《大数据开发》Hadoop-HDFS
Posted Steve_Abelieve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《大数据开发》Hadoop-HDFS相关的知识,希望对你有一定的参考价值。
快速入门
官方文档
Hadoop
Hadoop 是一个开源的, 可靠的(reliable), 可扩展的(scalable)分布式计算框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集(python java …)。
可扩展: 从单个服务器可以横向扩张到数千台计算机,每台计算机都提供本地计算和存储。
可靠的: 不依靠硬件来提供高可用性(high-availability),而是在应用层检测和处理故障,从而在计算机集群之上提供高可用服务。
HDFS
Hadoop Distributed File System (HDFs):分布式文件系统,用来存储海量数据。
重要的5个守护进程
不同网络服务器运行一组守护进程,每个进程有着特殊的角色。
- NameNode(名字节点)
- DataNode(数据节点)
- Secondary NameNode(次名字节点)
- JobTracker(作业跟踪节点)
- TaskTracker(任务跟踪节点)
NameNode(名字节点)
Hadoop 分布式计算,分布式存储都是采用了主从结构。分布式存储被称作HDFS。 NameNode位于HDFS主端,指导从端的DataNode执行底层的I/O 任务。
跟踪文件如何被分割成文件块,而这些块又被哪些几点存储,以及分布式文件系统的整体运行状态是否正常。
DataNode(数据节点)
每个集群的从节点都会驻留一个DataNode守护进程,来执行分布式文件系统的繁重工作,将HDFS数据块读取或者写入到本地文件系统的实际文件中。
由NameNode告知客户端每个数据块驻留在哪个DataNode,客户端直接与DataNode守护进程进行通信。来处理与数据块对应的本地文件,而后,DataNode 与其他DatNode进行通信,复制这些数据块以实现数据冗余。
DataNode 不断向NameNode报告,初始化时,DatNode将当前存储的数据块信息告知NameNode,初始映射完成后,DataNode仍不断更新NameNode,为之提供本地修改相关信息,同时接收指令创建、移动或者删除本地磁盘上的数据块。
- 管理各个datanode
- 管理文件信息,文件名、文件多大、文件被切块、存贮位置信息,即管理元数据信息。
- 基于RPC心跳机制控制集群中各个节点(datanode)的状态。
- namenode存在单点故障问题,可以在起一个SecondaryNameNode用来保证元数据信息安全。
- datanode挂掉后,数据丢失,因此需要控制datanode 的备份,默认3份,本机一份。
Secondary NameNode(次名字节点)
SNN,一个用于检测HDFS集群状态的辅助守护进程,像NameNode一样,每个集群有一个SNN,它通常也独占一台服务器。
SNN与NanmeNode 不同在于它不接收或者记录HDFS的任何实时变化,相反,它与NameNode进行通信,根据集群所配置的时间间隔获取HDFS元数据的快照。
SNN快照有助于减少停机时间并降低数据丢失的风险,
NameNode失效处理需要人工的干预,即手动地重新配置集群,将SNN用作主要的NameNode.
JobTracker(作业跟踪节点)
应用程序和Hadoop之间的纽带,一旦代码提交到集群上,JobTracker将会确定执行计划,包括处理哪些文件,为不同任务分配节点以及监控所有任务的执行。如果任务执行失败,JobTracker将会自动重启任务,但所分配的节点可能会不同,同时受到预定义的重试次数限制。
每个Hadoop集群只有一个JobTracker守护进程,它通常运行在服务器集群的主节点上。
TaskTracker(任务跟踪节点)
管理各个任务在每个从节点上的执行情况。
每个TaskTacker负责执行由JobTacker分配的单项任务。
一个职责是持续不断地与JobTracker进行通信,如果规定时间内,JobTracker没有收到来自的心跳,假定JobTracker已经崩溃了,进行重新提交相应的任务到集群中的其他节点中。
1. 架构图

HDFS 读流程

HDFS 写流程
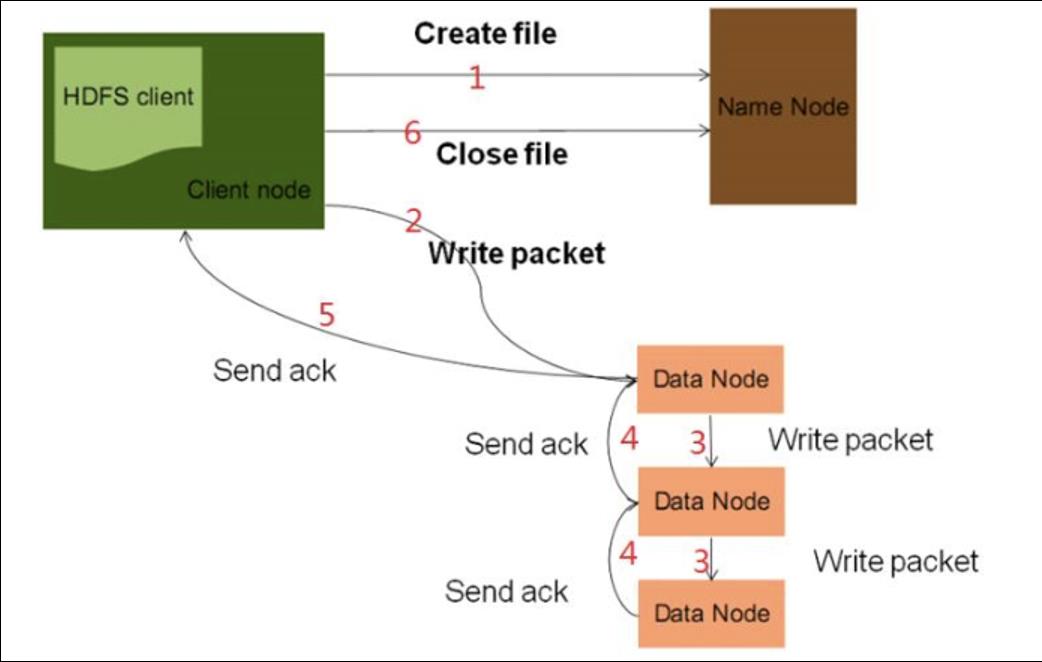
优点:
1.支持文件存储,TB、PB级别的数据,如每日的用户行为log。
2.高容错性
3.横向扩展的花费呈线性
4.快速响应硬件故障
缺点:
1.类似数据库一样的低延迟访问数据,响应时间毫秒级别。
2.不适合大量存储小文件。
3.不适合多次修改数据,写入文件。
以上是关于《大数据开发》Hadoop-HDFS的主要内容,如果未能解决你的问题,请参考以下文章