为什么对抗生成网络(GAN)被誉为过去20年来深度学习中最酷的想法?
Posted 人邮异步社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么对抗生成网络(GAN)被誉为过去20年来深度学习中最酷的想法?相关的知识,希望对你有一定的参考价值。
自发明以来,GAN一直被学术界和工业界的专家们誉为“深度学习中最重要的创新之一”。Facebook的人工智能研究主管Yann LeCun甚至表示,GAN及其变体是“过去20年来深度学习中最酷的想法”。
这种兴奋是合情合理的。机器学习领域的其他进展可能在科研人员中人尽皆知,但对于门外汉来说,可能疑惑多于兴奋,GAN激起了从研究人员到大众的极大兴趣——包括《纽约时报》、BBC、《科学美国人》以及许多其他知名媒体机构,甚至可能就是GAN的某项成果驱使你来购买这本书的呢。(对吧?)
最值得关注的可能是GAN创作超现实主义意象的能力。图1.4所示的人脸都不是真人的,都是假的,这展示了 GAN 合成足以和真实照片以假乱真图像的能力。这些人脸是用渐进式增长生成对抗网络生成的。

(来源:Progressive Growing of GAN for Improved Quality, Stability and Variation,by Tero Karras et al., 2017.)图1.4 这些逼真但虚假的脸是由在高分辨率名人肖像照片集上训练过的渐进GAN生成的
GAN另一个引人瞩目的成就是图像到图像的转换(image-to-image translation)。与把句子从汉语翻译成西班牙语的方式类似,GAN可以将图像从一种风格转换为另一种风格。如图1.5所示,GAN可以把马的图像转换为斑马的图像,把一张照片变成莫奈的画作,而这几乎不需要任何监督,也不需要任何标签。使这一切成为可能GAN的变体是循环一致性生成对抗网络(CycleGAN)。
更实用些的GAN应用同样令人着迷。在线零售的巨头亚马逊(Amazon)尝试利用GAN提供时尚建议:通过分析无数的搭配,系统能学会生成符合给定的任意风格的新产品。 在医学研究中,GAN通过合成样本增强数据集,以提高诊断准确率。

(来源:Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks, by Jun-Yan Zhu et al., 2017.)图1.5 通过使用名为CycleGAN的GAN变体,可以将莫奈的画作变成照片,或将图片中的斑马变成马;反之亦然
GAN也被视为实现通用人工智能的重要基石。它是一种能够匹敌人类认知能力的人工系统,能获取几乎任何领域的专业知识——从走路所需的运动技能到语言表达技能,甚至于写诗所需的创作技能。
然而,拥有生成新数据和新图像的能力使得GAN有时也会很危险。关于假新闻的传播及其危险性已经是老生常谈,GAN生成可信假视频的能力也令人不安。在2018年一篇关于GAN的文章的结尾处——这篇文章的标题很贴切“如何成为一个人工智能”——《纽约时报》记者 Cade Metz和Keith Collins谈到了令人担忧的前景:GAN可能被用来制造和传播易使人轻信的错误信息,比如虚假的世界各国领导人发表声明的视频片段。《麻省理工学院科技评论》旧金山分社社长Martin Giles也表达了他的担忧,他在2018年发表的《GAN之父:赋予机器想象力的人》一文中提到,在技术娴熟的黑客手中,GAN可能会以前所未有的规模被用来探索和利用系统漏洞。这些忧虑促使我们讨论GAN的应用在道德伦理上的考量。
GAN可以为世界带来许多好处,但是任何技术创新都是一把双刃剑。对此,我们必须怀有一种哲学意识:“除掉”一种技术是不可能的,所以确保像你这样的人了解这项技术的迅速崛起及其巨大的潜力是很重要的。
什么是GAN
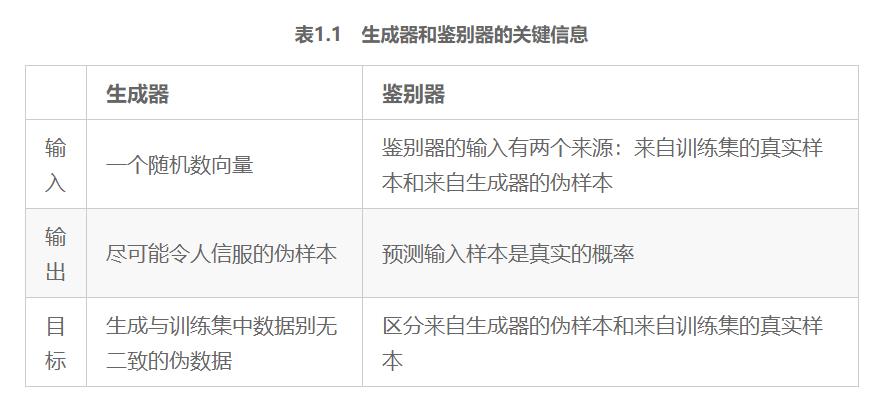
GAN是一类由两个同时训练的模型组成的机器学习技术:一个是生成器,训练其生成伪数据;另一个是鉴别器,训练其从真实数据中识别伪数据。
生成(generative)一词预示着模型的总目标——生成新数据。GAN通过学习生成的数据取决于所选择的训练集,例如,如果我们想用GAN合成一幅看起来像达•芬奇作品的画作,就得用达•芬奇的作品作为训练集。
对抗(adversarial)一词则是指构成GAN框架的两个动态博弈、竞争的模型:生成器和鉴别器。生成器的目标是生成与训练集中的真实数据无法区分的伪数据——在刚才的示例中,这就意味着能够创作出和达•芬奇画作一样的绘画作品。鉴别器的目标是能辨别出哪些是来自训练集的真实数据,哪些是来自生成器的伪数据。也就是说,鉴别器充当着艺术品鉴定专家的角色,评估被认为是达•芬奇画作的作品的真实性。这两个网络不断地“斗智斗勇”,试图互相欺骗:生成器生成的伪数据越逼真,鉴别器辨别真伪的能力就要越强。
网络(network)一词表示最常用于生成器和鉴别器的一类机器学习模型:神经网络。依据GAN实现的复杂程度,这些网络包括从最简单的前馈神经网络(第3章)到卷积神经网络(第4章)以及更为复杂的变体(如第9章的U-Net)。
GAN是如何工作的
支撑GAN的数学理论是较为复杂的(我们将在后面几章中集中探讨,特别是第3章和第5章),幸运的是,我们有许多现实世界的示例可以做类比,这样能使GAN更容易理解。前面我们讨论了一个艺术品伪造者(生成器)试图愚弄艺术品鉴定专家(鉴别器)的示例。伪造者制作的假画越逼真,鉴定专家就必须具有越强的辨别真伪的能力。反过来也是成立的:鉴定专家越善于判断某幅画是否是真的,伪造者就越要改进造假技术,以免被当场识破。
还有一个比喻经常用来形容GAN(Ian Goodfellow经常喜欢用的示例),假币制造者(生成器)和试图逮捕他的侦探(鉴别器)——假钞看起来越真实,就需要越好的侦探才能辨别出它们,反之亦然。
用更专业的术语来说,生成器的目标是生成能最大程度有效捕捉训练集特征的样本,以至于生成出的样本与训练数据别无二致。生成器可以看作一个反向的对象识别模型——对象识别算法学习图像中的模式,以期能够识别图像的内容。生成器不是去识别这些模式,而是要学会从头开始学习创建它们,实际上,生成器的输入通常不过是一个随机数向量。
生成器通过从鉴别器的分类结果中接收反馈来不断学习。鉴别器的目标是判断一个特定的样本是真的(来自训练集)还是假的(由生成器生成)。因此,每当鉴别器“上当受骗”将假的图像错判为真实图像时,生成器就会知道自己做得很好;相反,每当鉴别器正确地将生成器生成的假图像辨别出来时,生成器就会收到需要继续改进的反馈。
鉴别器也会不断地改善,像其他分类器一样,它会从预测标签与真实标签(真或假)之间的偏差中学习。所以随着生成器能更好地生成更逼真的数据,鉴别器也能更好地辨别真假数据,两个网络都在同时不断地改进着。
表1.1总结了GAN的两个子网络的关键信息。
表1.1 生成器和鉴别器的关键信息
GAN的创新
说到使用案例,我们知道GAN是一个不断发展的领域,因此想快速介绍一些可能目前在学术界还没有先前章节中的一些主题那么成熟的内容,但期望这些内容在未来会具有重要意义。秉承实用性的精神,我们挑选了3个有趣且实用的GAN创新:一篇实用论文(RGAN)、一个Github项目(SAGAN)和一项艺术应用(BigGAN)。
1 相对生成对抗网络(RGAN)
我们很少在论文原稿中看到如此简单和优雅但功能强大到足以击败许多最先进算法的报道——相对生成对抗网络(Relativistic GAN,RGAN)就是这样一个例子。RGAN的核心思想是,除了原始的GAN(特别是在第5章中提到的NS-GAN),在生成器中添加了一个额外的项,迫使生成器生成的数据看起来比实际数据更真实。
换言之,除了使伪数据看起来更真实,生成器还应使真实数据看起来相对不太真实,从而可以提高训练的稳定性。当然,生成器能控制的唯一数据是合成数据,因此只能相对地实现此目的。
RGAN的作者将其描述为WGAN的一个通用版本。我们从表5.1中的简化损失函数开始。式 12.1 描述了鉴别器的损失函数,该函数衡量了实际数据(
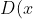
))和生成数据

之间的差异;式12.2描述了生成器的损失函数,该函数试图使鉴别器相信所看到的样本是真实的。

式12.1
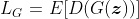
式12.2
回到RGAN最接近的一种GAN——WGAN。要使生成的分布看起来真实,必须移动一定的概率质量,WGAN要使这一概率质量最小化。从这个意义上讲,RGAN和WGAN有许多相似之处(例如,鉴别器通常被称为批评者,而WGAN在本文中是作为RGAN的一个特例展示)。归根结底,这两种方法都是用唯一的数字来衡量所处的现状,还记得推土机距离吗?
RGAN的创新之处在于不用再获得以前那种生成器总是在扮演追赶者角色的无用动力了,换句话说,生成器正试图生成比实际数据更真实的数据,这样它就不会总是处于防御状态。因此,
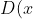
)可以解释为实际数据比生成数据更真实的概率。
在深入探讨差异之前,我们先引入一种略有不同的表示,以近似原论文中所用的表示方法,但更加简化。在式12.3和式12.4中,
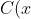
)充当类似于WGAN中的批评者角色,[4] 可以将其视为鉴别器,

()定义为log(sigmoid( ))。原论文中用

代替
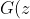
)表示伪样本,用带下标

的
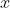
表示真样本,但我们将遵循前几章中更简单的表示法。

式12.3

式12.4
以上等式只体现生成器中的一个关键区别:真实数据现在被添加到损失函数中了,这个看似简单的技巧使生成器不再永久处于劣势。为了在理想化的环境中理解这一点和另外两个观点,图12.1绘制出了不同的鉴别器输出。
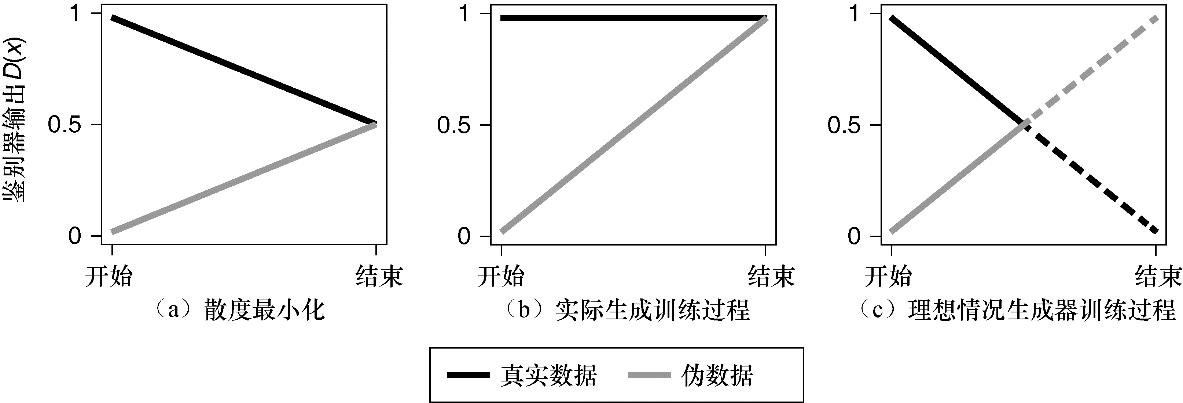
(来源:The Relativistic Discriminator: A Key Element Missing from Standard GAN, by Alexia Jolicoeur-Martineau, 2018.)图12.1 在散度最小化情况下(图(a)),生成器总是在追赶鉴别器(因为散度总是0)。图(b)中展示了“好的”NS-GAN训练的过程,同样,生成器也不可能赢。在图(c)中可以看到
你可能会想,为什么仅增加这样一个项就值得关注呢?因为这个简单的增加仅需很少额外的计算成本就能使得训练更加稳定。这一点很重要,尤其是第5章中提及的Are GAN Created Equal?一文的作者认为,迄今为止所有主要的GAN模型结构在针对额外的处理需求进行调整时,比原始GAN仅有有限的改进。这是因为许多新的GAN模型架构只有消耗巨大的计算成本才会更好,这使得它们的用处更小,但是RGAN有可能全面改变GAN架构。
注意,即使一个方法可能只需要较少的更新步骤,但若是每个步骤由于额外的计算花费而需要两倍的时间,这样做真的值得吗?大多数会议的同行评议过程并不能避免这种弱点,所以你必须小心。
应用
你可能会问为什么这在实践中十分重要?在不到一年的时间里,RGAN的论文已被引用了50多次,这对一位名不见经传的作者来说已经是很高的引用量了。此外,人们已经使用RGAN发表了应用方向的文章,例如用RGAN实现了最先进的语音增强(有史以来最佳性能),击败了其他基于GAN和非GAN的方法。[5]
详细解释这篇论文已经超出了本书的范围,此处不再赘述。
2 自注意力生成对抗网络(SAGAN)
下一个将改变当前 GAN 发展格局的创新是自注意力生成对抗网络(Self-Attention GAN,SAGAN)。注意力是建立在一个非常人性化的观点之上的,即人是如何看待这个世界的——一次只能聚焦在有限的地方[6]。GAN的注意力也是如此:人的意识只能有意地关注桌子的一小部分,但是大脑能够通过快速微小的眼球运动(即扫视)将整张桌子拼接在一起,同时仍然只聚焦于图像的一部分。
类似的原理在自然语言处理和计算机视觉等领域已有广泛的应用。注意力可以帮助解决卷积神经网络(CNN)忽略图片大部分的问题。众所周知,CNN依赖于由卷积大小决定的小的感受野。第5章中,在GAN中感受野的大小很可能会导致问题出现——例如生成有多个头部或身体的奶牛,但GAN并不会认为它们奇怪。
当生成或评估图像的子部分时,程序可能会看到一条腿出现在一个区域,但无法看到其他的腿已经存在于另一个区域。这可能是因为卷积忽略了物体的结构,或者因为腿或腿的旋转是由不同的、更高层次的神经元来表示的——这些神经元彼此没有通信。经验丰富的数据科学家会记得这是Hinton的CapsuleNets试图解决的问题,但并没有真正奏效。没有人能绝对肯定地说出为什么注意力可以解决这个问题,一种好的解释方式是它可以创建一个具有灵活感受野(形状)的特征检测器聚焦在给定图片的几个关键区域(图12.2)。
当图像大小为512×512时,这个问题尤为明显——因为常用的最大卷积大小是7,所以这是大量特征被忽略的关键所在!即使在更高层次的节点中,神经网络也可能无法检查是否合适,例如处在正确位置的头部。因此,只要奶牛有一个头挨着身体,网络就不关心任何其他的头,但这种结构是错误的!

(来源:Convolution Arithmetic, by vdmoulin, 2016.)
图12.2 输出像素(2×2块)会忽略除突出显示地小区域之外的其他内容,注意力帮助解决此问题
这些更高层次的表现更难解释,研究人员还没有就这种情况发生的确切原因达成共识,但从经验上看,网络确实没有学到这些信息。注意力使我们能够选择任何形状或大小的相关区域,并恰当地考虑它们。参考图12.3来观察注意力可以灵活关注的区域类型。

(来源:Self-Attention Generative Adversarial Networks,by Han Zhang, 2018.)
图12.3 在给定具有代表性的查询定位的情况下,注意机制最关注的图像区域。可以看到注意力机制通常关心不同形状和大小的区域,这是一个好兆头,因为我们希望它能挑出图像决定对象类型的区域
应用
DeOldify是Jeremy Howard教授的fast.ai课程的学生Jason Antic制作的流行的SAGAN应用之一。DeOldify使用SAGAN为老旧的图像和绘画着色,并达到了一个惊人的准确水平。图12.4展示将著名的历史照片和绘画变成全彩色版本。

(a) (b)
图12.4 Deadwood, South Dakota,1877年。这是一本黑白印刷书中的插图,图(b)中的图像实际上已经着色了
3 BigGAN
另一个让世界瞩目的网络是BigGAN。 BigGAN在ImageNet的所有1000类图像上实现了高度逼真的512×512图像生成,在此之前,这一壮举被认为在现有的GAN中几乎是不可能实现的。BigGAN取得了3倍于之前最佳算法的视觉得分。简而言之,建立在SAGAN和频谱归一化的基础上的BigGAN在5个方向上进行了进一步创新。
(1)把GAN扩展到以前难以置信的计算规模。BigGAN的作者们使用了8倍于之前的批处理大小来训练,这是他们成功的一部分原因——此举已经能使性能提高46%。理论上,训练BigGAN所需的资源总计价值5.9万美元。[8]
(2)BigGAN的结构与SAGAN相比,每层中的通道(特征图)数量是后者的1.5倍——这可能要归因于所用数据集的复杂性。
(3)如果通过控制对抗过程来提高生成器和鉴别器的稳定性,可以带来总体上更好的效果。这一方法背后的数学知识超出了本书讨论的范围,如果你对此感兴趣,可以从了解频谱归一化开始。不感兴趣的人则大可放心,因为即使是文章作者,在后面的训练中也放弃了这种策略,而且由于计算成本过高而使模式崩溃。
(4)引入截断技巧(truncation trick),给出了一种控制多样性与保真度之间平衡的方法。如果在接近分布中心的位置采样(截断),截断技巧可以获得更好的等效结果。这是有意义的——因为将产生更好的样本,这也是BigGAN拥有“最丰富经验”之处。
(5)作者还介绍了另外3个理论进展,但是根据作者自己的结果,这些操作似乎只对分数产生轻微的影响,还常导致稳定性降低。实际上它们对提高计算效率很有用,但此处不予讨论。
应用
BigGAN一个迷人的艺术应用是Ganbreeder App,这得益于预先训练的模型和Joel Simon的辛勤工作。Ganbreeder是一个基于网页的交互式(免费的)探索BigGAN潜在空间的方法,作为一种创造新图像的技术,已被广泛应用于艺术领域。
你既可以探索两个相邻的潜在空间,也可以在两个不同图像域的两个样本之间使用线性插值来创建新图像。图12.5显示了一个在Ganbreeder上进行创作的例子。
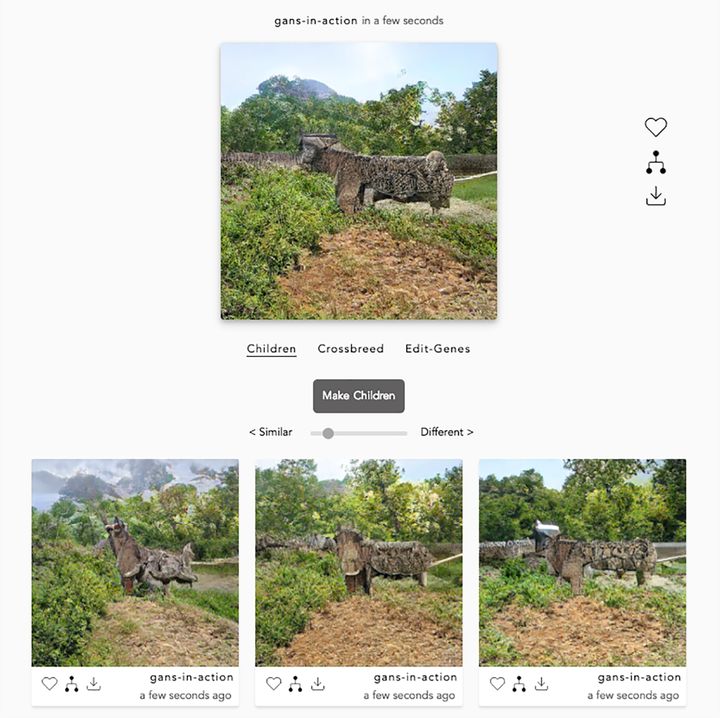
(来源:Ganbreeder)图12.5 每次单击Make Children按钮,Ganbreer都会提供附近潜在空间中的一系列突变,从而生成下面的3幅图像。可以从自己的样本或他人的样本开始,从而使之成为一个合作的练习。这就是Crossbreed部分用途,可以从潜在空间的其他部分选择另一个有趣的样本并混合。最后在Edit-Genes中
BigGAN值得进一步关注,因为DeepMind免费提供了所有这些计算,并将预训练模型上传到了TensorFlow Hub上(TensorFlow Hub是在第6章中使用的机器学习代码仓库)。
GAN书籍推荐
GAN实战

本书主要介绍构建和训练生成对抗网络(GAN)的方法。全书共12 章,先介绍生成模型以及GAN 的工作原理,并概述它们的潜在用途,然后探索GAN 的基础结构(生成器和鉴别器),引导读者搭建一个简单的对抗系统。
本书给出了大量的示例,教读者学习针对不同的场景训练不同的GAN,进而完成生成高分辨率图像、实现图像到图像的转换、生成对抗样本以及目标数据等任务,让所构建的系统变得智能、有效和快速。
PyTorch生成对抗网络编程

本书以直白、简短的方式向读者介绍了生成对抗网络,并且教读者如何使用PyTorch按部就班地编写生成对抗网络。全书共3章和5个附录,分别介绍了PyTorch基础知识,用PyTorch开发神经网络,改良神经网络以提升效果,引入CUDA和GPU以加速GAN训练,以及生成高质量图像的卷积GAN、条件式GAN等话题。附录部分介绍了在很多机器学习相关教程中被忽略的主题,包括计算平衡GAN的理想损失值、概率分布和采样,以及卷积如何工作,还简单解释了为什么梯度下降不适用于对抗式机器学习。
本书适合想初步了解GAN以及其工作原理的读者,也适合想要学习如何构建GAN的机器学习从业人员。对于正在学习机器学习相关课程的学生,本书可以帮助读者快速入门,为后续的学习打好基础。
以上是关于为什么对抗生成网络(GAN)被誉为过去20年来深度学习中最酷的想法?的主要内容,如果未能解决你的问题,请参考以下文章