[人工智能-深度学习-58]:生成对抗网络GNN - 概述与常见应用
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-58]:生成对抗网络GNN - 概述与常见应用相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121881726
目录
第1章 什么是GAN
1.1 GAN概述
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。

模型通过框架中(至少)两个模块:生成模型G(Generative Model)和判别模型D(Discriminative Model)的互相博弈学习产生相当好的输出。因此被称为“对抗”网络,对抗是指“生成模型”与“判别模型”相互对抗,实际上他们不仅仅是对抗,而是相互合作,相互演进,相互促进。
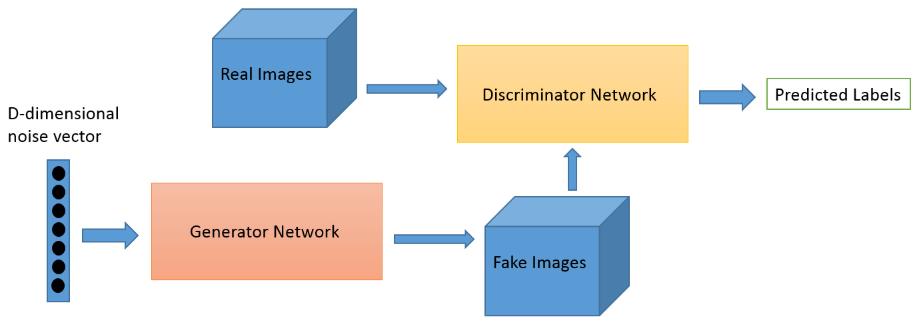
原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。至于G和D网络本身采用什么样的深度神经网络,是RNN或CNN或全连接,其实没有限制,实际上都是可以的。

GAN的核心不在于G和D, 其核心在于G和D如何相互协作,如何进行训练。训练的原理是GAN网络的最核心的地方,需要深入理解的地方。
没有合理训练的GAN网络,其输出输出是不理想。
1.2 发展历史
Ian J. Goodfellow等人于2014年10月在Generative Adversarial Networks中提出了一个通过对抗过程估计生成模型的新框架。
框架中同时训练两个独立又相互关联的模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。
G的训练程序是将D错误的概率最大化。这个框架对应一个最大值集下限的双方对抗游戏。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔可夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估证明了本框架的潜力。
1.3 GAN网络的竞争对手
GANs不是唯一属于生成模型类的模型,其他深度学习模型(如变分自编码器和自回归模型)也是生成模型的好示例,用于模拟数据的分布。
这些生成算法具有不同的基本工作,对于GANs而言,训练过程就像生成器和判别器之间的竞争,而变分自编码器允许我们在概率图形模型的框架中形成生成训练样本的问题,我们最大化了数据的对数可能性的最低范围。在PixelRNN的自回归模型的情况下,对网络进行训练以模拟每个单独像素的条件分布到前一像素的条件分布进行建模。
1.4 GAN网络的种类
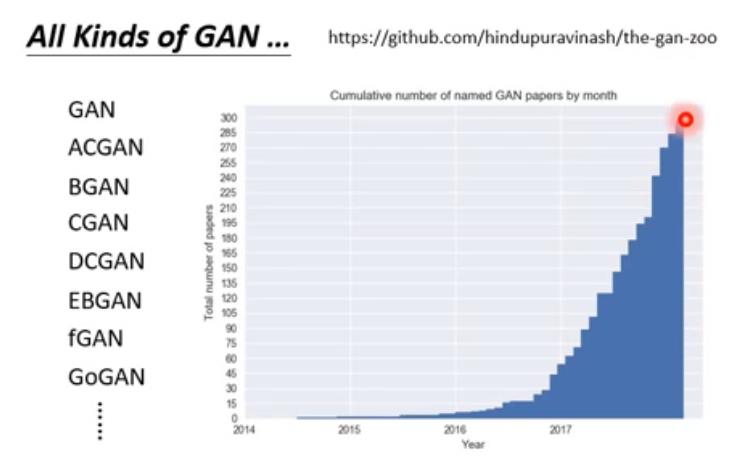
由于GAN网络本身对G和D网络做明确的指定,因此衍生出上百种不同的GAN网络,用于不同的应用。
如下的链接是GAN网络的大观园, 有几百种GAN网络的变体。
https://github.com/hindupuravinash/the-gan-zoo.
-
GAN
实现最原始的,基于多层感知器构成的生成器和判别器,组成的生成对抗网络模型(Generative Adversarial)。
参考论文:《Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/gan/gan.py
- AC-GAN
实现辅助分类-生成对抗网络(Auxiliary Classifier Generative Adversarial Network)。
参考论文:《Conditional Image Synthesis With Auxiliary Classifier GANs》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/acgan/acgan.py
- BiGAN
实现双向生成对抗网络(Bidirectional Generative Adversarial Network)。
参考论文:《Adversarial Feature Learning》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/bigan/bigan.py
- BGAN
实现边界搜索生成对抗网络(Boundary-Seeking Generative Adversarial Networks)。
参考论文:《Boundary-Seeking Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/bgan/bgan.py
- CC-GAN
实现基于上下文的半监督生成对抗网络(Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks)。
参考论文:《Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/ccgan/ccgan.py
- CoGAN
实现耦合生成对抗网络(Coupled generative adversarial networks)。
参考论文:《Coupled Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/cogan/cogan.py
- CycleGAN
实现基于循环一致性对抗网络(Cycle-Consistent Adversarial Networks)的不成对的Image-to-Image 翻译。
参考论文:《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/cyclegan/cyclegan.py
- DCGAN
实现深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Network)。
参考论文:《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/dcgan/dcgan.py
- DualGAN
实现对偶生成对抗网络(DualGAN),基于无监督的对偶学习进行Image-to-Image翻译。
参考论文:《DualGAN: Unsupervised Dual Learning for Image-to-Image Translation》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/dualgan/dualgan.py
- InfoGAN
实现的信息最大化的生成对抗网络(InfoGAN),基于信息最大化生成对抗网络的可解释表示学习。
参考论文:《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/infogan/infogan.py
- LSGAN
实现最小均方误差的生成对抗网络(Least Squares Generative Adversarial Networks)。
参考论文:《Least Squares Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/lsgan/lsgan.py
- SGAN
实现半监督生成对抗网络(Semi-Supervised Generative Adversarial Network)。
参考论文:《Semi-Supervised Learning with Generative Adversarial Networks》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/sgan/sgan.py
- WGAN
实现 Wasserstein GAN。
参考论文:《Wasserstein GAN》
代码地址:https://github.com/eriklindernoren/Keras-GAN/blob/master/wgan/wgan.py
第2章 GAN网络的常见应用
2.1 主要应用概述(图片、文本生成)
生成的图片或文本与训练的图片或文本具有相同的内在特征!!!!
因此,一种地地道道的高仿真!!!
因此,可以应用在任意高仿真的场合,如图像、文字、音乐、视频等等。
- 图像数据集生成
- 生成人脸照片
- 生成真实化照片
- 生成卡通照片
- 图像翻译
- 文本到图像翻译(Text2Image Translation)
- 图像语义道照片翻译(Semantic-Image2Photo Translation)
- 人脸正面视图生成(Face Frontal View Generation)
- 新姿态生成(Generate New Human Poses) =》具备与原姿态相同的特征
- 照片到卡通漫画翻译
- 照片编辑
- 人脸年龄化
- 照片融合(Photo Blending)
- 超像素(Super Resolution)
- 照片修复(Photo Inpainting)
- 视频预测(Video Prediction)
- 三维对象生成(3D Object Generation)
2.2 图像样本数据的生成或数据增强
最明显的应用是:从已有的数据集样本中生成新样本,以增强我们的数据集,以帮助后续的训练模型。
我们如何检查这种增强是否真的有帮助呢?
那么,有两个主要策略:
(1)我们可以在生成的“假”数据上训练我们的模型,并检查它在真实样本上的表现。
(2)相反:我们在实际数据上训练我们的模型来做一些分类任务,并且只有在检查它对生成的数据的执行情况之后(GAN粉丝可以在这里识别初始分数)。
如果它在两种情况下都能正常工作 - 您可以随意将生成模型中的样本添加到您的实际数据中并再次重新训练 - 您应该期望获得性能。要使此方法更加强大和灵活。
NVIDIA展示了这种方法的惊人实例:他们使用GAN来增加具有不同疾病的医学脑CT图像的数据集,并且表明仅使用经典数据增强的分类性能产生78.6%的灵敏度和88.4%的特异性。通过添加合成数据增加,结果增加到85.7%的灵敏度和92.4%的特异性。
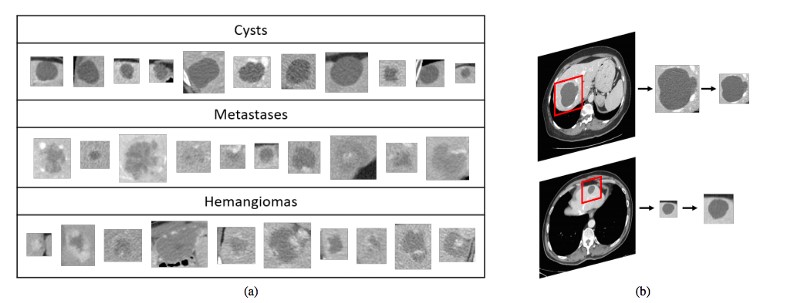
之所以,这种生成的图片是有效的,是因为GAN网络的生成图片,与原始的实际样本的图片,具备相同的内在特征,虽然外形上与原图片不一定完全相同。


2.3 隐私保护
许多公司的数据可能是秘密的(如赚钱的财务数据),机密或敏感(包含患者诊断的医疗数据)。但有时我们需要与顾问或研究人员等第三方分享。
如果我们只想分享关于我们的数据的一般概念,包括最重要的模式(内在特征),而忽略对象的细节和形状,我们可以像前一段一样直接使用生成模型来抽样我们的数据示例以与其他人分享。这样我们就不会分享任何确切的机密数据,只是看起来完全像它的东西。
更困难的情况是我们想要秘密共享数据。当然,我们有不同的加密方案,如同态加密,但它们有已知的缺点,例如在10GB代码中隐藏1MB信息。2016年,谷歌开辟了一条关于使用GAN竞争框架加密问题的新研究路径,其中两个网络必须竞争创建代码并破解它:
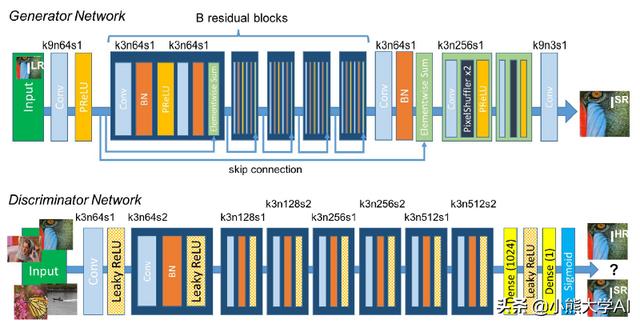
2.4 单幅图像超分辨率合成
我们经常面临低分辨率图像的问题,因为它们不清楚,GANs帮助我们从单个低分辨率图像创建高分辨率图像。
对于这个问题,使用了一个名为SRGAN的GAN ,我们可以看到SRGAN如何能够在下图中创建最高分辨率的图像,如下图所示:

尽管存在许多方法,但是当图像超分辨率时恢复更精细的纹理细节的问题仍然存在。
SRGAN是第一个能够为4倍放大因子推断照片真实感自然图像的框架。它使用感知损失函数,其包括对抗性损失和内容损失。对抗性损失使用经过训练以区分超分辨图像和原始照片真实图像的判别器网络将解决方案推送到自然图像集。
2.5 文本到图像合成
从文本描述中合成高质量的图像是计算机视觉中的挑战性问题。
由现有的文本到图像方法生成的样本可以粗略地反映给定描述的含义,但是它们不能包含必要的细节和生动的对象部分。
这个应用程序的最佳网络是StackGAN或堆叠生成对抗网络,它根据文本描述生成256x256的逼真照片般的图像。

Pix2pix是一种条件GAN。对于该任务,生成器G的目标是将语义标签映射转换为具有真实感的图像,而判别器D旨在将真实图像与翻译的图像区分开。pix2pix方法采用U-Net作为生成器。
以及patch-based的完全卷积网络作为判别器。判别器的输入是语义标签映射和对应图像的通道顺序连接。我们可以通过使用粗到精生成器,multi-scale判别器架构和强大的对抗性学习目标函数来提高真实感和分辨率。
2.6 视频生成
视频生成是图像生成的延伸,这是一个巨大的挑战,因为我们必须在生成过程中考虑视频的时间维度,因为理解对象运动和场景动态是视频生成核心问题,这对视频生成提出了很大的挑战。
由于记忆和训练稳定性的限制,随着视频分辨率/时长的增加,生成变得越来越具有挑战性。视频生成过程可以通过两种方式进行,一种是提供文本作为创建相应视频的特性,另一种是提供视频并生成视频的下一帧。为了实现生成器具有时空卷积结构的生成对抗网络,它将场景的前景从背景中分离出来。
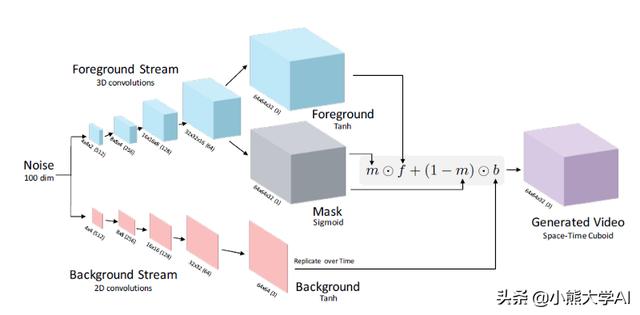
2.7 风格迁移 (图片或视频)

把棕色马的特征迁移到斑马身上,他们具备相同的“马”的特征。
2.8 老照片或老视频的修复

可以把黑白的照片,修复成彩色照片,而保留他们的轮廓特征。
生成新的彩色特征。
2.9 动作的迁移

把一章图片的动作特征迁移到另一章图片上。
2.10 超高辨率的增强

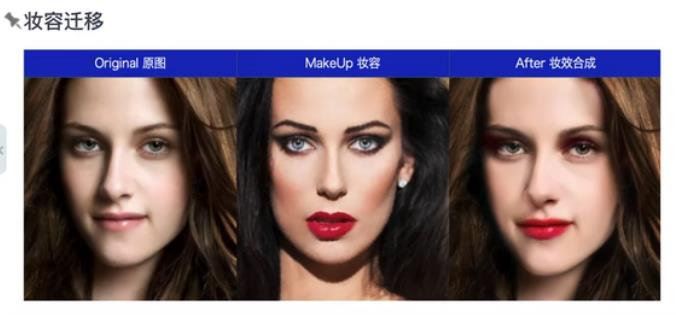
2.11 把一个人的妆容迁移到另一个人像图片上
2.12 人脸的动漫化

2.13 人脸卡通化

2.14 照片的动漫化

2.15 唇形同步

参考:
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121881726
以上是关于[人工智能-深度学习-58]:生成对抗网络GNN - 概述与常见应用的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-60]:生成对抗网络GAN - 结构化学习Structured Learning
[人工智能-深度学习-61]:生成对抗网络GAN - 图像融合的基本原理与案例
深度学习与图神经网络核心技术实践应用高级研修班-Day3对抗生成网络(Generative Adversarial Networks)