Hadoop-hdfs分布式集群搭建
Posted pig-driving-spacecraft
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-hdfs分布式集群搭建相关的知识,希望对你有一定的参考价值。
第一步:准备n台linux服务器
我这里使用的是3台CentOS6.5版本的linux虚拟机,1个namenode节点 + 2个datanode 节点。
第二步:给3台虚拟机分配IP并修改hosts文件
主机名:hdp-01 对应的ip地址:192.168.33.61
主机名:hdp-02 对应的ip地址:192.168.33.62
主机名:hdp-03 对应的ip地址:192.168.33.63
1.修改主机名 (/etc/sysconfig/network)

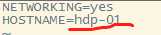
2.修改IP(/etc/sysconfig/network-scripts/ifcfg-eth0)

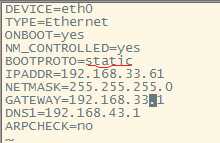
3.修改hosts文件(/etc/hosts)
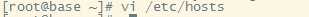

4.重启linux虚拟机
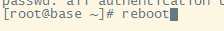
按照以上5步完成3台虚拟机IP分配和hosts文件修改
第三步 配置linux服务器的基础软件环境
1.关闭防火墙以及防火墙自启(学习时会省去不少麻烦)

2.添加用户并设置密码
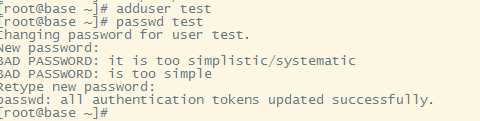
3.切换到新添用户test

4.安装JDK
上传JDK安装包到当前用户home目录下,并解压至/home/test/apps/目录下

配置JDK环境变量
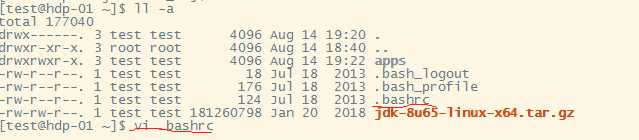

使环境变量生效
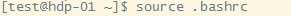
检查是否安装成功

将安装好的jdk目录用scp命令拷贝到其他机器
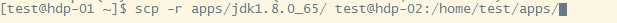
将/home/test/.bashrc配置文件也用scp命令拷贝到其他机器并分别执行source命令
第四步:安装hadoop
1.上传hadoop安装包到当前用户home目录下,并解压至/home/test/apps/目录下,再配置环境变量

2、修改配置文件
核心配置参数:
1) 指定hadoop的默认文件系统为:hdfs
2) 指定hdfs的namenode节点为哪台机器
3) 指定namenode软件存储元数据的本地目录
4) 指定datanode软件存放文件块的本地目录
hadoop的配置文件在:/home/test/apps/hadoop-2.7.3/etc/hadoop/下
修改hadoop-env.sh


修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-01:9000</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/test/data/hdpdata/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/test/data/hdpdata/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdp-02:50090</value>
</property>
</configuration>
拷贝整个hadoop安装目录到其他机器
第五步:启动hdfs
首先,初始化namenode的元数据目录
在hdp-01上执行hadoop命令hadoop namenode -format来初始化namenode的元数据存储目录

启动完后,首先用jps查看一下namenode的进程是否存在
然后,在windows中用浏览器访问namenode提供的web端口:50070 http://hdp-01:50070
然后,启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
第六步:用自动批量启动脚本来启动HDFS
1) 先配置hdp-01到集群中所有机器(包含自己)的免密登陆
2) 配完免密后,可以执行一次 ssh 0.0.0.0
3) 修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)

4) 在hdp-01上用脚本:start-dfs.sh 来自动启动整个集群
5) 如果要停止,则用脚本:stop-dfs.sh
以上是关于Hadoop-hdfs分布式集群搭建的主要内容,如果未能解决你的问题,请参考以下文章