webrtc音频发送流程
Posted linalg
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了webrtc音频发送流程相关的知识,希望对你有一定的参考价值。
一 概述
webrtc 音频数据整个流程的代码调用图:
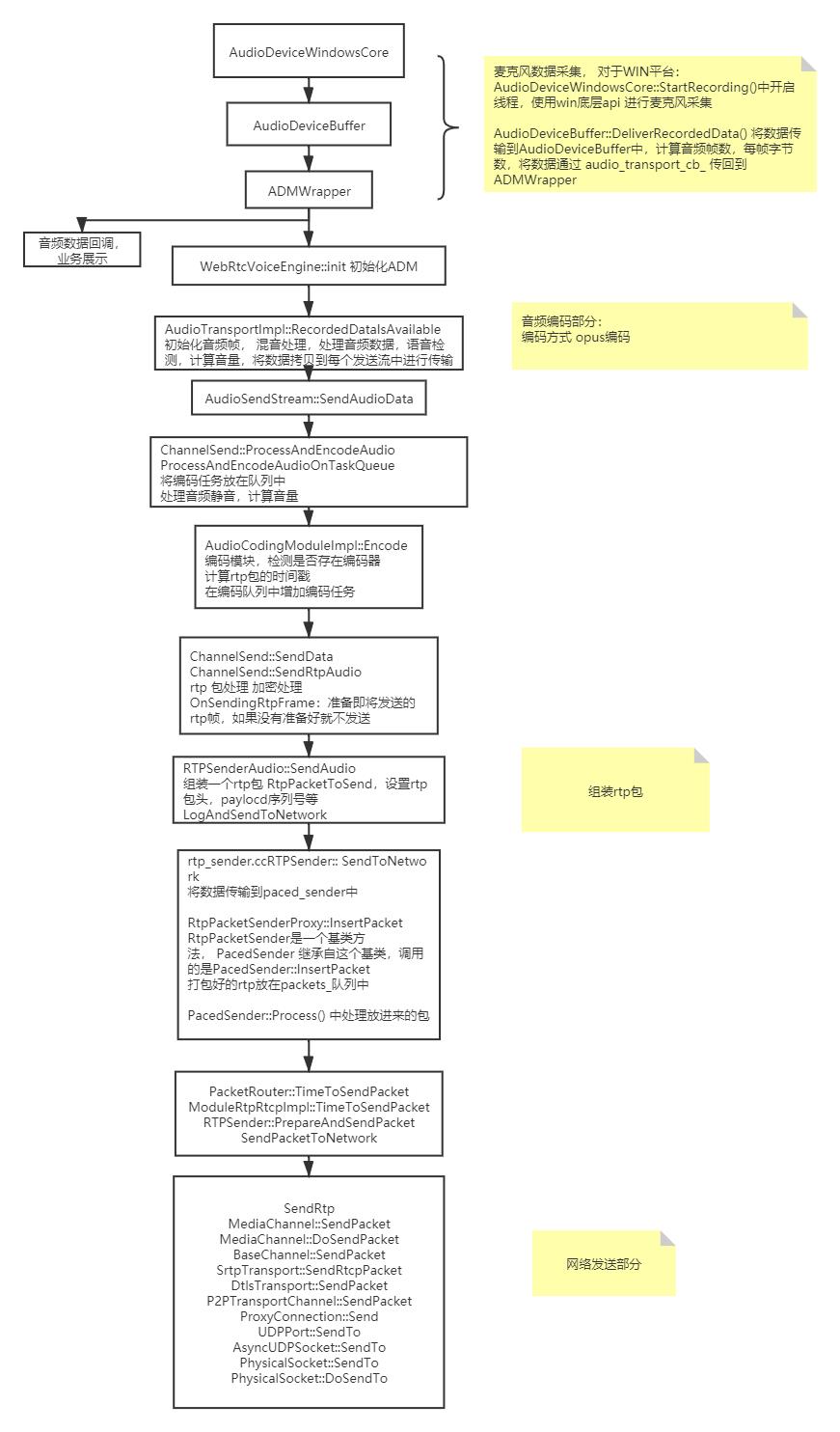
二 采集部分
采集部分:使用平台上的麦克风采集api, 代码模块: moudles/audio_devce
ADMWarpper类封装了音频设备类 AudioDeviceModule, AudioDeviceDataObserver 类,AudioTransport类, 其中AudioDeviceModule 封装拉流各个平台的麦克风采集API, AudioDeviceDataObserver 可以将采集到的原始数据向外抛出,进行业务展示; AudioTransport 将原始数据进行编码传输等。
采集部分代码:
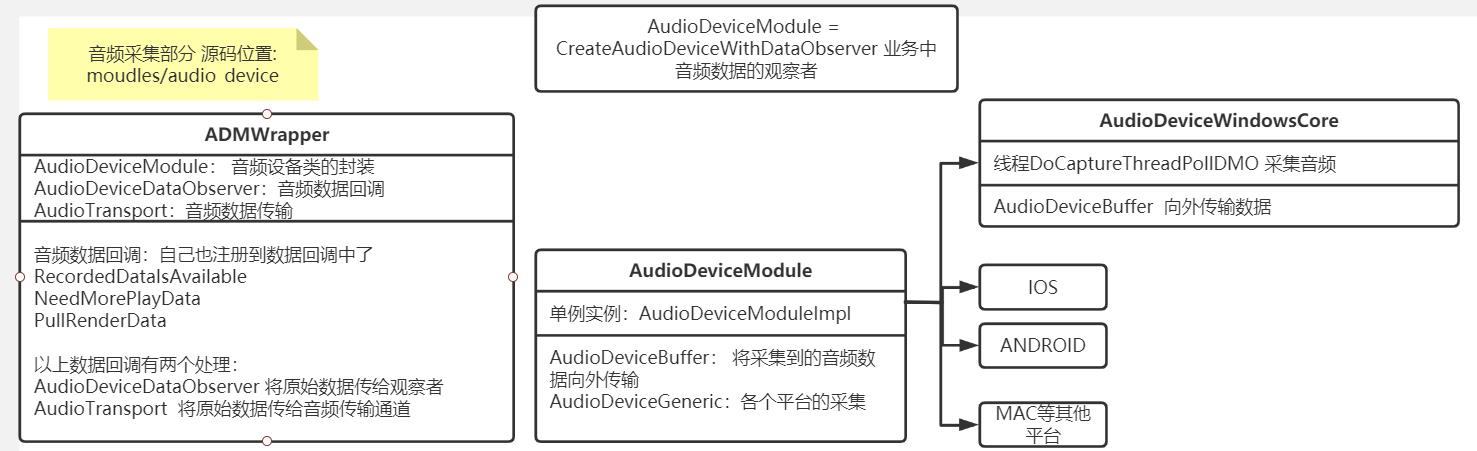
采集前会遍历麦克风设备,获取设备信息,InitRecordingDMO
使用AEC时麦克风设备属性:
typedef struct tWAVEFORMATEX
WORD wFormatTag; WAVE_FORMAT_PCM //音频格式
WORD nChannels; 1 //通道
DWORD nSamplesPerSec; 16000 //采样率
DWORD nAvgBytesPerSec; 32000 //平均每秒的字节数
WORD nBlockAlign; 2 //数据块大小
WORD wBitsPerSample; 16 //位数
WORD cbSize;
WAVEFORMATEX;
AudioDeviceWindowsCore::StartRecording()
win下启用AEC硬件回音消除,启用AEC是在 WebrtcVoiceEngine::init中 const bool enable_built_in_aec =
*options.echo_cancellation && !use_delay_agnostic_aec;
WSAPICaptureThreadPollDMO->DoCaptureThreadPollDMO,开启采集线程,
DWORD waitResult = WaitForSingleObject(_hShutdownCaptureEvent, 5); 采集音频的间隔是5毫秒
音频数据传输到 AudioDeviceBuffer中, AudioDeviceBuffer 中计算每个通道的帧数等,将数据通过回调传给audio_transport_cb_
ADMWrapper 中接收该数据,并且将数据传输 RecordedDataIsAvailable
observer 是收到了采集到的原始数据, 原始数据打包成AudioFrame, 进行重采样,通过回调observer将数据传输到上层
audio_transport_ 将数据传输到编码层
AudioTransportImpl::RecordedDataIsAvailable
InitializeCaptureFrame 在不丢音频信息的情况下,选择最低的采样率和通道数,选择本机最小的设备输入和编码采样频率,最小的通道数配置AudioFrame
RemixAndResample 重采样 降低或者提高音频的通道数
计算音频声音大小,将数据拷贝到每个要发送的流中。
ChannelSend::ProcessAndEncodeAudio 将一个AudioFrame数据放在编码队列中, 编码前处理音频静音(静音是将该帧的音频数据重置为0)、添加帧的时间戳,编码完后调用packetization_callback_->SendData 将数据发送出去
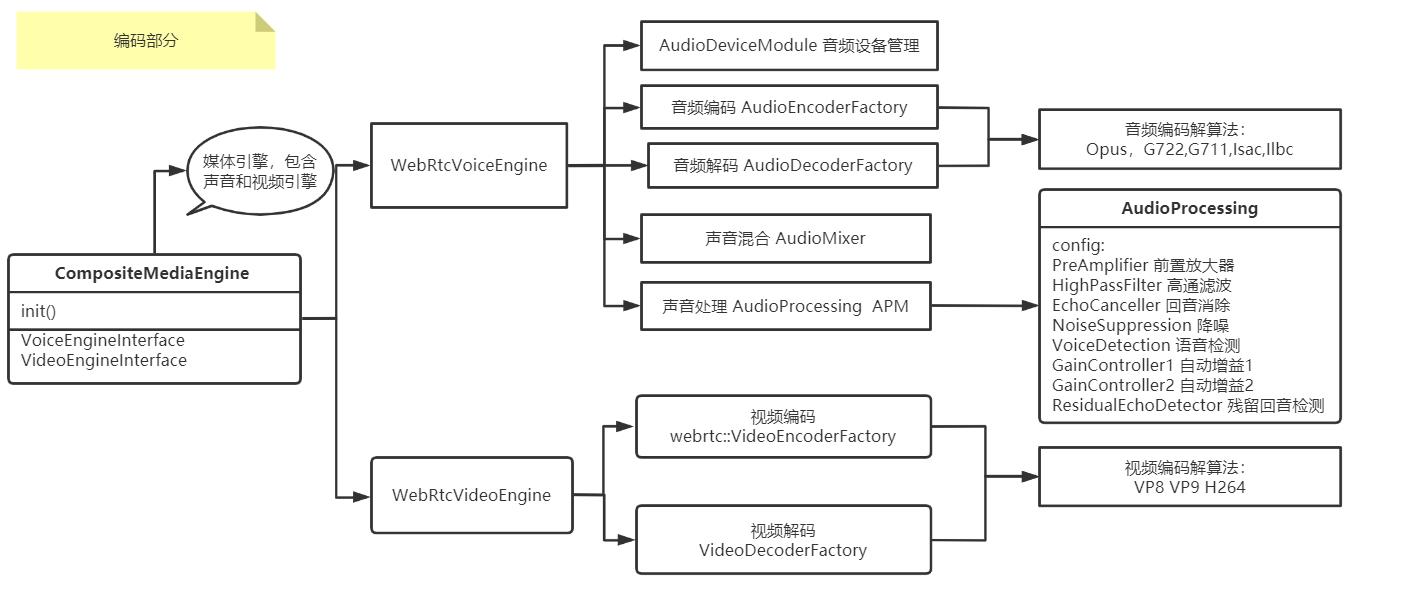
三 编码部分
采集到的音频可能存在噪音,所以需要对源数据进行预处理, 预处理模块 AudioProcessing,处理完后对音频进行编码
编码前需要对声音进行预处理 AudioProcessing,
编码部分:一般的编码算法: Opus,G722,G711,Isac,Ilbc, 编码完成后将音频数据打包成rtp, 音频的编码方式是根据sdp协商来的,
m=audio 9 UDP/TLS/RTP/SAVPF 111 102 103 104 9 0 8 106 105 13 110 112 113 126
表示流中包含音频数据, 端口号9, 使用udp协议 tls加密rtp包,SAVPF代表使用srtcp的反馈机制来控制通信过程, 编码方式使用111, 111在后面的sdp中有说明:
a=rtpmap:111 opus/48000/2 //opus编码, 48000hz, 双通道
a=rtcp-fb:111 transport-cc // 支持 rtcp 协议控制拥塞
a=rtcp-fb:111 nack // 支持丢包重传
a=fmtp:111 minptime=10;useinbandfec=1 //对opus编码可选的补充说明,minptime代表最小打包时长是10ms,useinbandfec=1代表使用opus编码内置fec特性。
数据发送:
packetization_callback_->SendData(
frame_type, encoded_info.payload_type, encoded_info.encoded_timestamp,
encode_buffer_.data(), encode_buffer_.size());
发送音频数据 payload_type就是sdp协商的类型,也是编码方式。
三 发送部分
发送部分主要将音频数据打包成rtp包, 平滑发送 rtp 包和rtcp包, 最后数据通过udp发送到对端。
1. rtprtcp 部分
RTP(Real-time Transport Protocol 实时传输协议) 协议是网络中对于流媒体传输的基础协议,RTP协议本身只保证数据实时传输,并不保证数据安全到达。与RTP 配套的协议是 RTCP(Real-time Transport Control Protocol) 实时传输控制协议,RTCP提供流量控制和拥塞服务。 rtc会话期间参与者周期性的发送rtcp报文,包括接收和发送数据的内容, 参与者根据 rtcp 数据动态调整。
音频转发到ChannelSend::SendRtpAudio 时,在rtp扩展头中增加音量属性, 对音频数据进行加密, 发送rtcp数据(webrtc中rtcp的发送规则:默认配置rtcp音频间隔5秒钟, 视频间隔1秒钟, 两个rtcp包的发送间隔是 [0.5 ~ 1.5]*默认间隔)。
RTPSender::SendToNetwork 中做了两件事: 1. 判断是否开启了fec,开启fec将rtp包存储到 flexfec_packet_history_,否则 将该rtp包存储到packet_history_中,为以后重发该rtp包做准备 2. 将该包插入paced_sender中, paced_sender按照优先级发送包, 优先级高的会立即发送
2. PacedSender 部分
PacedSender 部分:通过gcc估算出的码率来计算当前应该发送多少字节的数据。GoogCcNetworkController: GCC谷歌提出的拥塞控制算法(简称GCC[1])来控制发送端码率,设置两个码率:pacing_rate_bps 和 padding_rate_bps,其中pacing_rate_bps 是发送码率控制, padding_rate_bps 是填充码率控制(webrtc引入padding机制来保障发送尽量大的数据来探测网络带宽上限)。
media_budget_和padding_budget_ 保存了媒体发送预算和填充数据 每次可以发送的字节数。
PacedSender::Process()中先计算了要发送的剩余数据及包的平均剩余时间, 获取最小发送码率, 判断是否暂停和是否有发送包,再发送包时会根据包的优先级和media_budget_ 判断是否发送包, 如果发送失败,会将该包重新重新放入发送队列中。 包发送完后会判断是否发送 padding数据。
PacedSender发送相关类:
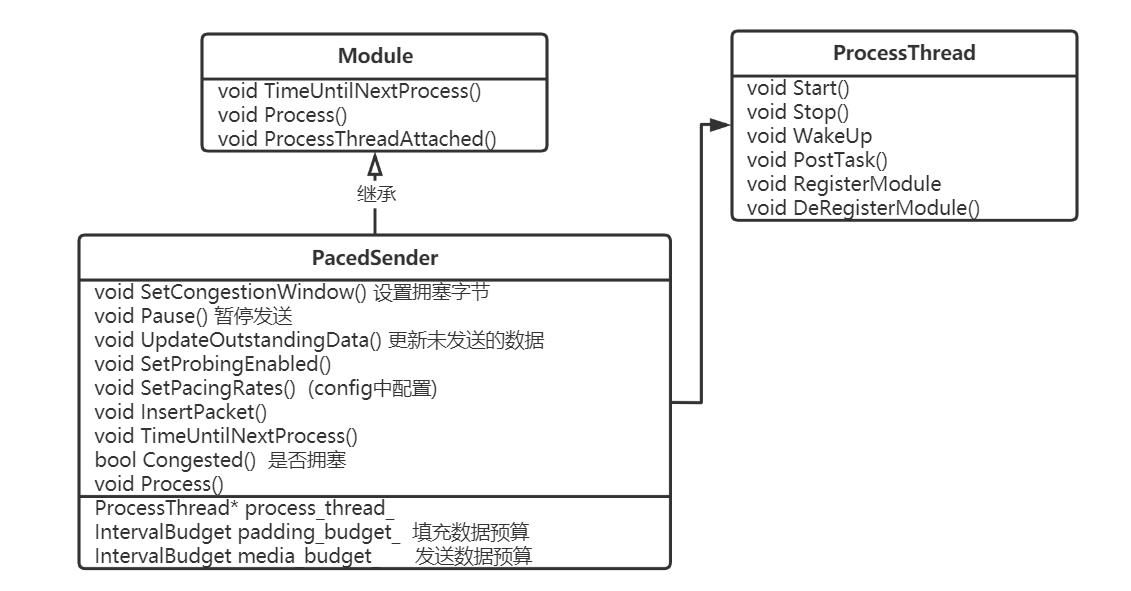
webrtc module用来处理定时重复任务,module 三个接口:
TimeUntilNextProcess 距离下次任务执行的时间间隔
Process 任务处理函数
ProcessThreadAttached 绑定ProcessThread到当前模块
PacedSender类继承Module类, 内部有ProcessThread 来定时执行发送任务
rtp_transport_controller_send.cc中将 PacedSender线程注册到ProcessThread模块中, ProcessThread线程开始执行,run中会遍历所有的模块, 计算每个模块下次执行的时间,执行每个模块的Process()任务, ProcessThread 还支持PostTask任务。
四 总结

音频采集到发送的流程如上图: 音频采集和每个平台的底层API相关, windows上使用core audio, 音频预处理, 主要进行重采样、声道、回音抑制、声音检测等, 音频编码将音频数据进一步压缩,编码算法的选择是sdp协商的结果, 音频数据编码封装成rtp包,同时还会检查是否需要发送rtcp数据, 最后进行平滑发送到udp接口。
WebRTC Native M96 音频发送流程(SendRtp)以及接收音频包播放流程(OnPacketReceived)
WebRTC默认是采用Opus编码。
Opus是一个有损音频压缩的数字音频编码格式,由Xiph.Org基金会开发,之后由互联网工程任务组(IETF)进行标准化,目标是希望用单一格式包含声音和语音,取代Speex和Vorbis,且适用于网络上低延迟的即时声音传输,标准格式定义于RFC 6716文件。Opus格式是一个开放格式,使用上没有任何专利或限制。
Opus集成了两种声音编码的技术:以语音编码为导向的SILK和低延迟的CELT。Opus可以无缝调节高低比特率。在编码器内部它在较低比特率时使用线性预测编码在高比特率时候使用变换编码(在高低比特率交界处也使用两者结合的编码方式)。Opus具有非常低的算法延迟(默认为22.5 ms,非常适合用于低延迟语音通话的编码,像是网络上的即时声音流、即时同步声音旁白等等,此外Opus也可以透过降低编码比特率,达成更低的算法延迟,最低可以到5 ms。在多个听觉盲测中,Opus都比MP3、AAC、HE-AAC等常见格式,有更低的延迟和更好的声音压缩率。
不过今天不谈Opus,主要讲两个方面:
1. 音频采集–>编码–>发送音频包
2. 音频包接收–>解码–>音频播放
音频数据从采集到发送数据包的处理流程
录制线程将录制的麦克风音频数据抛上来
线程:webrtc_core_audio_capture_thread
AudioDeviceWindowsCore::WSAPICaptureThreadPollDMO
AudioDeviceWindowsCore::DoCaptureThre以上是关于webrtc音频发送流程的主要内容,如果未能解决你的问题,请参考以下文章