分布图
Posted chenbocheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布图相关的知识,希望对你有一定的参考价值。
分布图通过将数据的经验分布与指定分布预期的理论值进行比较,直观地评估样本数据的分布。除了更正式的假设检验之外,还使用分布图来确定样本数据是否来自指定的分布。要了解假设检验,请参阅假设检验。
统计和机器学习工具箱™提供了几种分布图选项:
正态概率图
使用正态概率图来评估数据是否来自正态分布。许多统计程序假设基础分布是正常的。正态概率图可以提供一些保证来证明这一假设,或者提供对假设问题的警告。对正态性的分析通常将正态概率图与正态性的假设检验相结合。
该示例从具有平均值10和标准偏差1的正态分布生成25个随机数的数据样本,并创建数据的正态概率图。
可直接联系客服QQ交代需求:953586085
rng(‘default‘); %为了再现性 x = normrnd(10,1,[25,1]); normplot(x)的
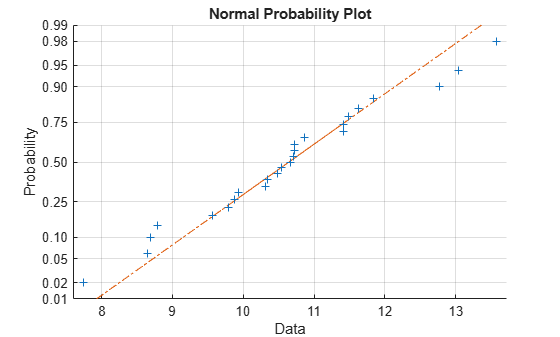
加号标出经验概率与数据中每个点的数据值。实线连接数据中的第25和第75百分位数,虚线将其扩展到数据的末尾。所述ÿ -轴的值从零到一的概率,但规模不是线性的。y轴上的刻度线之间的距离与正态分布的分位数之间的距离相匹配。分位数在中位数(第50百分位数)附近靠近在一起,并且当您远离中位数时对称地伸展。
在正态概率图中,如果所有数据点都落在该线附近,则正态假设是合理的。否则,正常假设是不合理的。例如,下面从指数分布生成100个随机数的数据样本,平均值为10,并创建数据的正态概率图。
x = exprnd(10,100,1); normplot(x)的
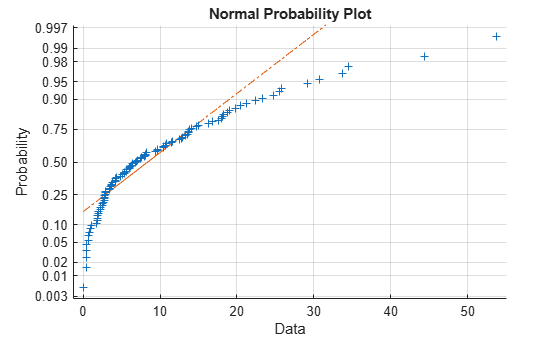
该图是有力证据表明基础分布不正常。
概率图
与正态概率图一样,概率图只是按比例缩放到特定分布的经验cdf图。所述ÿ -轴的值从零到一的概率,但规模不是线性的。刻度线之间的距离是分布的分位数之间的距离。在图中,在数据的第一个和第三个四分位之间绘制一条线。如果数据落在线附近,则选择分布作为数据模型是合理的。分布分析通常将概率图与特定分布的假设检验相结合。
创建Weibull概率图
生成样本数据并创建概率图。
生成样本数据。样本x1包含来自具有比例参数A = 3和形状参数的Weibull分布的500个随机数B = 3。样本x2包含来自具有比例参数的瑞利分布的500个随机数B = 3。
rng(‘default‘); %为了再现性 x1 = wblrnd(3,3,[500,1]); x2 = raylrnd(3,[500,1]);
创建概率图,以评估是否在数据x1和x2来自韦伯分布。
数字 probplot(‘ weibull ‘,[x1 x2]) 传奇(‘Weibull Sample‘,‘Rayleigh Sample‘,‘Location‘,‘best‘)
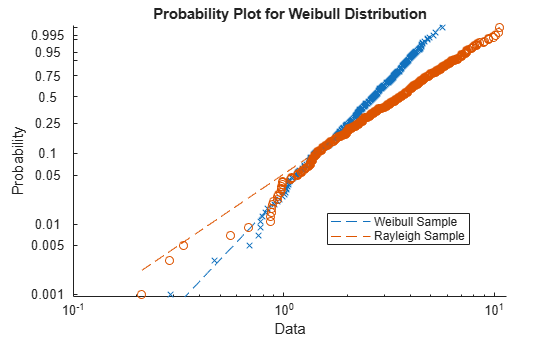
概率图显示数据x1来自Weibull分布,而数据x2则不是。
或者,您可以使用wblplot创建威布尔概率图。
分位数 - 分位数图
使用分位数 - 分位数(qq)图来确定两个样本是否来自同一分布族。QQ图是从每个样本计算的分位数的散点图,在第一和第三四分位数之间绘制线。如果数据落在线附近,则可以合理地假设两个样本来自相同的分布。该方法对于任一分布的位置和规模的变化是稳健的。
使用该qqplot函数创建分位数 - 分位数图。
以下示例生成两个数据样本,其包含来自具有不同参数值的泊松分布的随机数,并创建分位数 - 分位数图。数据x来自泊松分布,均值为10,数据y来自泊松分布,均值为5。
x = poissrnd(10,[50,1]); y = poissrnd(5,[100,1]); qqplot(X,Y)
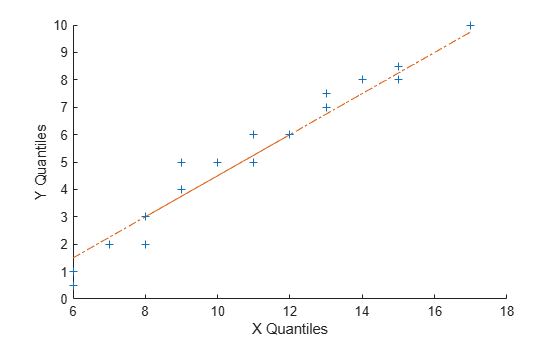
即使参数和样本大小不同,近似线性关系表明两个样本可能来自同一分布族。与正态概率图一样,假设检验可以为这种假设提供额外的理由。然而,对于依赖于来自相同分布的两个样本的统计过程,线性分位数 - 分位数图通常就足够了。
以下示例显示了基础分布不相同时会发生什么。这里,x包含从平均值为5和标准差为1的正态分布生成的100个随机数,同时y包含由Weibull分布生成的100个随机数,其中比例参数为2,形状参数为0.5。
x = normrnd(5,1,[100,1]); y = wblrnd(2,0.5,[100,1]); qqplot(X,Y)
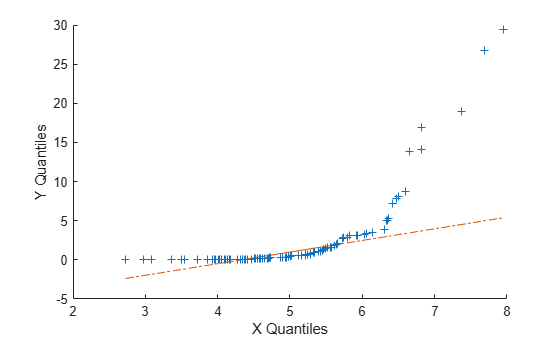
该图表明这些样品显然不是来自同一分布族。
累积分布图
经验累积分布函数(cdf)图显示小于或等于每个x值的数据的比例,作为x的函数 。y轴上的比例是线性的; 特别是,它没有扩展到任何特定的分布。经验cdf图用于比较特定分布的数据cdfs和cdfs。
要创建经验cdf图,请使用cdfplot函数或ecdf函数。
将Empirical cdf与理论cdf进行比较
绘制样本数据集的经验cdf,并将其与样本数据集的基础分布的理论cdf进行比较。在实践中,理论上的cdf可能是未知的。
使用位置参数0和比例参数3从极值分布生成随机样本数据集。
rng(‘default‘) %对于再现性 y = evrnd(0,3,100,1);
在同一图上绘制样本数据集的经验cdf和理论cdf。
cdfplot(y)的 坚持下去 x = linspace(min(y),max(y)); 图(X,evcdf(X,0,3)) 传奇(‘经济CDF‘,‘理论CDF‘,‘位置‘,‘最佳‘) 持有关闭
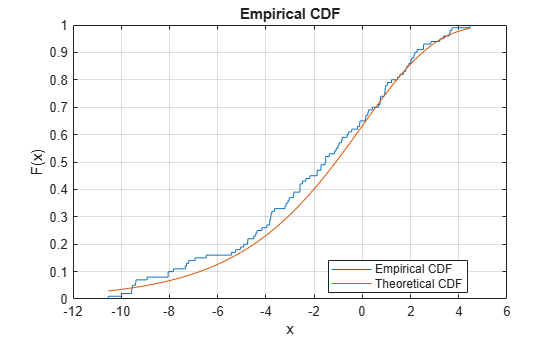
该图显示了经验cdf和理论cdf之间的相似性。
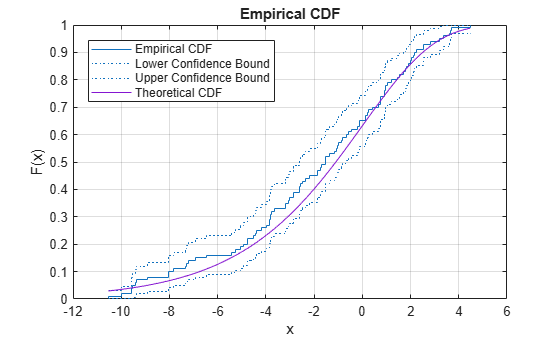
或者,您可以使用该ecdf功能。该ecdf函数还绘制了使用格林伍德公式估算的95%置信区间。有关详细信息,请参阅Greenwood的公式。
ecdf(y,‘Bounds‘,‘on‘) 坚持下去 图(X,evcdf(X,0,3)) 网格上 的标题(“实证CDF”) 传奇(‘经验CDF‘,‘较低置信度‘,‘上置信度‘,‘理论CDF‘,‘位置‘,‘最佳‘) 持有关闭
以上是关于分布图的主要内容,如果未能解决你的问题,请参考以下文章