如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是啥关系?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是啥关系?相关的知识,希望对你有一定的参考价值。
参考技术A大数据本身是一个非常宽泛的概念,而Hadoop生态系统(或一般的生态系统)基本上是单一规模的数据处理。你可以把它和厨房比较,所以我需要各种工具。锅碗瓢盆,各有其用,重叠。你可以在碗里直接用汤锅。你可以用刀或飞机去皮。每个工具都有自己的特性,虽然奇数可以工作,但不一定是最好的。大数据,首先你需要能够保存大数据。传统的文件系统是单一的,而不是跨不同的机器。HDFS (Hadoop分布式文件系统)本质上是为大量数据设计的,这些数据可以跨越数千台机器,但是您看到的是一个文件系统,而不是很多文件系统。

例如,如果您说我想获得数据/HDFS/TMP/file1,那么您可以引用一个文件路径,但是实际的数据存储在许多不同的机器中。作为用户,您不需要知道这一点,就像您不关心分散在某个扇区上的单个文件一样。HDFS为您管理这些数据。使用现有数据,您将开始考虑如何处理数据。虽然HDFS可以为您提供对不同机器上的数据的全面管理,但是数据太大了。数据可以在机器上读取到T P(哦,很多数据,比如东京热的整体尺寸,所有的高清电影),机器运行缓慢,可能需要几天或几周的时间。对于许多公司来说,单句柄是不能容忍的,比如twitter的24小时更新,必须在24小时内运行。所以如果我想用大量的机器处理,我将面对如何分工,如果机器挂断了如何重新启动相应的任务,如何与对方沟通交换数据,完成复杂的计算等等。这是图/Tez/Spark的函数。图是第一代计算机引擎,Tez和Spark是第二代。
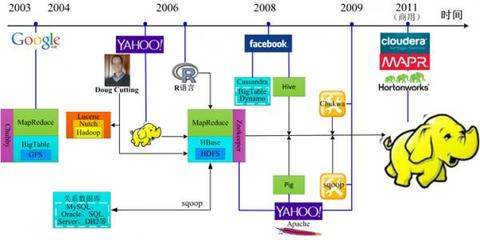
使用简化的计算模型,只有两个图,并且通过使用这个模型简化计算过程(中间),这是一个很大的问题,可以用大数据字段处理。地图的缩小是多少?如果要在类似的HDFS中存储大型文本文件的统计信息,则需要知道文本中每个单词的频率。你开始一个项目。Map阶段,同时,数百个不同部分的机器,读取这个文件,分别读取各部分的词频统计,分别有相似的(你好,12100),(15214)世界等(这里我把地图和在一起,为了简化);数百台机器被收集,数百台机器开始减少加工。由于mapper将接收所有统计结果,机器将获得B B词汇统计数据(实际上,在不以字母开头的基础上,当然,作为一个散列函数,以避免数据字符串)。因为在单词开头的类似的X被认为比其他的要小得多,而且您不需要为每台机器处理数据处理工作负载差异。然后,还原器将再次汇总,(hello, 12100) + (hello, 12311) + (hello, 345881) = (hello, 370292)。如上所述,您拥有整个单词频率结果文件。这看起来是一个非常简单的模型,但是很多人可以用这个模型来描述算法。地图+简单的模型还原非常色情,非常暴力,虽然有用,但它很重。
第二代的冬季和引发新特性除了内存缓存,从本质上讲,是使Map / Reduce模型更通用,让Map和Reduce之间的界限更模糊,数据交换更灵活和更少的磁盘读写,为了更好地描述复杂算法,以获得更高的吞吐量。由于图形、Tez和Spark,程序员发现很难为程序编写图形。他们想简化这个过程。就像你有汇编语言一样,你几乎可以做任何事情,但你仍然觉得它很麻烦。您需要更高层次的抽象来描述算法和数据处理。所以会有一头猪和一个蜂巢。猪非常接近脚本,并使用SQL来描述图表。他们将脚本和SQL转换成程序,把它丢给计算引擎,而你没有一个繁琐的程序来用更简单、更直观的语言编写程序。在一个hive之后,发现了SQL contras。
Hadoop生态优秀文章集锦
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
https://www.zhihu.com/question/27974418
HBase 和 Hive 的差别是什么,各自适用场景?
https://www.zhihu.com/question/21677041
以上是关于如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是啥关系?的主要内容,如果未能解决你的问题,请参考以下文章