DataWhale概率统计3——常见分布与假设检验
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataWhale概率统计3——常见分布与假设检验相关的知识,希望对你有一定的参考价值。
参考技术A 根据随机变量可能取值的个数分为离散型(取值有限)和连续性(取值无限)两类。对于离散型随机变量,使用概率质量函数(probability mass function),简称PMF,来变数其分布律。假定离散型随机变量X,共有n个取值, ,那么
用到PMF的例子:二项分布,泊松分布
对于连续型随机变量,使用概率密度函数(probability density function),简称PDF,来描述其分布情况。
连续型随机变量的特点在于取任何固定值的概率都为0,因此讨论其在特定值上的概率是没有意义的,应当讨论其在某一区间范围内的概率,这就用到了概率密度函数的概念。
假定连续型随机变量X,f(x)为概率密度函数,对于任意实数范围如[a,b],有
用到PDF的例子:均匀分布,正态分布,指数分布
对于连续型随机变量,通常还会用到累计分布函数(cumulative distribution function),简称CDF,来描述其性质,在数学上CDF是PDF的积分形式。
分布函数F(x)在点x处的函数值表示X落在区间(-∞,x]内的概率,所以分布函数就是定义域为R的一个普通函数,因此我们可以把概率问题转化为函数问题,从而可以利用普通函数的知识来研究概率问题,增大了概率的研究范围。
二项分布可以认为是一种只有两种结果(成功/失败)的单次试验重复多次后成功次数的分布概率。
二项分布需要满足以下条件:
1.试验次数是固定的;
2.每次试验都是独立的;
3.对于每次试验成功的概率都是一样的
一些二项分布的例子:
1.销售电话成功的次数
2.一批产品中有缺陷的产品数量
3.掷硬币正面朝上的次数
4.在一袋糖果中取糖果吃,拿到红色包装的次数
在n次试验中,单次试验成功率为p,失败率q=1-p,则出现成功次数的概率为
泊松分布是用来描述泊松试验的一种分布,满足以下两个特征的试验可以认为是泊松试验:
1.所考察的事件在任意两个长度相等的区间里发生一次的机会均等
2.所考察的事件在任何一个区间里发生与否和在其他区间里发生与否没有互相影响,即是独立的
泊松分布需要满足一些条件:
1.试验次数n趋向于无穷大
2.单次事件发生的概率p趋向于0
3.np是一个有限的数值
一些例子:
1.一定时间段内,某航空公司接到的订票电话数
2.一定时间内,到车站等候公交汽车的人数
3.一匹布上发现的瑕疵点的个数
4.一定页数的书刊上出现的错别字个数
一个服从泊松分布的随机变量X,在具有比率参数(rate parameter) ( )的一段固定时间间隔内,事件发生次数为i的概率为
这三个分布之间具有非常微妙的关联
当n很大,p很小时,如n>=100 and np<=10时,二项分布可以近似为泊松分布
当 很大时,如 >=1000时,泊松分布可以近似为正态分布。
当n很大时,np和n(1-p)都足够大时,如n>=100, np>=10,n(1-p)>=10 时,二项分布可以近似为正态分布
除了二项分布和泊松分布以外,还有一些其他的不太常用的离散型分布
1.几何分布: 考虑独立重复试验,几何分布描述的是经过k次试验才首次获得成功的概率,假定每次成功率为p
2.负二项分布: 考虑独立重复试验,负二项分布描述的是试验一直进行到成功r次的概率,假定每次成功率为p
3.超几何分布: 超几何分布描述的是在一个总数为N的总体中进行有放回的抽样,其中在总体中k个元素属于一组,剩余N-k个元素属于另一组,假定从总体中抽取n次,其中包含x个第一组的概率为
均匀分布是指一类在定义域内概率密度函数处处相等的统计分布
若X是服从区间[a,b]上的均匀分布,则记作X~U[a,b].
均匀分布的一些例子:
1.一个理想的随机数生成器
2.一个理想的圆盘以一定力度旋转后静止时的角度
正态分布又叫高斯分布,是最常见的统计分布之一,是一种对称的分布,概率密度函数呈现钟摆的形状。
正态分布的一些例子:
1.成人的身高
2.不同方向的气体分子的运动速度
3.测量物体质量时的误差
正态分布在现实生活中有非常多的例子,这一点可以从中心极限定理来解释,中心极限定理说的是一组独立分布的随机样本的平均值近似为正态分布,无论随机变量的总体符合何种分布。
指数分布通常被广泛用在描述一个特定事件繁盛所需要的时间,在指数分布随机变量的分布中,有着很少的大数值和非常多的小数值。
指数分布的一些例子
1.顾客到达一家店铺的时间间隔
2.从现在开始到发生地震的时间间隔
3.在产线上收到一个问题产品的时间间隔
关于指数分布还有一个有趣的性质:指数分布是无记忆性的,假定在等候事件发生的过程中,已经过了一些时间,此时距离下一次事件发生的时间间隔的分布情况和最开始是完全一样的,就好像中间等候的那一段时间完全没有发生一样,也不会对结果有任何的影响
分布
常用来描述某个事件总共要发生n次的等待时间的分布
威尔布分布
常用来描述在工程领域中某类具有‘最弱链’对象的寿命
假设检验问题是统计推断中的一类重要问题,在总体的分布函数完全未知或只知其形式,不知其参数的情况,为了推断总体的某些未知特征,提出某些关于总体的假设,这类问题被称为假设检验。
一个假设检验问题可以分为5步,无论细节如何变化,都一定会遵循这5个步骤。
1.陈述研究假设,包含原假设和备择假设:通常来说,我们会把原假设的描述写成变量之间不存在某种差异,或不存在某种关联,备择假设则为存在某种差异或关联。例如,原假设:男人和女人的平均身高没有差别,备择假设男人和女人的平均身高存在显著差别
2.为验证假设收集数据:为了统计检验的结果真实可靠,需要根据实际的假设命题从总体中抽取样本,要求抽样的数据要具有代表性,例如在上述男女平均身高的命题中,抽取样本要覆盖全面
3.构造合适的统计测试量并测试:统计检验量有很多种类,但是所有的统计检验都是基于组内方差和组间方差的比较,如果组间方差足够大,使得不同组之间几乎没有重叠,那么统计量会反映出一个非常小的P值,意味着不同组之间的差异不可能是由偶然性导致的
4.决定是接收还是拒绝原假设:基于统计量的结果做出接收或拒绝原假设的判断,通常我们会以P=0.05作为临界值(单侧检验)
5.展示结论
选择合适的统计量是进行假设检验的关键步骤,最常用的统计检验保罗回归检验,比较检验和关联检验三类
回归检验
回归检验适用于预测变量是数值型的情况,根据预测变量的数量和结果变量的类型又分为以下几种:
1.简单线性回归,预测变量:单个连续数值,结果变量:连续数值
2.多重线性回归,预测变量:多个连续数值,结果变量:连续数值
3.Logistic回归,预测变量:连续数值,结果变量:二元类别
比较检验
比较检验适用于预测变量是类别型,结果变量是数值型的情况,根据预测变量的分组数量和结果变量的数量又可以分为多种
关联检验
关联检验常用的只有卡方检验一种,适用于预测变量和结果变量均为类别型的情况
非参数检验
由于一般来说上述参数检验都需满足一些前提条件,样本之间独立,不同组的组内方差近似和数据满足正态性,所以当这些条件不满足时,我们可以用非参数检验来代替参数检验
当我们进行假设检验的过程中是存在犯错误的可能的,并且理论上来说错误是无法完全避免的。根据定义,错误分为两类,一类错误和二类错误
1.一类错误:拒绝真的原假设
2.二类错误:接受错误的原假设
一类错误可以通过α值来控制,在假设检验中选择的α(显著性水平)对一类错误有着直接影响。α可以认为是我们犯一类错误的最大可能性。以95%的置信水平为例,α=0.05,这意味着我们拒绝一个真的原假设的可能性是5%。从长期来看,每做20次假设检验会有一次犯一类错误的事件发生。
二类错误通常是由小样本或高样本方差导致的,二类错误的概率可以用β表示,和一类不一样的是,此类错误不能通过设置一个错误率来控制。对于二类错误,可以从功效的角度来估计,受限进行功效分析计算出功效值1-β,进而得到二类错误的估计值β。
一般来说这两类错误是无法同时降低的,在降低犯一类错误的前提下会增加犯二类错误的可能性,在实际案例中如何平衡着两类错误取决于我们更能接受一类错误还是二类错误。
分布图
分布图通过将数据的经验分布与指定分布预期的理论值进行比较,直观地评估样本数据的分布。除了更正式的假设检验之外,还使用分布图来确定样本数据是否来自指定的分布。要了解假设检验,请参阅假设检验。
统计和机器学习工具箱™提供了几种分布图选项:
正态概率图
使用正态概率图来评估数据是否来自正态分布。许多统计程序假设基础分布是正常的。正态概率图可以提供一些保证来证明这一假设,或者提供对假设问题的警告。对正态性的分析通常将正态概率图与正态性的假设检验相结合。
该示例从具有平均值10和标准偏差1的正态分布生成25个随机数的数据样本,并创建数据的正态概率图。
可直接联系客服QQ交代需求:953586085
rng(‘default‘); %为了再现性 x = normrnd(10,1,[25,1]); normplot(x)的
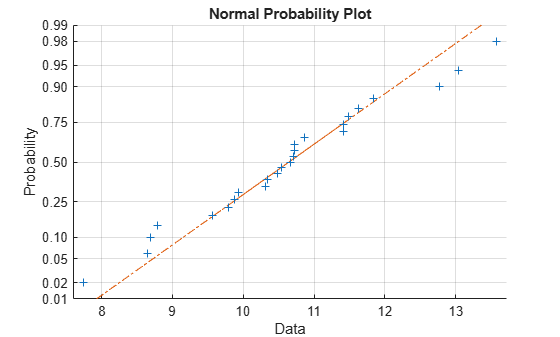
加号标出经验概率与数据中每个点的数据值。实线连接数据中的第25和第75百分位数,虚线将其扩展到数据的末尾。所述ÿ -轴的值从零到一的概率,但规模不是线性的。y轴上的刻度线之间的距离与正态分布的分位数之间的距离相匹配。分位数在中位数(第50百分位数)附近靠近在一起,并且当您远离中位数时对称地伸展。
在正态概率图中,如果所有数据点都落在该线附近,则正态假设是合理的。否则,正常假设是不合理的。例如,下面从指数分布生成100个随机数的数据样本,平均值为10,并创建数据的正态概率图。
x = exprnd(10,100,1); normplot(x)的
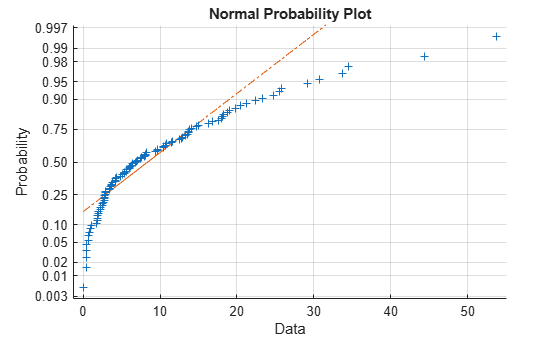
该图是有力证据表明基础分布不正常。
概率图
与正态概率图一样,概率图只是按比例缩放到特定分布的经验cdf图。所述ÿ -轴的值从零到一的概率,但规模不是线性的。刻度线之间的距离是分布的分位数之间的距离。在图中,在数据的第一个和第三个四分位之间绘制一条线。如果数据落在线附近,则选择分布作为数据模型是合理的。分布分析通常将概率图与特定分布的假设检验相结合。
创建Weibull概率图
生成样本数据并创建概率图。
生成样本数据。样本x1包含来自具有比例参数A = 3和形状参数的Weibull分布的500个随机数B = 3。样本x2包含来自具有比例参数的瑞利分布的500个随机数B = 3。
rng(‘default‘); %为了再现性 x1 = wblrnd(3,3,[500,1]); x2 = raylrnd(3,[500,1]);
创建概率图,以评估是否在数据x1和x2来自韦伯分布。
数字 probplot(‘ weibull ‘,[x1 x2]) 传奇(‘Weibull Sample‘,‘Rayleigh Sample‘,‘Location‘,‘best‘)
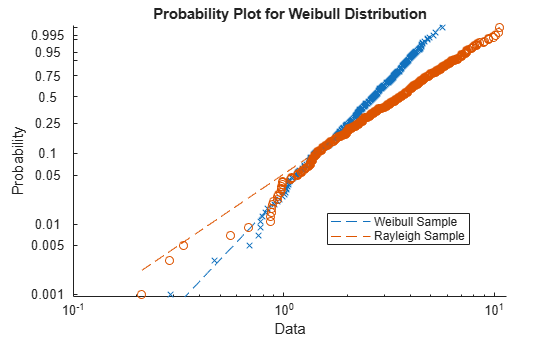
概率图显示数据x1来自Weibull分布,而数据x2则不是。
或者,您可以使用wblplot创建威布尔概率图。
分位数 - 分位数图
使用分位数 - 分位数(qq)图来确定两个样本是否来自同一分布族。QQ图是从每个样本计算的分位数的散点图,在第一和第三四分位数之间绘制线。如果数据落在线附近,则可以合理地假设两个样本来自相同的分布。该方法对于任一分布的位置和规模的变化是稳健的。
使用该qqplot函数创建分位数 - 分位数图。
以下示例生成两个数据样本,其包含来自具有不同参数值的泊松分布的随机数,并创建分位数 - 分位数图。数据x来自泊松分布,均值为10,数据y来自泊松分布,均值为5。
x = poissrnd(10,[50,1]); y = poissrnd(5,[100,1]); qqplot(X,Y)
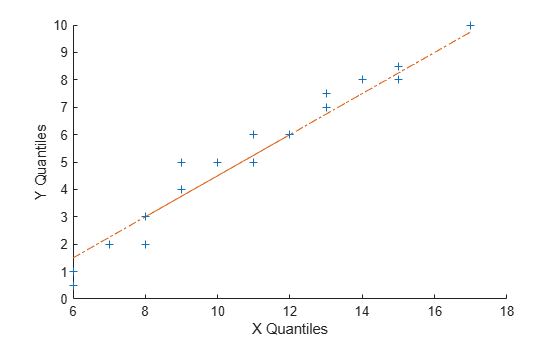
即使参数和样本大小不同,近似线性关系表明两个样本可能来自同一分布族。与正态概率图一样,假设检验可以为这种假设提供额外的理由。然而,对于依赖于来自相同分布的两个样本的统计过程,线性分位数 - 分位数图通常就足够了。
以下示例显示了基础分布不相同时会发生什么。这里,x包含从平均值为5和标准差为1的正态分布生成的100个随机数,同时y包含由Weibull分布生成的100个随机数,其中比例参数为2,形状参数为0.5。
x = normrnd(5,1,[100,1]); y = wblrnd(2,0.5,[100,1]); qqplot(X,Y)
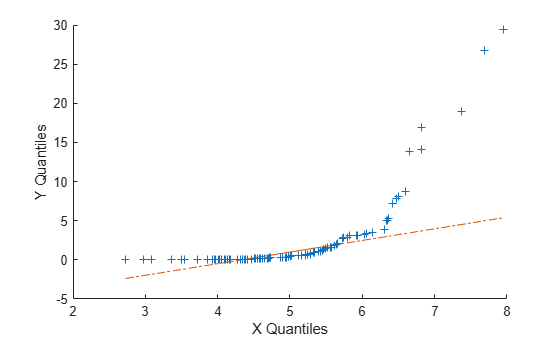
该图表明这些样品显然不是来自同一分布族。
累积分布图
经验累积分布函数(cdf)图显示小于或等于每个x值的数据的比例,作为x的函数 。y轴上的比例是线性的; 特别是,它没有扩展到任何特定的分布。经验cdf图用于比较特定分布的数据cdfs和cdfs。
要创建经验cdf图,请使用cdfplot函数或ecdf函数。
将Empirical cdf与理论cdf进行比较
绘制样本数据集的经验cdf,并将其与样本数据集的基础分布的理论cdf进行比较。在实践中,理论上的cdf可能是未知的。
使用位置参数0和比例参数3从极值分布生成随机样本数据集。
rng(‘default‘) %对于再现性 y = evrnd(0,3,100,1);
在同一图上绘制样本数据集的经验cdf和理论cdf。
cdfplot(y)的 坚持下去 x = linspace(min(y),max(y)); 图(X,evcdf(X,0,3)) 传奇(‘经济CDF‘,‘理论CDF‘,‘位置‘,‘最佳‘) 持有关闭
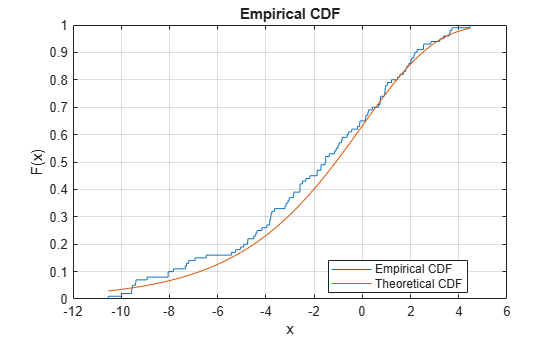
该图显示了经验cdf和理论cdf之间的相似性。
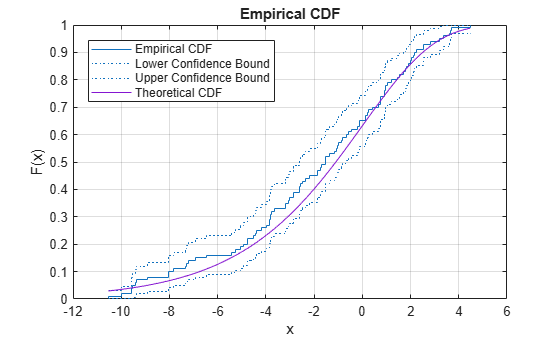
或者,您可以使用该ecdf功能。该ecdf函数还绘制了使用格林伍德公式估算的95%置信区间。有关详细信息,请参阅Greenwood的公式。
ecdf(y,‘Bounds‘,‘on‘) 坚持下去 图(X,evcdf(X,0,3)) 网格上 的标题(“实证CDF”) 传奇(‘经验CDF‘,‘较低置信度‘,‘上置信度‘,‘理论CDF‘,‘位置‘,‘最佳‘) 持有关闭
以上是关于DataWhale概率统计3——常见分布与假设检验的主要内容,如果未能解决你的问题,请参考以下文章