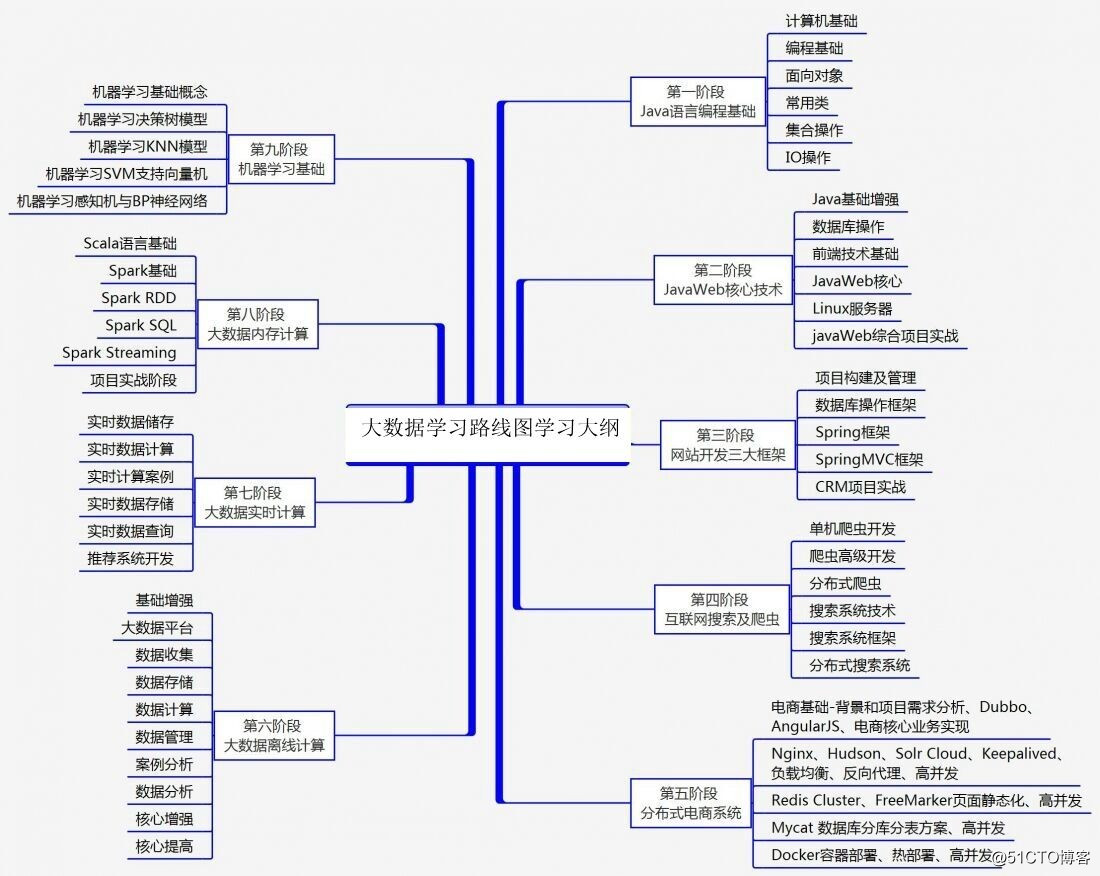
数学基础;
机器学习实战(Machine Learning in Action),懂Python最好;
以上是关于女生如果学大数据怎么样?的主要内容,如果未能解决你的问题,请参考以下文章