SQL语句:统计指定字段,等于不同值的条数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL语句:统计指定字段,等于不同值的条数相关的知识,希望对你有一定的参考价值。
例表:
===================================
ID 字段1 字段2 字段3
1 A B C
2 X B E
3 A B U
4 X D E
5 A K N
6 X D C
===================================
如SQL语句统计:字段1有多少不同的值,A值一种,X值一种,答案应是2
字段2有多少不同的值,B值一种,D值一种,K值一种,答案应是3
字段3有多少不同的值,C值一种,E值一种,U值一种,N值,答案应是3
Ps:重复值只算一种,如字段1,有3个相同值A。
要求SQL语句简洁,执行速度快。。。。
sql:select count(1) from tablename group by columes;
方法二:通过district函数来直接取出唯一字段,之后统计数量:
sql:select count(ditrict(columes)) from tablename;
解释:columes表示的是特殊字段。 参考技术A select count(distinct 字段1),count(distinct 字段2),count(distinct 字段3) from 表名追问
SELECT COUNT(DISTINCT 字段1) FROM TableName WHERE 月份=3
数据库ACCESS,调试出错,请问问题出在那?
是ACCESS不支持?
。。。。。。。。
参考技术B 语句:select count(distinct 字段1),count(distinct 字段2),count(distinct 字段3) from 表本回答被提问者采纳
sql语句中count(0)和count(1)的区别
一、意思不同
count(1)会统计包括null值的所有符合条件的字段的条数。count(0)将返回表格中所有存在的行的总数包括值为null的行,然而count(列名)将返回表格中除去null以外的所有行的总数(有默认值的列也会被计入),distinct 列名,得到的结果将是除去值为null和重复数据后的结果 。
二、作用不同
主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。 因为count(*),自动会优化指定到那一个字段。所以没必要去count(?),用count(*),sql会帮你完成优化的 。

三、使用结果不同
当abc为空的时候,第二种不算入count中,而第一种是无条件的都算入count中,比例一列数据
字段名叫abc
A
B
NULL
这样的话,第一种查询是3条,而第二种查询的结果是2条。
参考技术A从SQL语句中count(0)和count(1)用法并无实质上差异。
SQL语句中COUNT函数是返回一个查询的记录数。
COUNT(expr), COUNT(*),一列中的值数(如果将一个列名指定为 expr)或表中的行数或组中的行值(如果指定 *)。COUNT(expr) 忽略空值,但 COUNT(*) 在计数中包含它们 。
SQL语句中COUNT函数括号中可以填写任何实数,能正常使用。
以下代码COUNT函数括号中使用实数>
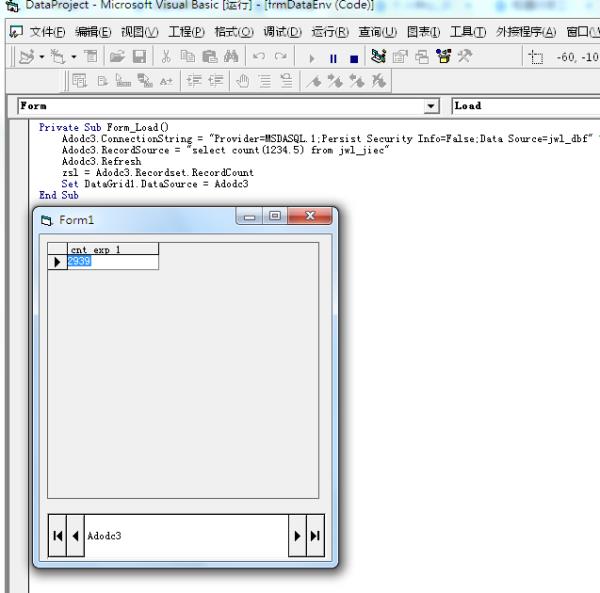
Private Sub Form_Load()
Adodc3.ConnectionString = "Provider=MSDASQL.1;Persist Security Info=False;Data Source=jwl_dbf" '/count(备件代码) as sj
Adodc3.RecordSource = "select count(1234.5) from jwl_jiec"
Adodc3.Refresh
zsl = Adodc3.Recordset.RecordCount
Set DataGrid1.DataSource = Adodc3
End Sub
运行界面如下:
不是吧?刚刚我测试,结果就是一样的,但是我听说两者有区别,好像是效率方面!还有count(*)
追答你说的是效率方面啊。 以为是执行出来的结果呢。 如果写表中带的列名或者* 效率会第一点。 写其他常数 效率会高
参考技术C count(1)或者count(0)这个效率快一些中间的是常量就没什么区别count(*)这个是最慢的 因为它要先去找*代表的列名是什么本回答被提问者采纳 参考技术D 区别在于
当abc为空的时候,第二种不算入count中
而第一种是无条件的都算入count中
比例一列数据
字段名叫abc
A
B
NULL
这样的话,第一种查询是3条,而第二种查询的结果是2条
你可以自己弄几条数据测试一下,就知道结果了
以上是关于SQL语句:统计指定字段,等于不同值的条数的主要内容,如果未能解决你的问题,请参考以下文章