hadoop是啥意思?与大数据有啥关系?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop是啥意思?与大数据有啥关系?相关的知识,希望对你有一定的参考价值。
一、hadoop是什么意思?
Hadoop是具体的开源框架,是工具,用来做海量数据的存储和计算的。
二、hadoop与大数据的关系
首先,大数据本身涉及到一个庞大的技术体系,从学科的角度来看,涉及到数学、统计学和计算机三大学科,同时还涉及到社会学、经济学、医学等学科,所以大数据本身的知识量还是非常大的。
从当前大数据领域的产业链来看,大数据领域涉及到数据采集、数据存储、数据分析和数据应用等环节,不同的环节需要采用不同的技术,但是这些环节往往都要依赖于大数据平台,而Hadoop则是当前比较流行的大数据平台之一。
Hadoop平台经过多年的发展已经形成了一个比较完善的生态体系,而且由于Hadoop平台是开源的,所以很多商用的大数据平台也是基于Hadoop搭建的,所以对于初学大数据的技术人员来说,从Hadoop开始学起是不错的选择。
当前Hadoop平台的功能正在不断得到完善,不仅涉及到数据存储,同时也涉及到数据分析和数据应用,所以对于当前大数据应用开发人员来说,整体的知识结构往往都是围绕大数据平台来组织的。随着大数据平台逐渐开始落地到传统行业领域,大数据技术人员对于大数据平台的依赖程度会越来越高。
当前从事大数据开发的岗位可以分为两大类,一类是大数据平台开发,这一类岗位往往是研发级岗位,不仅岗位附加值比较高,未来的发展空间也比较大,但是大数据平台开发对于从业者的要求比较高,当前有不少研究生在毕业后会从事大数据平台开发岗位。
另一类是大数据应用开发岗位,这类岗位的工作任务就是基于大数据平台(Hadoop等)来进行行业应用开发,在工业互联网时代,大数据应用开发岗位的数量还是比较多的,而且大数据应用开发岗位对于从业者的要求也相对比较低。
参考技术A Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
大数据只是区别于传统关系型数据库
现在最成熟的开源nosql是啥?分别有啥优缺点
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
虽然NoSQL流行语火起来才短短一年的时间,但是不可否认,现在已经开始了第二代运动。尽管早期的堆栈代码只能算是一种实验,然而现在的系统已经更加的成熟、稳定。不过现在也面临着一个严酷的事实:技术越来越成熟——以至于原来很好的NoSQL数据存储不得不进行重写,也有少数人认为这就是所谓的2.0版本。这里列出一些比较知名的工具,可以为大数据建立快速、可扩展的存储库。
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
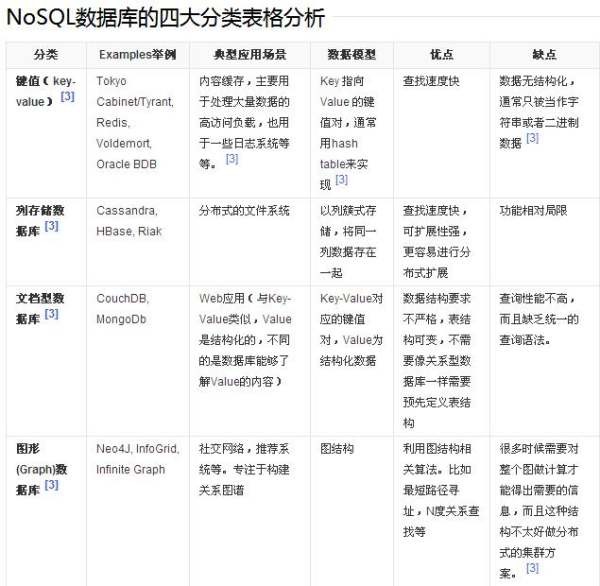
NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
参考技术A Apache三剑客:HBase, Cassandra, CouchDB。HBase的前景最为看好,因为它的开发者众多并且都是顶尖高手。Cassandra目前有很多否定的声音。CouchDB的小而精悍,赞誉很多,将要正式发布的CouchBase融合了MemBase和CouchDB,很令人期待。HBase和Cassandra都是效仿Google的BigTable的基于列的数据库,它们都是用Java写的。另外一类似的数据库是HyperTable,百度用在一些后台分析,因为它是C++写的,速度比较快。不过HyperTable有点边缘,不太流行。这些基于列的开源数据库目前都比Goolge的BigTable差之少一个数量级
CouchDB是一个文档数据库。其最大的竞争者是MongoDB。MongoDB和HBase都采用主从服务器设计。CouchDB的服务器分布设计和Cassandra类似,Peer to Peer类型的。主从服务器设计一般能更好的strong consistent,属于CAP理论中的CP类型。 CouchDB和Cassandra一般认为都是eventual consistent,属于CAP理论中的AP类型。但其实MongoDB和Cassandra都可以设置成strong consistent或者eventual consistent。
以上所提到的数据库都支持MapReduce。好像出了HyperTable都支持非主键索引。HBase和strong consistent配置的MongoDB都支持最基本的锁定(HBase单行锁定,MongoDB单文档锁定),因此可以实现transaction,但是实现有点复杂和低效。单就transaction这一点,目前开源NoSQL数据库没有做的比较好的。
MongoDB的最大卖点是不需构建非主键索引也能执行很多查询。但是MongoDB的服务器分布设计实在不能让人恭维,可以说是NoSQL数据库中最Ugly的实现。
K-V数据库比较多,而且上面提到的基于列的数据库和文档数据库其实也都是K-V数据库。比较流行的纯种K-V数据库有:
Memcached: 非常流行,不支持持久化
VMWare's Redis: 很流行,新浪和知乎都在用,CP类型。
MemBase: 由很多Memcached的开发者开发,使用sqlite作底层存储。在社交游戏中用的比较多, zynga在用,CP类型。
Riak, 分布式实现和CouchDB/Cassandra比较像,AP类型。支持MapReduce。
Linkin's Voldemort, 在K-V中少见的eventual consistent ,AP类型。
TT, TC
纯基于二维座标索引的是Neo4j。但是现在MongoDB和CouchDB都集成这一特性。
目前CouchDB的开发者成立的公司CouchOne收购了MemBase,将其底层sqlite换成CouchDB推出了CouchBase,从而引入MapReduce以支持非主键索引。CouchBase暂时还没有正式发布官方正式版,不过快了。虽然CouchDB是eventual consistent的,但是CouchBase的开发者宣称CouchBase保持了MemBase的strong consistent特性,具体实现有待以后研究。
如果从成熟的角度来看,比较成熟并且十分流行的的有CouchDB,Memcached,Redis。
HBase和MongonDB和Cassandra都比较新,处于频繁更新之中。最有前途的是HBase,但是Hadoop/HBase集群的维护常常需要很多专业人员并且需要构建一个比较大的集群才能最大化体现出威力,因此用户主要是Facebook, yahoo, 百度和阿里巴巴等大公司。
个人比较期待CouchBase。
转载仅供参考,版权属于原作者。祝你愉快,满意请采纳哦
以上是关于hadoop是啥意思?与大数据有啥关系?的主要内容,如果未能解决你的问题,请参考以下文章