WebRTC 的音频网络对抗概述
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WebRTC 的音频网络对抗概述相关的知识,希望对你有一定的参考价值。
参考技术AWebRTC 音频数据处理中,期望可以实现音频数据处理及传输,延时低,互动性好,声音平稳无抖动,码率低消耗带宽少等。在数据传输上,WebRTC 采用基于 UDP 的 RTP/RTCP 协议,RTP/RTCP 本身不提供数据的可靠传输及质量保障。公共互联网这种分组交换网络,天然具有数据包传输的丢失、重复、乱序及延时等问题。WebRTC 音频数据处理的这些目标很难同时实现,WebRTC 的音频网络对抗实现中针对不同情况对这些目标进行平衡。
这里更仔细地看一下 WebRTC 音频数据处理管线,并特别关注与音频网络对抗相关的逻辑。
前面在 WebRTC 的音频数据编码及发送控制管线 一文中分析了 WebRTC 的音频数据编码及发送控制相关逻辑,这里再来看一下 WebRTC 的音频数据接收及解码播放过程。
WebRTC 的音频数据接收处理的概念抽象层面的完整流程大体如下:
对于 WebRTC 的音频数据接收处理过程, webrtc::AudioDeviceModule 负责把声音 PCM 数据通过系统接口送进设备播放出来。 webrtc::AudioDeviceModule 内部一般会起专门的播放线程,由播放线程驱动整个解码播放过程。 webrtc::AudioTransport 作为一个适配和胶水模块,它把音频数据播放和 webrtc::AudioProcessing 的音频数据处理及混音等结合起来,它通过 webrtc::AudioMixer 同步获取并混音各个远端音频流,这些混音之后的音频数据除了返回给 webrtc::AudioDeviceModule 用于播放外,还会被送进 webrtc::AudioProcessing ,以作为回声消除的参考信号。 webrtc::AudioMixer::Source / webrtc::AudioReceiveStream 为播放过程提供解码之后的数据。RTCP 反馈在 webrtc::AudioMixer::Source / webrtc::AudioReceiveStream 中会通过 webrtc::Transport 发送出去。 webrtc::Transport 也是一个适配和胶水模块,它通过 cricket::MediaChannel::NetworkInterface 实际将数据包发送网络。 cricket::MediaChannel 从网络中接收音频数据包并送进 webrtc::AudioMixer::Source / webrtc::AudioReceiveStream 。
如果将音频数据接收处理流水线上的适配和胶水模块省掉,音频数据接收处理流水线将可简化为类似下面这样:
webrtc::AudioMixer::Source / webrtc::AudioReceiveStream 是整个过程的中心,其实现位于 webrtc/audio/audio_receive_stream.h / webrtc/audio/audio_receive_stream.cc ,相关的类层次结构如下图:
在 RTC 中,为了实现交互和低延迟,音频数据接收处理不能只做包的重排序和解码,它还要充分考虑网络对抗,如 PLC 及发送 RTCP 反馈等,这也是一个相当复杂的过程。WebRTC 的设计大量采用了控制流与数据流分离的思想,这在 webrtc::AudioReceiveStream 的设计与实现中也有体现。分析 webrtc::AudioReceiveStream 的设计与实现时,也可以从配置及控制,和数据流两个角度来看。
可以对 webrtc::AudioReceiveStream 执行的配置和控制主要有如下这些:
对于数据流,一是从网络中接收到的数据包被送进 webrtc::AudioReceiveStream ;二是播放时, webrtc::AudioDeviceModule 从 webrtc::AudioReceiveStream 获得解码后的数据,并送进播放设备播放出来;三是 webrtc::AudioReceiveStream 发送 RTCP 反馈包给发送端以协助实现拥塞控制,对编码发送过程产生影响。
webrtc::AudioReceiveStream 的实现中,最主要的数据处理流程 —— 音频数据接收、解码及播放过程,及相关模块如下图:
这个图中的箭头表示数据流动的方向,数据在各个模块中处理的先后顺序为自左向右。图中下方红色的框中是与网络对抗密切相关的逻辑。
webrtc::AudioReceiveStream 的实现的数据处理流程中,输入数据为音频网络数据包和对端发来的 RTCP 包,来自于 cricket::MediaChannel ,输出数据为解码后的 PCM 数据,被送给 webrtc::AudioTransport ,以及构造的 RTCP 反馈包,如 TransportCC、RTCP NACK 包,被送给 webrtc::Transport 发出去。
webrtc::AudioReceiveStream 的实现内部,音频网络数据包最终被送进 NetEQ 的缓冲区 webrtc::PacketBuffer 里,播放时 NetEQ 做解码、PLC 等,解码后的数据提供给 webrtc::AudioDeviceModule 。
这里先来看一下, webrtc::AudioReceiveStream 实现的这个数据处理流水线的搭建过程。
webrtc::AudioReceiveStream 实现的数据处理管线是分步骤搭建完成的。我们围绕上面的 webrtc::AudioReceiveStream 数据处理流程图 来看这个过程。
在 webrtc::AudioReceiveStream 对象创建,也就是 webrtc::voe::(anonymous namespace)::ChannelReceive 对象创建时,会创建一些关键对象,并建立部分对象之间的联系,这个调用过程如下:
webrtc::AudioReceiveStream 通过 webrtc::Call 创建,传入 webrtc::AudioReceiveStream::Config,其中包含与 NACK、jitter buffer 最大大小、payload type 与 codec 的映射相关,及 webrtc::Transport 等各种配置。
webrtc::voe::(anonymous namespace)::ChannelReceive 对象的构造函数如下:
webrtc::voe::(anonymous namespace)::ChannelReceive 对象的构造函数的执行过程如下:
图中标为绿色的模块为这个阶段已经接入 webrtc::voe::(anonymous namespace)::ChannelReceive 的模块,标为黄色的则为那些还没有接进来的模块;实线箭头表示这个阶段已经建立的连接,虚线箭头则表示还没有建立的连接。
在 ChannelReceive 的 RegisterReceiverCongestionControlObjects() 函数中, webrtc::PacketRouter 被接进来:
这个操作也发生在 webrtc::AudioReceiveStream 对象创建期间。 ChannelReceive 的 RegisterReceiverCongestionControlObjects() 函数的实现如下:
这里 webrtc::PacketRouter 和 webrtc::ModuleRtpRtcpImpl2 被连接起来,前面图中标号为 5 的这条连接也建立起来了。NetEQ 在需要音频解码器时创建音频解码器,这个过程这里不再赘述。
这样 webrtc::AudioReceiveStream 内部的数据处理管线的状态变为如下图所示:
webrtc::AudioReceiveStream 的生命周期函数 Start() 被调用时, webrtc::AudioReceiveStream 被加进 webrtc::AudioMixer :
这样 webrtc::AudioReceiveStream 的数据处理管线就此搭建完成。整个音频数据处理管线的状态变为如下图所示:
WebRTC 音频数据接收处理的实现中,保存从网络上接收的音频数据包的缓冲区为 NetEQ 的 webrtc::PacketBuffer ,收到音频数据包并保存进 NetEQ 的 webrtc::PacketBuffer 的过程如下面这样:
播放时, webrtc::AudioDeviceModule 最终会向 NetEQ 请求 PCM 数据,此时 NetEQ 会从 webrtc::PacketBuffer 中取出数据包并解码。网络中传输的音频数据包中包含的音频采样点和 webrtc::AudioDeviceModule 每次请求的音频采样点不一定是完全相同的,比如采样率为 48kHz 的音频, webrtc::AudioDeviceModule 每次请求 10ms 的数据,也就是 480 个采样点,而 OPUS 音频编解码器每个编码帧中包含 20ms 的数据,也就是 960 个采样点,这样 NetEQ 返回 webrtc::AudioDeviceModule 每次请求的采样点之后,可能会有解码音频数据的剩余,这需要一个专门的 PCM 数据缓冲区。这个数据缓冲区为 NetEQ 的 webrtc::SyncBuffer 。
webrtc::AudioDeviceModule 请求播放数据的大体过程如下面这样:
更加仔细地审视 WebRTC 的音频数据处理、编码和发送过程,更完整地将网络对抗考虑进来, WebRTC 的音频数据处理、编码和发送过程,及相关模块如下图:
在 WebRTC 的音频数据处理、编码和发送过程中,编码器对于网络对抗起着巨大的作用。WebRTC 通过一个名为 audio network adapter (ANA) 的模块,根据网络状况,对编码过程进行调节。
pacing 模块平滑地将媒体数据发送到网络,拥塞控制 congestion control 模块通过影响 pacing 模块来影响媒体数据发送的过程,以达到控制拥塞的目的。
由 WebRTC 的音频采集、处理、编码和发送过程,及音频的接收、解码、处理及播放过程,可以粗略梳理出 WebRTC 的音频网络对抗的复杂机制:
没看到 WebRTC 有音频带外 FEC 机制的实现。
参考文章
干货|一文读懂腾讯会议在复杂网络下如何保证高清音频
Done.
WebRTC音频系统 之audio技术栈简介-1
文章目录
WebRTC是Google开源的Web实时音视频通信框架,其提供P2P的音频、视频和一般数据传输协议栈的支持,其音频主要包括:采集播放、众多音频编解码器、语音增强、回声消除、网络均衡和拥塞控制等音频处理单元,其视频主要包括:采集播放,丢包隐藏,视频增强和编解码几个部分,支持的编解码有H264、VP8,VP9,AV1、H265,在网络方面WebRTC提供针对音视频的动态抖动buffer管理和丢包隐藏处理,另外也提供基于STURN和TRUN的P2P的多媒体数据传输。WebRTC的时音视频通信技术栈实现很,有技术含量,这体现在将硬件、流媒体、网络、信令在实时视频会议中进行了抽象归纳解耦,这使得各个模块大部分都可并行开发,本书以WebRTC自带的Native c++例子着重分析音视频处理技术栈,音视频算法原理并不是本书的重点,比如AEC算法,只涉及API的调用而不涉及AEC内部实现的细节。
第一章 WebRTC技术栈简介
标准和源码是研究WebRTC的第一手资料,而标准和源码也是在持续的演进,在编译native源的该时候,可以生成各个模块的测试二进制程序,通过这些二进制程序熟悉各个模块的使用方法,比如APM模块的可执行二进制测试程序是audioproc_f,各个模块的组成见1.4小节,图1-3,测试程序包括了音视频以及网络部分,和native 测试app,其测试程序见下图红色部分:
图1-1 MacOS上WebRTC native编译结果
一个完整的p2p native例子可以串起整个WebRTC的处理流程,为了方便多媒体模块的管理和使用,WebRTC抽象出了MediaStream、 Tack、 channel、 engine、 transport等概念。交互式实时音视频会议存在上行和下行数据的概念,因而从硬件上存在source和sink两个方向,source是生成音频和视频内容的源,而sink则是消费音频(如播放接收到音视频),在传输上也存在sendstream和recvstream两个方向,在编解码上也存在send_codec和recv_codec两个方向,上下行统一使用voiceengine和videoengine管理,voiceengine和videoengine是多媒体管理的核心组件。本章简单阐述WebRTC使用到的一些概念和模块,熟悉这些模块的使用方法有助于理解后文整个P2P的串接过程。
1.1 视频会议中常见的服务端架构
在视频会议场景中,主要有三种类型的服务器架构,Mesh,MCU和SFU,WebRTC主推的是无中心的P2P架构,会为每一个端建立一个PeerConnection对象,这就是Mesh架构。
Mesh架构由于不需要多媒体(音视频)服务器,因而成本是最低的,安全性好,然而当人数较多时,可以看到P2P的链接数和带宽需求量变大,这在人数较少(如5人之内)是较为实用的,MCU架构需要服务器进行视频的解码、转码、混合和编码,但是上述视频的处理是比较消耗服务器资源的,因而成本较高,且会引入通信延迟,但是由于连接数量少,带宽压力小,因而在参会人数在数十人的场景中使用到,SFU架构和MCU架构一样都需要中心节点服务器,不同的是改服务器只负责转发,不负责视频处理,这在上百人场景中会用到该架构。
1.2 WebRTC 网络协议栈
Mesh架构下,需要进行透传以便通信双方能够正常进行,这就使用到的STURN和TURN以及ICE技术。WebRTC的信令传输可以慢些但需要可靠,而流媒体则实时性优,可以存在丢包、错包;这就意味着需要两套网络传输协议,一套是基于TCP的可靠传输协议用于信令等传输,一套是基于UDP的TRP协议用于实时多媒体数据的传输。其协议栈如下图所示:
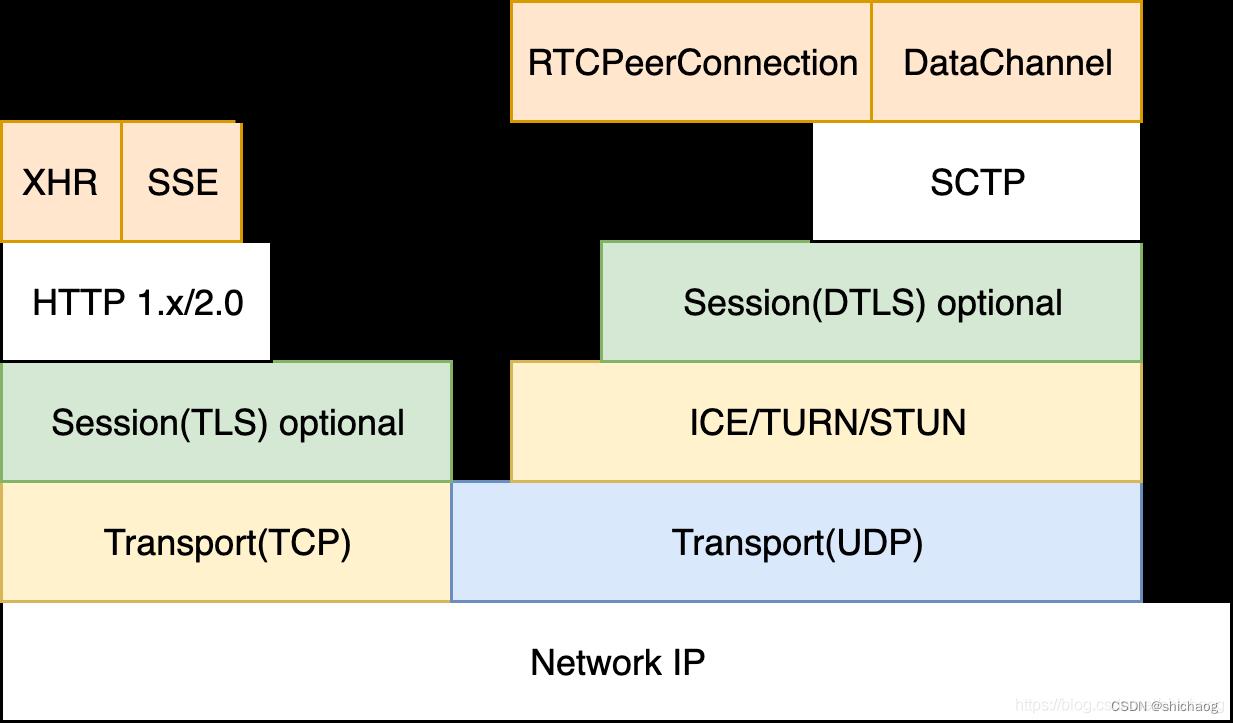
图1-2 WebRTC网络技术栈
STUN(Session Traversal Utilities for NAT)(RFC5389),用于获取设备的外网地址;
TURN(Traversal Using Relays around NAT)(RFC 5766),在P2P通信失败后用于中继;
ICE(Interactive Connectivity Establishment)协议(RFC 5245),整合了TURN和STUN。
这三个协议是基于UDP协议建立和维持P2P连接的必要网络组件;DTLS(Datagram Transport Protocol)用于P2P双方数据安全传输。
信令服务器:负责端到端的连接,如SDP,candidate等;
因为由于IPv4地址数量不够用和安全的问题,开会的双方基本都在防火墙和NAT之后,通过运营商接入公网,当在家时手机、电脑、网络电视通过电信路由器上网时,路由器分配给我们的地址就是“192.168.XXX.XXX”,但是在公网上我们的数据头地址被转换成电信服务商提供的地址了,如果双发希望直接通信而不需要公共服务器中转(加大了延迟和丢包的不确定性)数据包,这时需要NAT穿透技术,STUN和TURN就是这种透传协议,ICE是一套整合了这两个协议的框架。
1.3 WebRTC 源码目录结构
WebRTC目录结构如下图所示:

图1-3 WebRTC源码目录结构
各个目录的功能如下:
api目录:是对WebRTC功能件的封装,以更方便应用层调用,这里封装的内容包括audio、video、数据通道以及RTP传输,并在create_peerconnection_factory.h文件中定义了P2P通信的核心类PeerConnectionFactoryInterface;
audio目录:这里的audio层是用于发送和接收音频数据流的网络层,真实硬件的采集播放放在adm(audio device module),增强处理放在apm(audio processing module)里,adm和apm并不在这一目录下;
base目录:提供了一些依赖OS的基础函数,比如内存管理等;
build相关目录:使用与编译WebRTC的,在编译小节中会有编译说明;
call目录:从字面可以知道是用于通信用的,主要是RTP和RTCP相关协议的封装一遍WebRTC使用;
common_audio和common_video目录:音视频的各种算法都可能用到的,比如fir滤波,环形缓冲区,窗函数等;
examples:P2P等各个平台各种例子所在的目录;
media:是对video和audio增强和编解码的封装层,即video engine和audio engine。
modules:音视频具体功能实现所在的目录,如音视频编解码实现;音频混音、处理以及设备管理,视频采集播放以及数据发送和占用带宽估计等;
pc(peer connection)目录:P2P连接实现的核心目录;
sdk目录:android平台应用层Java和MAC平台应用层Object C访问natvie层的桥接层;
1.4 client侧技术栈
Android IOS Windows MAC Linux 浏览器。
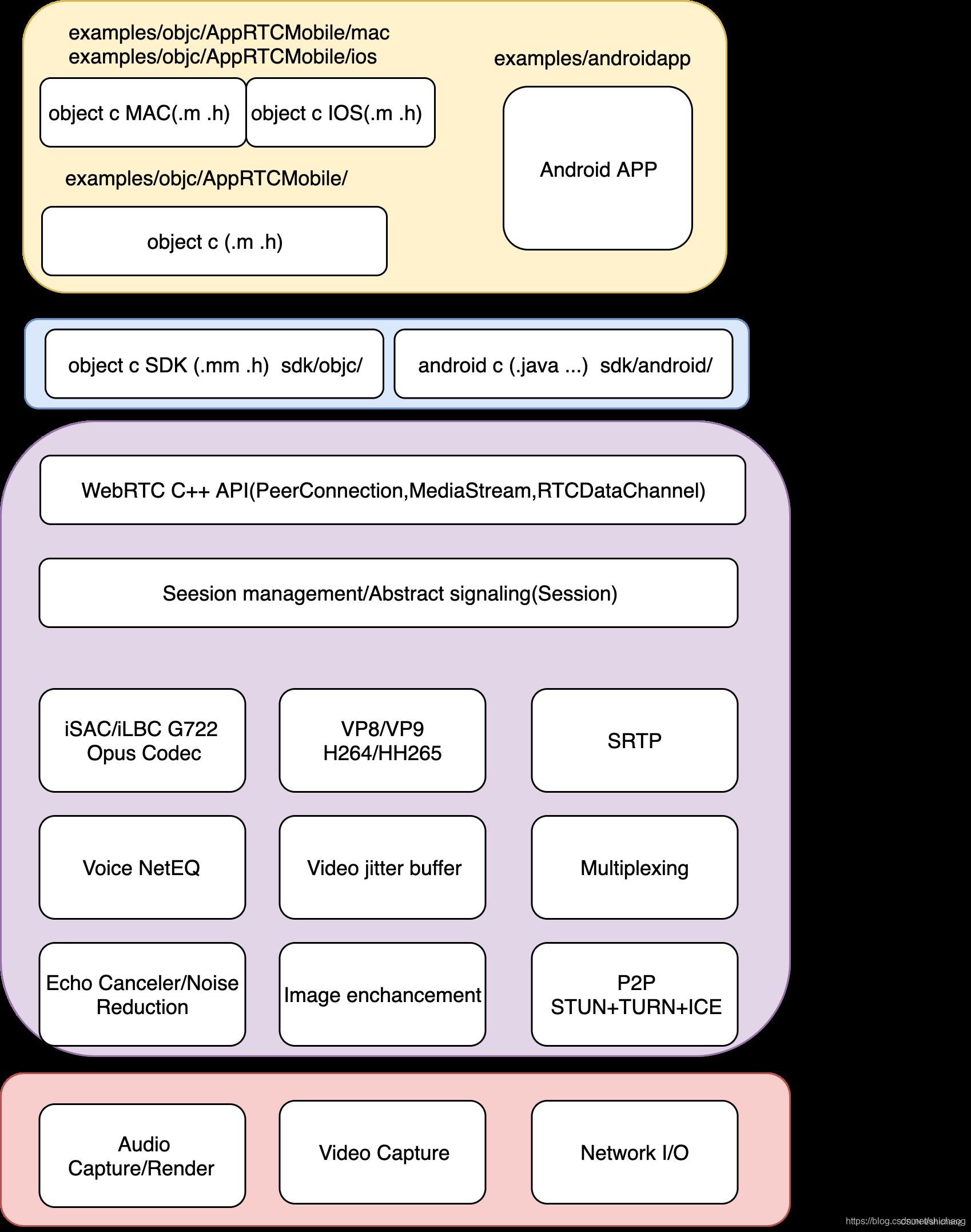
图1-4 WebRTC 客户端技术栈
由于不同平台使用了不同的UI库和编程语言,他们的实现差异很大,但是不同的平台都会支持c/c++,所以为了适配不同的平台,WebRTC提供了SDK层,Linux平台基于使用GTK的c++,MAC和IOS平台基于使用cocoa库的Object c,android平台基于JAVA,为了让这些平台都能够调用c/c++核心函数,WebRTC提供了android和object c的封装层,这称为SDK层,android中使用了JNI机制使得UI层的JAVA程序和实现核心功能的c/c++程序可以互相调用,类似的object c使用了.mm扩展程序是得UI的.m程序可以和c/c++互相调用。由于访问各个平台都提供了C API(为了效率),所有已在音视频以及网络API都可以直接通过包含不同操作系统的头文件来实现跨平台差异化编译。
1.5 WebRTC native编译以及debug
初次上手时,在编译webrtc的使用除了将is_debug=true之外,还可将rtc_base/logging.cc文件下面代码段中的LS_INFO改为LS_VERBOSE,这样可以打出更详细的信息以便于对执行过程的理解。
//rtc_base/logging.cc
/ By default, release builds don't log, debug builds at info level
#if !defined(NDEBUG)
constexpr LoggingSeverity kDefaultLoggingSeverity = LS_INFO;
#else
constexpr LoggingSeverity kDefaultLoggingSeverity = LS_NONE;
#endif
// Note: `g_min_sev` and `g_dbg_sev` can be changed while running.
LoggingSeverity g_min_sev = kDefaultLoggingSeverity;
LoggingSeverity g_dbg_sev = kDefaultLoggingSeverity;
将LS_INFO改为LS_VERBOSE以便打出更为详细的日志信息。这样可以看到如下log信息
1 gsc@gsc240:~/webrtc/src$ ./out/Default/peerconnection_client
1 (field_trial.cc:159): Setting field trial string:
2 (main_wnd.cc:255): SwitchToConnectUI
3 (peer_connection_client.cc:287): Headers received
4 (peer_connection_client.cc:462): OnClose 5 (conductor.cc:281): OnPeerConnected 6 (conductor.cc:267): OnSignedIn 7 (main_wnd.cc:303): SwitchToPeerList 8 (conductor.cc:516): SEND_MESSAGE_TO_PEER 9 (create_peerconnection_factory.cc:72): CreatePeerConnectionFactory 10 (audio_processing_builder_impl.cc:29): Create 11 (audio_processing_impl.cc:295): Injected APM submodules:
12 Echo control factory: 0
13 Echo detector: 0 14 Capture analyzer: 0
15 Capture post processor: 0 16 Render pre processor: 0
17 (audio_processing_impl.cc:304): Denormal disabler: supported 18 (webrtc_voice_engine.cc:311): WebRtcVoiceEngine::WebRtcVoiceEngine
19 (webrtc_video_engine.cc:583): WebRtcVideoEngine::WebRtcVideoEngine() 20 (webrtc_voice_engine.cc:333): WebRtcVoiceEngine::Init
21 (webrtc_voice_engine.cc:342): Supported send codecs in order of preference:
22 (webrtc_voice_engine.cc:345): opus/48000/2 minptime=10 useinbandfec=1 (111)
23 (webrtc_voice_engine.cc:345): red/48000/2 =111/111 (63)
24 (webrtc_voice_engine.cc:345): ISAC/16000/1 (103)
25 (webrtc_voice_engine.cc:345): ISAC/32000/1 (104) 26 (webrtc_voice_engine.cc:345): G722/8000/1 (9) 27 (webrtc_voice_engine.cc:345): ILBC/8000/1 (102)
28 (webrtc_voice_engine.cc:345): PCMU/8000/1 (0)
29 (webrtc_voice_engine.cc:345): PCMA/8000/1 (8)
30 (webrtc_voice_engine.cc:345): CN/32000/1 (106)
31 (webrtc_voice_engine.cc:345): CN/16000/1 (105)
如果想在添加额外的日志,则可以使用如下类似的方法:
RTC_LOG(INFO) << __FUNCTION__ << "AudioDeviceBuffer::~dtor";
更多的log API可以参考third_party/webrtc/rtc_base/logging.h文件。
桌面应用程序使用如下方法下载代码:
mkdir webrtc-checkout
cd webrtc-checkout
fetch --nohooks webrtc
gclient sync
其编译使用Ninja,先创建Ninja工程文件,默认工程是debug版本,这在学习的时候建议打开。
gn gen out/Default
如果想看配置参数,可以使用如下命令:
gn args out/Default --list > log_args
编译使用如下命令:
ninja -C out/Default
这样就得到了图1-1中的测试二进制程序以及Peerconnection例子的server端和client端程序,通过单元测试用例和peerconnection例子可以加深WebRTC的理解。
1.6 APM模块
APM(Audio Processing Module)提供了音频处理模块的集合,这里音频处理算法针对的是实时通信场景。APM逐帧对两路音频帧处理,其中一路的音频(near-end,采集信号)将会调用所有音频算法进行处理,这通过调用ProcessStream()实现,而另一路音(far-end,接收到的信号)频调用ProcessReverseStream()处理。
APM模块只接受10ms帧长的PCM数据,其帧长可以通过API AudioProcessing::GetFrameSize()获取,对于int16格式的多通道(channel )输入API数据是交叉存放的,而浮点格式的音频输入则采用非交叉存放。
本篇不会深入算法原理以及相关实现的技巧,对此感兴趣读者可以参考《实时语音处理实践指南》一书。
APM模块使用的方法如下代码,后文native 层peerconnection例子采用的就是这里的方法构建音频处理模块的。
AudioProcessing* apm = AudioProcessingBuilder().Create();
AudioProcessing::Config config;
config.echo_canceller.enabled = true;
config.echo_canceller.mobile_mode = false;
config.gain_controller1.enabled = true;
config.gain_controller1.mode =
AudioProcessing::Config::GainController1::kAdaptiveAnalog;
config.gain_controller1.analog_level_minimum = 0;
config.gain_controller1.analog_level_maximum = 255;
config.gain_controller2.enabled = true;
config.high_pass_filter.enabled = true;
apm->ApplyConfig(config)
apm->noise_reduction()->set_level(kHighSuppression);
apm->noise_reduction()->Enable(true);
//处理远端信号
apm->ProcessReverseStream(render_frame);
//实时通信需要设置音频增益、延迟等参数,采集到的数据调用ProcessStream处理
apm->set_stream_delay_ms(delay_ms);
apm->set_stream_analog_level(analog_level);
apm->ProcessStream(capture_frame);
AudioProcessing是一个接口类,这个接口类包含了Config字段和通用音频处理方法组成的接口类。
class RTC_EXPORT AudioProcessing : public rtc::RefCountInterface
public:
// Accepts and produces a ~10 ms frame of interleaved 16 bit integer audio as
// specified in `input_config` and `output_config`. `src` and `dest` may use
// the same memory, if desired.
virtual int ProcessStream(const int16_t* const src,
const StreamConfig& input_config,
const StreamConfig& output_config,
int16_t* const dest) = 0;
// Accepts deinterleaved float audio with the range [-1, 1]. Each element of
// `src` points to a channel buffer, arranged according to `input_stream`. At
// output, the channels will be arranged according to `output_stream` in
// `dest`.
//
// The output must have one channel or as many channels as the input. `src`
// and `dest` may use the same memory, if desired.
virtual int ProcessStream(const float* const* src,
const StreamConfig& input_config,
const StreamConfig& output_config,
float* const* dest) = 0;
// Accepts and produces a ~10 ms frame of interleaved 16 bit integer audio for
// the reverse direction audio stream as specified in `input_config` and
// `output_config`. `src` and `dest` may use the same memory, if desired.
virtual int ProcessReverseStream(const int16_t* const src,
const StreamConfig& input_config,
const StreamConfig& output_config,
int16_t* const dest) = 0;
// Accepts deinterleaved float audio with the range [-1, 1]. Each element of
// `data` points to a channel buffer, arranged according to `reverse_config`.
virtual int ProcessReverseStream(const float* const* src,
const StreamConfig& input_config,
const StreamConfig& output_config,
float* const* dest) = 0;
// Accepts deinterleaved float audio with the range [-1, 1]. Each element
// of `data` points to a channel buffer, arranged according to
// `reverse_config`.
virtual int AnalyzeReverseStream(const float* const* data,
const StreamConfig& reverse_config) = 0;
virtual int set_stream_delay_ms(int delay) = 0;
virtual int stream_delay_ms() const = 0;
static int GetFrameSize(int sample_rate_hz) return sample_rate_hz / 100;
;
APM模块有很多处理算法,包括AEC、NS、AGC等,这里以AEC mobile版(PC版本用aec3文件夹下的)本为例,说明其实如何嵌入到APM模块的,首先AEC mobile算法的核心实现是用c代码实现的,位于modules/audio_processing/aecm/文件夹下。有如下几个文件:
aecm_core.h aecm_core_mips.cc aecm_defines.h echo_control_mobile.h
aecm_core.cc aecm_core_c.cc aecm_core_neon.cc echo_control_mobile.cc
在EchoControlMobileImpl类init时,会创建canceller对象:
class EchoControlMobileImpl::Canceller
public:
Canceller()
state_ = WebRtcAecm_Create();
RTC_CHECK(state_);
~Canceller()
RTC_DCHECK(state_);
WebRtcAecm_Free(state_);
Canceller(const Canceller&) = delete;
Canceller& operator=(const Canceller&) = delete;
void* state()
RTC_DCHECK(state_);
return state_;
void Initialize(int sample_rate_hz)
RTC_DCHECK(state_);
//这里调用echo_control_mobile.cc文件里的方法,这里的state_定义为void*类型,而在.c算法实现层,
//则是AecMobile*类型的,在具体使用的地方强制转换下类型即可,这样也实现了隔离。
//int32_t WebRtcAecm_GetBufferFarendError(void* aecmInst,
// const int16_t* farend,
// size_t nrOfSamples)
// AecMobile* aecm = static_cast<AecMobile*>(aecmInst);
// ...
//
int error = WebRtcAecm_Init(state_, sample_rate_hz);
RTC_DCHECK_EQ(AudioProcessing::kNoError, error);
private:
void* state_;
;
void EchoControlMobileImpl::Initialize(int sample_rate_hz,
size_t num_reverse_channels,
size_t num_output_channels)
low_pass_reference_.resize(num_output_channels);
for (auto& reference : low_pass_reference_)
reference.fill(0);
stream_properties_.reset(new StreamProperties(
sample_rate_hz, num_reverse_channels, num_output_channels));
// AECM only supports 16 kHz or lower sample rates.
RTC_DCHECK_LE(stream_properties_->sample_rate_hz,
AudioProcessing::kSampleRate16kHz);
cancellers_.resize(
NumCancellersRequired(stream_properties_->num_output_channels,
stream_properties_->num_reverse_channels));
for (auto& canceller : cancellers_)
if (!canceller)
//调用上面的Canceller函数创建canceller对象,并初始化该对象
canceller.reset(new Canceller());
canceller->Initialize(sample_rate_hz);
Configure();
class EchoControlMobileImpl::Canceller
public:
Canceller()
state_ = WebRtcAecm_Create();
RTC_CHECK(state_);
~Canceller()
RTC_DCHECK(state_);
WebRtcAecm_Free(state_);
Canceller(const Canceller&) = delete;
Canceller& operator=(const Canceller&) = delete;
void* state()
RTC_DCHECK(state_);
return state_;
void Initialize(int sample_rate_hz)
RTC_DCHECK(state_);
//这里调用echo_control_mobile.cc文件里的方法,这里的state_定义为void*类型,而在.c算法实现层,
//则是AecMobile*类型的,在具体使用的地方强制转换下类型即可,这样也实现了隔离。
//int32_t WebRtcAecm_GetBufferFarendError(void* aecmInst,
// const int16_t* farend,
// size_t nrOfSamples)
// AecMobile* aecm = static_cast<AecMobile*>(aecmInst);
// ...
//
int error = WebRtcAecm_Init(state_, sample_rate_hz);
RTC_DCHECK_EQ(AudioProcessing::kNoError, error);
private:
void* state_;
;
void EchoControlMobileImpl::Initialize(int sample_rate_hz,
size_t num_reverse_channels,
size_t num_output_channels)
low_pass_reference_.resize(num_output_channels);
for (auto& reference : low_pass_reference_)
reference.fill(0);
stream_properties_.reset(new StreamProperties(
sample_rate_hz, num_reverse_channels, num_output_channels));
// AECM only supports 16 kHz or lower sample rates.
RTC_DCHECK_LE(stream_properties_->sample_rate_hz,
AudioProcessing::kSampleRate16kHz);
cancellers_.resize(
NumCancellersRequired(stream_properties_->num_output_channels,
stream_properties_->num_reverse_channels));
for (auto& canceller : cancellers_)
if (!canceller)
//调用上面的Canceller函数创建canceller对象,并初始化该对象
canceller.reset(new Canceller());
canceller->Initialize(sample_rate_hz);
Configure();
其它的算法和其套路类似,这样在APM类里定义EchoControlMobileImpl成员变量,这样可以使用成员变量调用具体算法了。AudioProcessingImpl类的submodules_成员就有std::unique_prt<EchoControlMobileImpl> echo_control_mobile这一成员定义。
在capture端会调用config配置的算法完成相应处理。
int AudioProcessingImpl::ProcessStream(const int16_t* const src,
const StreamConfig& input_config,
const StreamConfig& output_config,
int16_t* const dest)
TRACE_EVENT0("webrtc", "AudioProcessing::ProcessStream_AudioFrame");
RETURN_ON_ERR(MaybeInitializeCapture(input_config, output_config));
MutexLock lock_capture(&mutex_capture_);
DenormalDisabler denormal_disabler(use_denormal_disabler_);
capture_.capture_audio->CopyFrom(src, input_config);
if (capture_.capture_fullband_audio)
capture_.capture_fullband_audio->CopyFrom(src, input_config);
//ProcessCaptureStreamLocked调用算法的核心处理函数
RETURN_ON_ERR(ProcessCaptureStreamLocked());
if (submodule_states_.CaptureMultiBandProcessingPresent() ||
submodule_states_.CaptureFullBandProcessingActive())
if (capture_.capture_fullband_audio)
capture_.capture_fullband_audio->CopyTo(output_config, dest);
else
capture_.capture_audio->CopyTo(output_config, dest);
return kNoError;
int AudioProcessingImpl::ProcessCaptureStreamLocked() 函数有三百多行,精简了和算法调用无关的函数,其主体调用流程如下:
int AudioProcessingImpl::ProcessCaptureStreamLocked()
//先对信号进行
submodules_.high_pass_filter->Process(capture_buffer,
/*use_split_band_data=*/false);
if (submodules_.noise_suppressor)
submodules_.noise_suppressor->Process(capture_buffer);
//调用mobile 版本AEC算法
RETURN_ON_ERR(submodules_.echo_control_mobile->ProcessCaptureAudio(
capture_buffer, stream_delay_ms()));
if (submodules_.agc_manager)
submodules_.agc_manager->Process(capture_buffer);
if (submodules_.echo_detector)
submodules_.echo_detector->AnalyzeCaptureAudio(
rtc::ArrayView<const float>(capture_buffer->channels()[0],
capture_buffer->num_frames()));
if (!!submodules_.voice_activity_detector)
voice_probability = submodules_.voice_activity_detector->Analyze(
AudioFrameView<const float>(capture_buffer->channels(),
capture_buffer->num_channels(),
capture_buffer->num_frames()));
由上可以看到算法是如何调用的,接下来还剩一个问题,AudioProcessingImpl这个对象的实例上层是如何定义的?任何想使用该类的文件只需要include该头文件#include "modules/audio_processing/include/audio_processing.h"在其类中再定义 rtc::scoped_refptr<AudioProcessing> audio_processing;这样在就可以开发编译代码了,再链接的时候提供该库即可。通常只在WebRtcVoiceEngine中使用,也可以在tranport stream层或者channel层使用,通常还会和audio device module一同存在,因为audio device module采集数据,然后直接调用APM处理,这样的好处是采集是一个线程,每次采集约10ms的数据量,算法也是按照10ms帧长去处理的,这样处理起来紧凑且方便。
关于audio模块之间的组合以及调用见webrtc_voice_engine.h/webrtc_voice_engine.cc
1.7 ADM模块
audio device module,采集和播放声音都需要具体的硬件支持,Linux、Android、iOS、windows、mac都有不同硬件驱动和系统API可供调用,为了屏蔽不同操作系统提供的API差异,类似于ACM模块给编码器提供统一的接口、APM模块给音频处理算法提供统一的接口一样,ADM模块也提供了AudioDeviceModule这一接口类,该类也是通用的音频设备管理模块,该模块定义了音频设备的采集、播放以及管理(选择、枚举、启停等)的通用API,主其主要和具体的平台打交道,其支持的各个平台Audio如下:
```c++
enum AudioLayer
kPlatformDefaultAudio = 0,
kWindowsCoreAudio,
kWindowsCoreAudio2,
kLinuxAlsaAudio,
kLinuxPulseAudio,
kAndroidJavaAudio,
kAndroidOpenSLESAudio,
kAndroidJavaInputAndOpenSLESOutputAudio,
kAndroidAAudioAudio,
kAndroidJavaInputAndAAudioOutputAudio,
kDummyAudio,
;
当 AudioDeviceModule 采集到音频数据后通过回调RecordedDataIsAvailable通知该传输控制层新的数据到来,新到来的数据首先经过RemixAndResample方法进行预处理,这不是APM的处理而是将采集的音频和输出要求的格式对数据按最小计算原则混音和下采样,然后调用APM模块 webrtc::AudioProcessing 的音频数据处理,音频数据处理包括降噪、自动增益控制和回声消除等。数据处理完之后通过webrtc::AudioSender/webrtc::AudioSendStream 调用音频数据编码,如OPUS、AAC 等,RTP 打包和发送控制,打包完之后通过回调回webrtc::AudioTransport 层,webrtc::Transport 再把 webrtc::AudioSender/webrtc::AudioSendStream 得到的 RTP 和 RTCP 包发送给后面的网络接口模块块,cricket::MediaChannel::NetworkInterface 用于实现真正地把 RTP 和 RTCP 包通过底层的网络接口和协议发送,如 UDP 等。
描述设备的接口类实现定义于AudioDeviceModuleImpl,这里使用到了关键成员变量是AudioDeviceBuffer audio_device_buffer_;和std::unique_ptr audio_device_;,其中audio_device_是和平台相关的,而audio_device_buffer_则维护了音频设备的缓冲区,而audio_device_则代表了平台硬件设备,采集、播放、音量控制等都通过这个对象的接口实现。即AudioDeviceModuleImpl对象调用相应的采集、播放、音量控制等方法时,就会调用audio_device_对象里的方法完成响应的动作。
class AudioDeviceModuleImpl:public AudioDeviceModule
public:
enum PlatformType
kPlatformNotSupported = 0,
kPlatformWin32 = 1,
kPlatformWinCe = 2,
kPlatformLinux = 3,
kPlatformMac = 4,
kPlatformAndroid = 5以上是关于WebRTC 的音频网络对抗概述的主要内容,如果未能解决你的问题,请参考以下文章