postgreSQL使用sql归一化数据表的某列,以及出现“字段 ‘xxx’ 必须出现在 GROUP BY 子句中或者在聚合函数中”错误的可能原因之一
Posted 自闭火柴的玩具熊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了postgreSQL使用sql归一化数据表的某列,以及出现“字段 ‘xxx’ 必须出现在 GROUP BY 子句中或者在聚合函数中”错误的可能原因之一相关的知识,希望对你有一定的参考价值。
前言:
归一化(区别于标准化)一般是指,把数据变换到(0,1)之间的小数。主要是为了方便数据处理,或者把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。
不过还是有很多人使用时将归一化(normalization)和标准化(standardization)两个概念混淆,在这里我们就不过多讨论了。这里的归一化主要指的是这个常用的公式:
x‘ = (x - X_min) / (X_max - X_min)
最近使用openlayers添加heatmap图层的时候,查看官方文档发现,发现热力图的权重数据(weight)需要范围在0-1的数据。而我使用的数据是省会城市所对应省份的县及县级以上城市数量,所以就需要对数据进行归一化处理。

postgreSQL中的min和max函数可以求出最小值和最大值,所以就决定直接在数据库中处理。
先是准备工作,将原始数据建立一个只有省会城市名(name),省内县及县级以上城市数量(value)和geom字段的查询,名叫process_t,便于归一化。
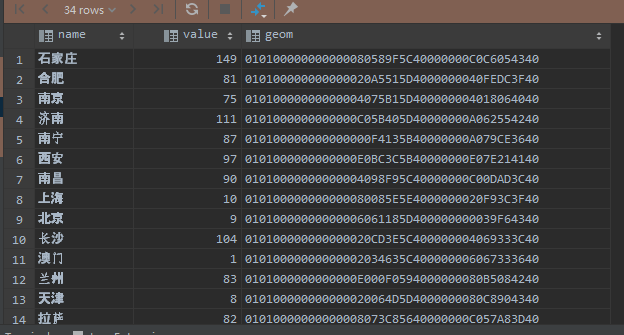
归一化的sql语句,一开始我是这样写的,其中process_t就是上面处理过的查询:
select name,geom,
process_t.value,
(value-min(process_t.value))/(max(process_t.value)-min(process_t.value))
from process_t
然而运行的时候出现了这么一个错误。但如果去掉min和max函数,或者去掉其他字段,这个错误就不会出现。
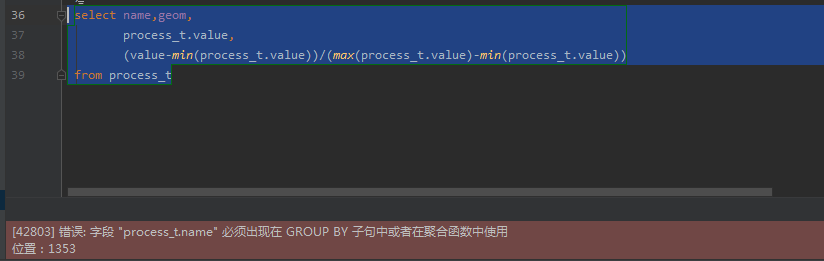
所以,这是由于max和min函数输出的值只有一条记录(最大值或最小值),但其他字段(name等)却拥有多条记录,这不能在一个查询中同时存在。因此,类似value-min(process_t.value),这样的语句就更行不通的。
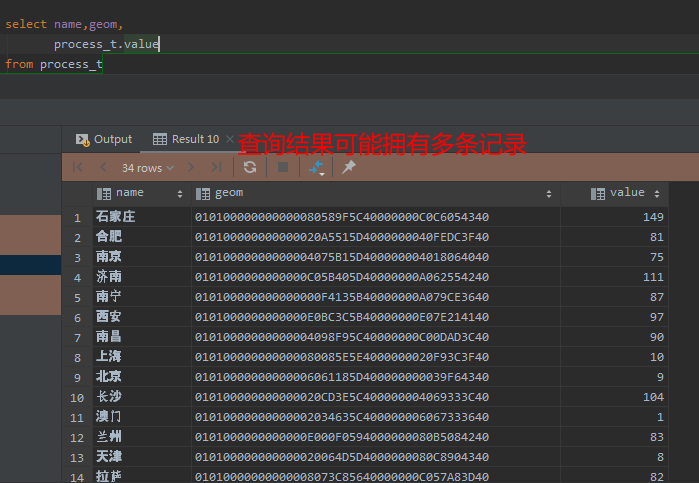
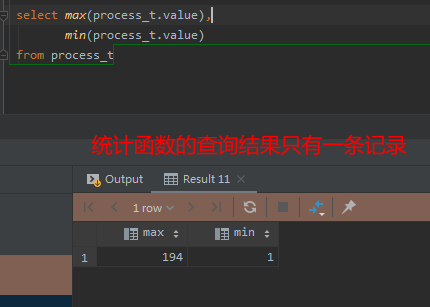
那么如何解决这个问题呢?
sql支持类似向量一样的运算,一个字段的多条记录与一个固定值进行运算是可以得到结果的,例如 value-1 就不会出现问题。
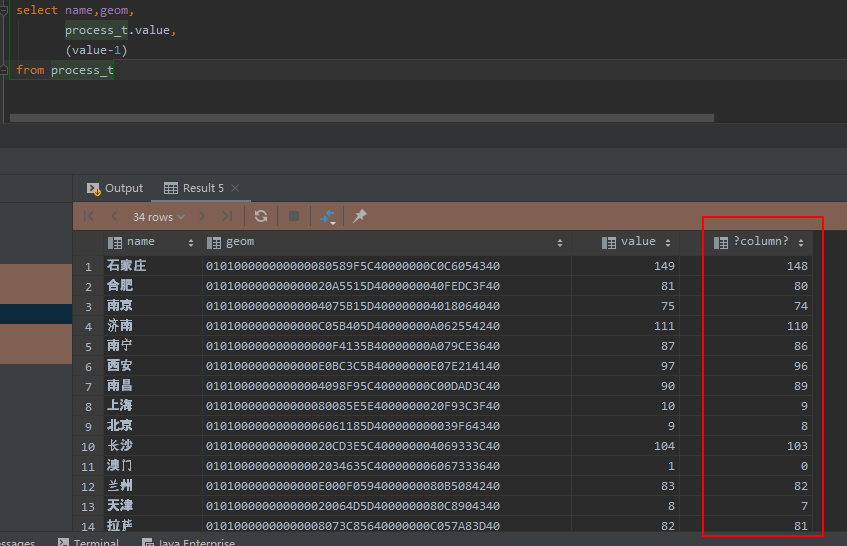
所以我们要保证的就是,sql语句中,与其他字段同时出现的不应该是一个带有聚合(统计)功能的函数(例如min,max,avg,stddev等),而是一个通过这些函数产生的固定值。这样就不会出现统计结果只有一条记录而其他字段有多条记录产生的冲突了。
例如:
select name,geom,
process_t.value,
(select max(process_t.value) from process_t) as max,
(select min(process_t.value) from process_t) as min
from process_t
其中的,(select max(process_t.value) from process_t) as max,
(select min(process_t.value) from process_t) as min
这两句话与直接使用max(process_t.value)或min(process_t.value)函数不同,它是将最大值和最小值的查询结果作为一个固定值写入新的查询之中,这样会让max和min字段的每条记录都有一个固定的值。
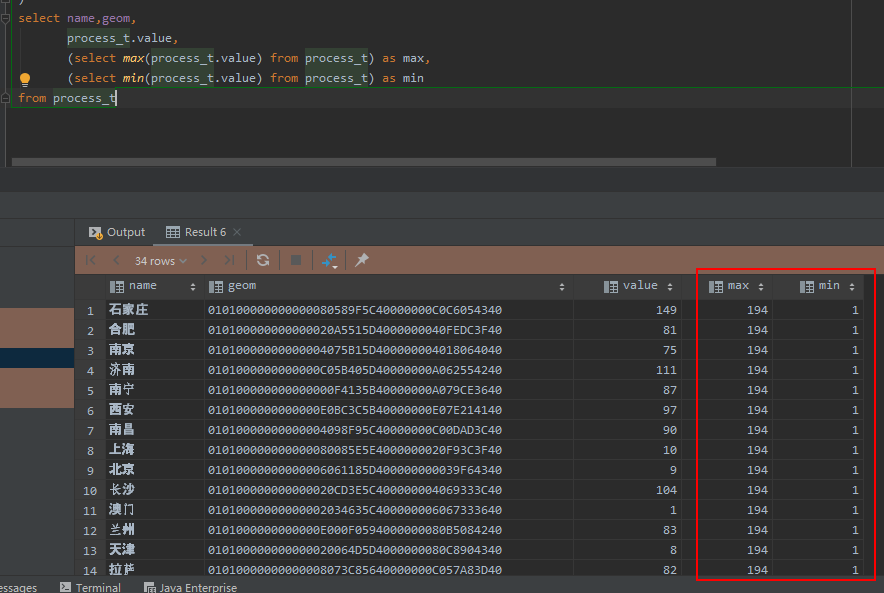
然后根据这个查询结果,通过公式进行归一化运算即可!!
当然,因为直接用(select max(process_t.value) from process_t)查询出来的结果可以作为一个固定值使用,所以也可以写成类似于’ value-1 ‘那样的语句,不产生新的字段,直接用原始数据归一化,例如:
select name,geom,
process_t.value,
(process_t.value - (select min(process_t.value) from process_t))*1.0/((select max(process_t.value) from process_t)-(select min(process_t.value) from process_t))
from process_t
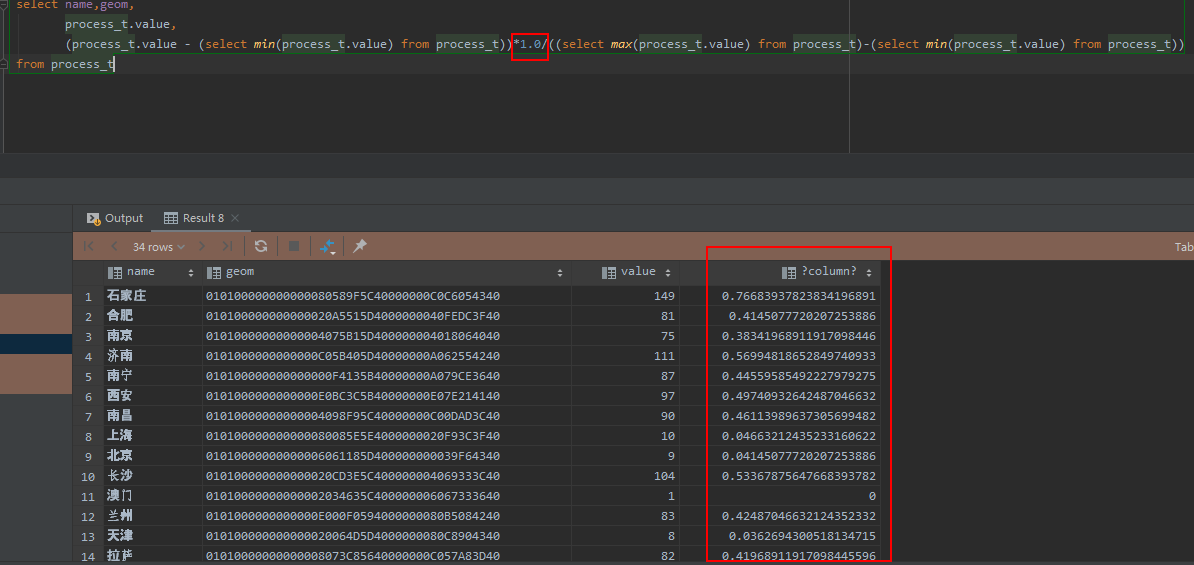
不难看到,这样做确实可以实现归一化。但这样写出来sql语句可读性实在是太差,所以还是先产生一个带有max和min字段的子查询,再进行归一化,这样会比较合理(在不考虑时空效率的前提下)。
最后,还有一点需要注意,归一化过程涉及整数相除,与C/C++,Java的除法类似的是,为了让结果保留为浮点数,sql语句中一定需要对整数类型进行强制类型转换或者像图中一样直接乘一个浮点数(1.0)
以上是关于postgreSQL使用sql归一化数据表的某列,以及出现“字段 ‘xxx’ 必须出现在 GROUP BY 子句中或者在聚合函数中”错误的可能原因之一的主要内容,如果未能解决你的问题,请参考以下文章