从Hadoop框架讨论大数据生态
Posted pier~呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Hadoop框架讨论大数据生态相关的知识,希望对你有一定的参考价值。
文章目录
从Hadoop框架讨论大数据生态
在上一章,我们讨论了什么是大数据,相信,了解了大数据一番,肯定不免得知道Hadoop集群框架,今天我们一起来讨论讨论Hadoop集群框架吧。浅谈什么是大数据_pier~呀的博客-CSDN博客
Hadoop 是什么(一是)
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop发展史(二知)
Hadoop最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。
Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目(同年,cloudera公司成立),迎来了它的快速发展期。
狭义上来说,hadoop就是单独指代hadoop这个软件,
广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件。
这里来源于百度知识,具体想要了解的可以自行百度。
Hadoop三大版本(三版)
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
-
Apache版本最原始(最基础)的版本,对于入门学习最好。
- 官网地址:http://hadoop.apache.org/releases.html
- 下载地址:https://archive.apache.org/dist/hadoop/common/
-
Cloudera内部集成了很多大数据框架。对应产品CDH。
- 官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
- 下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
-
Hortonworks文档较好。对应产品HDP。
- 官网地址:https://hortonworks.com/products/data-center/hdp/
- 下载地址:https://hortonworks.com/downloads/#data-platform
Hadoop的优势(4高)
-
高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失
-
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
-
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
-
高容错性:能够自动将失败的任务重新分配。
Hadoop的组成(关于吾的自身)
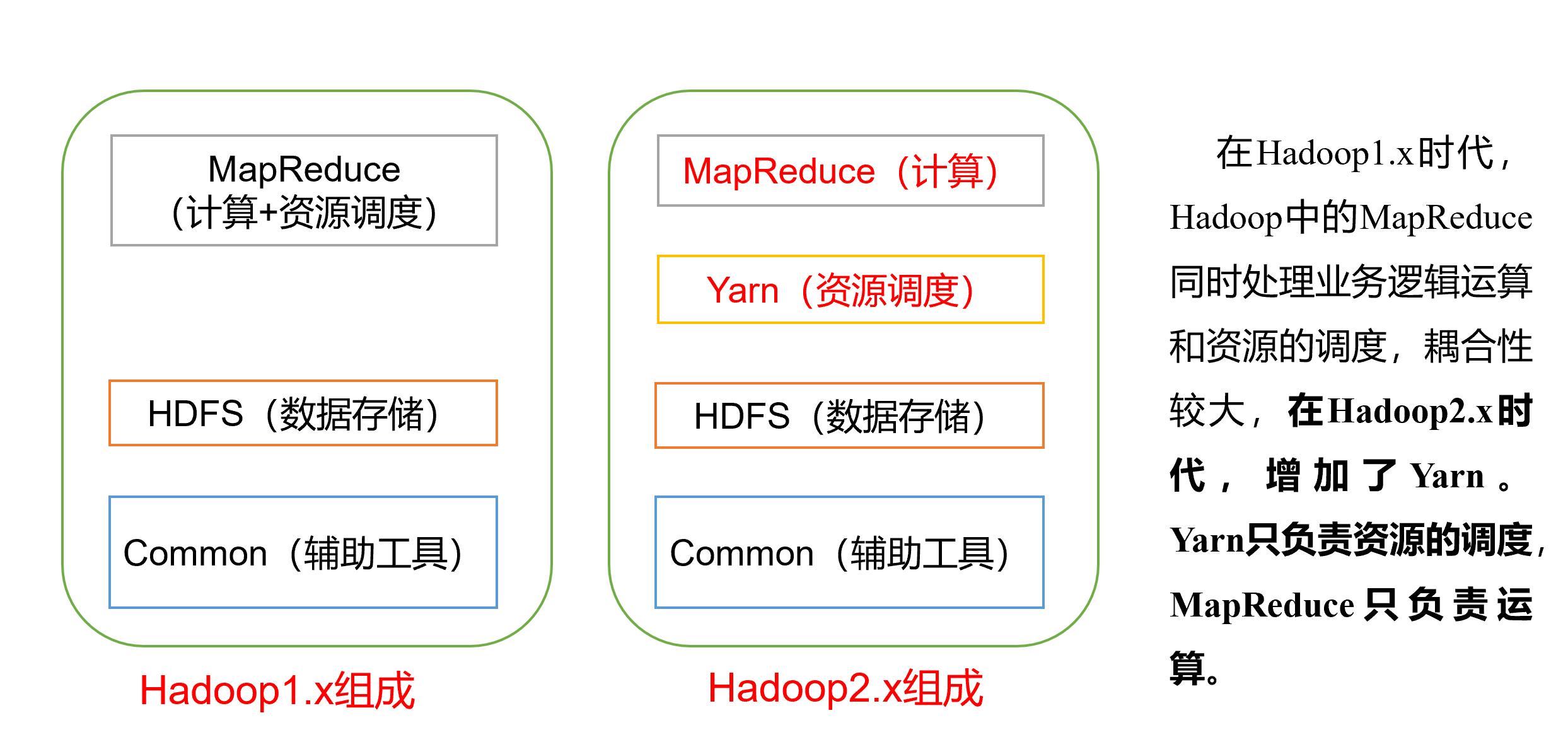
Hadoop1.x和Hadoop2.x的区别
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大,在Hadoop2.x时代,增加了Yarn 。Yarn只负责资源的调度,MapReduce只负责运算。
HDFS 架构概述
-
NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
-
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
-
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
他们之间的关系是怎样的呢?

Yarn架构概述
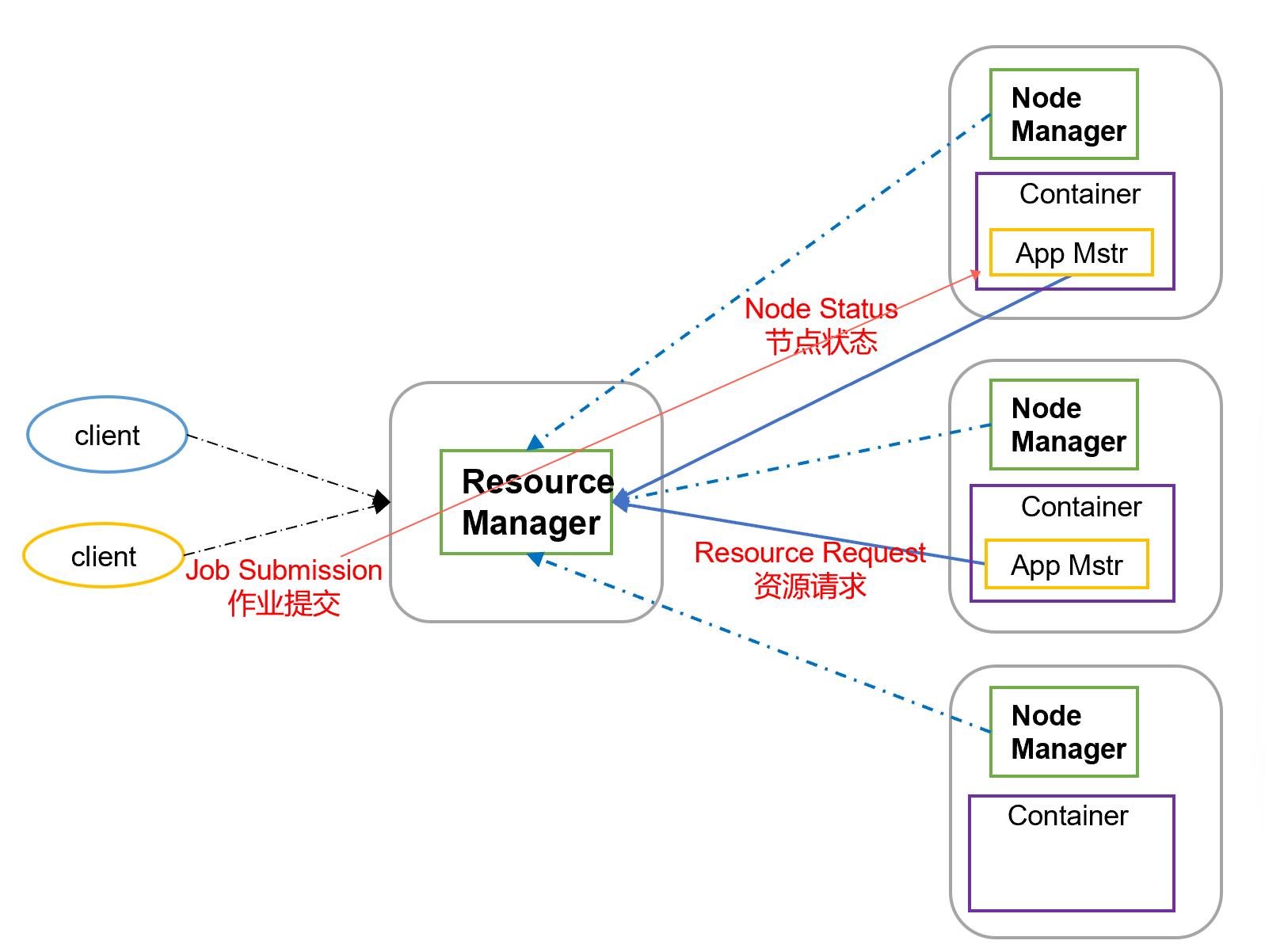
从YARN的架构图来看,它主要由ResourceManager和ApplicationMaster、NodeManager、ApplicationMaster和Container等组件组成。
ResourceManager(RM)
YARN分层结构的本质是ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础NodeManager(YARN 的每节点代理)。ResourceManager还与 ApplicationMaster 一起分配资源,与NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
主要作用:
1)处理客户端请求;
2)启动或监控ApplicationMaster;
3)监控NodeManager;
4)资源的分配与调度。
NodeManager(NM)
NodeManager管理一个YARN集群中的每个节点。NodeManager提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1通过插槽管理Map和Reduce任务的执行,而NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。YARN继续使用HDFS层。它的主要 NameNode用于元数据服务,而DataNode用于分散在一个集群中的复制存储服务。
主要作用:
1)单个节点上的资源管理;
2)处理来自ResourceManager上的命令;
3)处理来自ApplicationMaster上的命令。
ApplicationMaster(AM)
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
主要作用:
1)负责数据的切分;
2)为应用程序申请资源并分配给内部的任务;
3)任务的监控与容错。
Container
对任务运行环境进行抽象,封装CPU、内存等多维度的资源以及环境变量、启动命令等任务运行相关的信息。比如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
要使用一个YARN集群,首先需要来自包含一个应用程序的客户的请求。ResourceManager 协商一个容器的必要资源,启动一个ApplicationMaster 来表示已提交的应用程序。通过使用一个资源请求协议,ApplicationMaster协商每个节点上供应用程序使用的资源容器。执行应用程序时,ApplicationMaster 监视容器直到完成。当应用程序完成时,ApplicationMaster 从 ResourceManager 注销其容器,执行周期就完成了。
MapReduce架构描述
mapreduce是一个分布式运算程序的编程框架,是hadoop数据分析的核心. mapreduce的核心思想是将用户编写的逻辑代码和架构中的各个组件整合成一个分布式运算程序,实现一定程序的并行处理海量数据,提高效率.
MapReduce将计算一分为二,Map和Reduce。它巧妙的让我们的计算就像做一道数学题一样,把每一个大问题拆分为一个个小问题就是我们的Map阶段,将每一个小问题解决后再合并起来就是我们的Reduce阶段。和我们剪辑一样,我们有很多的视频集锦,可能并不是一个人拍的,我们把你和你对象的放在一起,这就是Map,你们的异地恋也是不一样的风景呢!然后,可能女孩子需要仪式感,你就把你们两的行程剪在一起,做成一个合集,这就是一个Reduce过程。最后你们的过年祝福就好了。
大数据技术生态系统
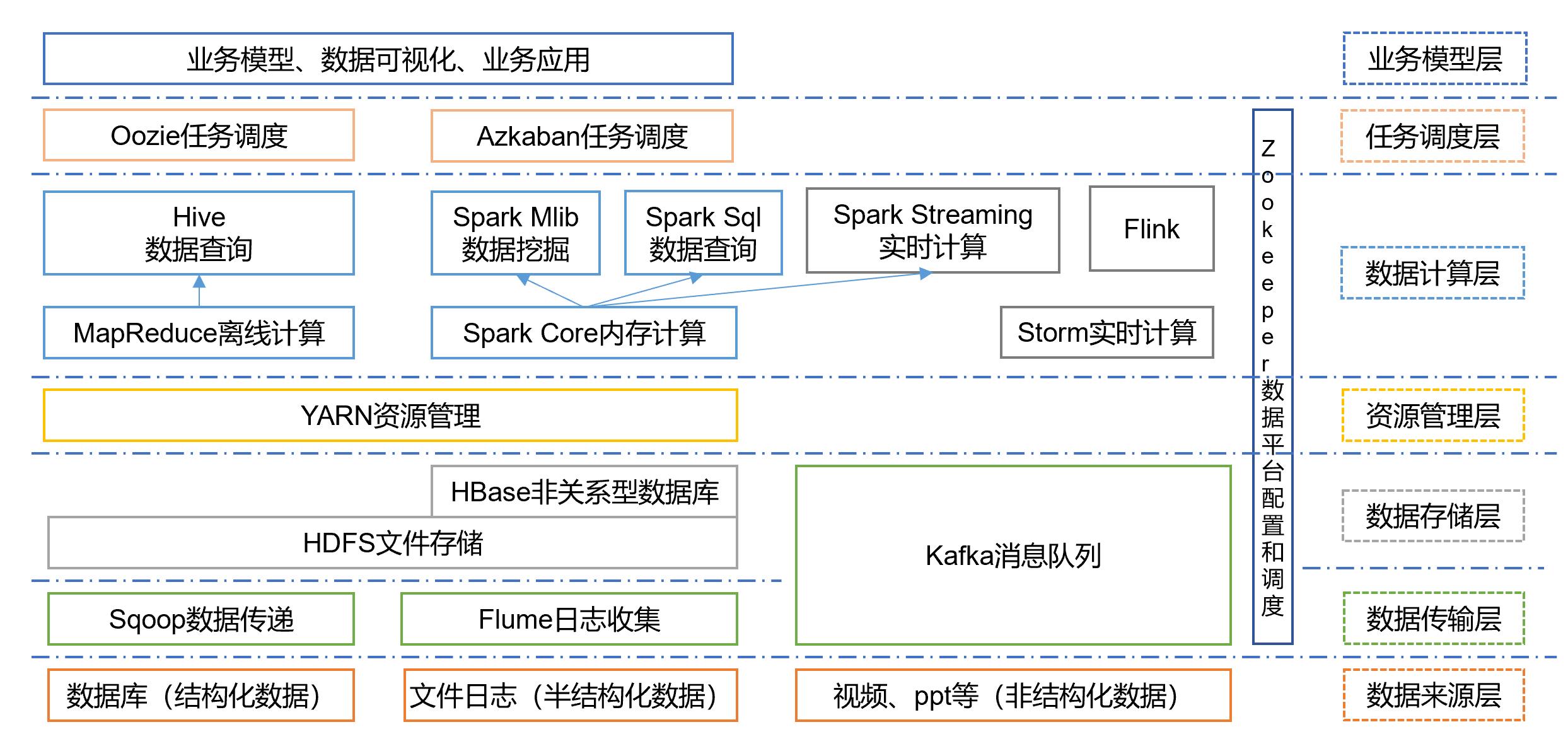
图中涉及的技术名词解释如下:
-
Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
-
Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
-
Kafka :Kafka是一种高吞吐量的分布式发布订阅消息系统;
-
Spark :Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
-
Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
-
Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
-
Hbase :HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
-
Hive :Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
-
ZooKeeper :它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- ZooKeeper :它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
加黑的是我们后面会学到的比较多的东西。
以上是关于从Hadoop框架讨论大数据生态的主要内容,如果未能解决你的问题,请参考以下文章