遍历字符串
我觉得首先要提出一个疑问:
一个数据库本身就是用于存储的,遍历字符串究竟有何意义?
先看如何实现的,毕竟sql service 是没有for循环,也没有loop和while的。
select SUBSTRING(e.ENAME,t.ID,1) as sub
from emp e,T10 t
where e.ENAME=\'JONES\' and t.ID<=len(e.ENAME)
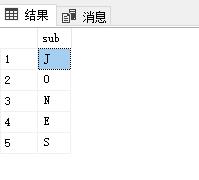
的确是遍历了这个字符串JONES.
原理也十分的简单:
select * from T10

T10 可以看成一个索引集,利用一个笛卡尔积的特性实现的。
加入不是去附加额外的条件:
select e.ENAME,t.ID
from emp e,T10 t
where e.ENAME=\'JONES\'

这就是它的一个简单原理。
回到业务层面,去数据库遍历一个字符串那么本身就不可以,因为数据库不是去计算层面的东西。
一般可用于用户的一些常规性,基本稳定的字段。
我们在查询一个记录的时候如果加上top 1,那么效率最高,因为不需要去遍历整张表。
所以比如用户的一些配置表示这样的:id(用户id) usersetting(某类用户特性).
举例而言:5 xxx,xxx,xxx,xxx,xxx,xxx
后面的xxx,xxx,xxx,xxx,xxx,xxx,是对应的另外一张表的主键,这张表的主键的id是生成的唯一id且长度相等。
那么就可以通过遍历的方式,查询出用户的具体特性。
下面这种:
select *
from xxx
where yy in
(select e.ENAME,t.ID
from emp e,T10 t
where e.ENAME=\'JONES\' )
由于自己水平的限制,这是我唯一遇到的情况,其他的情况也没遇上过。希望有人可以补充更加实用的例子,在此等待学习。
嵌入引号
这里只是接受两个\'\'是一个引号,如果只有\'\'为空,有点绕,看例子。
select \'g\'\'day mate\' from t1

select \'\' from t1

统计字符串出现的个数
通常往往一定,我们用的是正则,但是又碰巧sql service没有正则,这就巧了。
网上有一些文章写sql service 使用正则的,都是基本通过通配符来实现的。
这个就不需要这么麻烦了。
select (len(\'xxxx,xxxx,xxxx\')-len(REPLACE(\'xxxx,xxxx,xxxx\',\',\',\'\')))/len(\',\')
from T1
这个例子我第一个例子相对应。
删除不想要的字符
这个直接使用replace 函数替换即可,如果要替换几个,那么多次使用。例子参考上文。
在oracle 中可以使用 translate: replace(translate(\'你好啊 你好啊\',"mm",\'你啊\'),\'m\')
上文translate把"你" "啊" 全部换成了m,然后删除m即可。
translate 的第二个参数是每一位是和第三个参数的每一位相对应的。一个你,对应第一个m,第二个啊,对应第二个m,如果没有即为空。
在 sql service 2017以后:
select replace(translate(\'你好啊 你好啊\',\'mm\',\'你啊\'),\'m\',\'\')
from T1
分离数字和字符数据
和上面的一致,只是分离出数字后,需要用convert(int,\'xxx\') 转换
select CONVERT(int,REPLACE(translate(\'dadsawx10\',\'zzzzzzzzzzzzzzzzz\',\'abcdefghijklmnopqrstuvwxyz\'),\'z\',\'\')) as number,REPLACE(translate(\'dadsawx10\',\'0000000000\',\'0123456789\'),\'0\',\'\') as str
from t1