k均值聚类算法、c均值聚类算法、模糊的c均值聚类算法的区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k均值聚类算法、c均值聚类算法、模糊的c均值聚类算法的区别相关的知识,希望对你有一定的参考价值。
k均值聚类:---------一种硬聚类算法,隶属度只有两个取值0或1,提出的基本根据是“类内误差平方和最小化”准则;模糊的c均值聚类算法:--------
一种模糊聚类算法,是k均值聚类算法的推广形式,隶属度取值为[0
1]区间内的任何一个数,提出的基本根据是“类内加权误差平方和最小化”准则;
这两个方法都是迭代求取最终的聚类划分,即聚类中心与隶属度值。两者都不能保证找到问题的最优解,都有可能收敛到局部极值,模糊c均值甚至可能是鞍点。
至于c均值似乎没有这么叫的,至少从我看到文献来看是没有。不必纠结于名称。如果你看的是某本模式识别的书,可能它想表达的意思就是k均值。
实际上k-means这个单词最先是好像在1965年的一篇文献提出来的,后来很多人把这种聚类叫做k均值。但是实际上十多年前就有了类似的算法,但是名字不一样,k均值的历史相当的复杂,在若干不同的领域都被单独提出。追寻算法的名称与历史没什么意义,明白具体的实现方法就好了。 参考技术A c均值和k均值算法一样吗?它俩有什么区别
图像分割基于空间信息的模糊均值聚类算法实现图像分割matlab源码
模糊聚类是指模糊C均值聚类(Fuzzy Cmeans),简写为FCM或者模糊Cmeans,同Kmeans一样,是一种被广泛应用的聚类算法。通过测试,发现,模糊Cmeans的聚类效果比Kmeans要优秀。
模糊聚类引入一个 隶属度矩阵 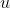 ,它是衡量当前样本属于某个类的可能性大小。当前样本可能属于类1,也可能属于累2,因此这种聚类成为模糊聚类。
,它是衡量当前样本属于某个类的可能性大小。当前样本可能属于类1,也可能属于累2,因此这种聚类成为模糊聚类。
若数据集 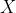 被划分成c个类,那么有c个类中心,样本
被划分成c个类,那么有c个类中心,样本 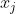 与类中心
与类中心 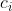 的隶属度为
的隶属度为 
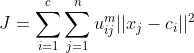 ,其中m是隶属度因子。
,其中m是隶属度因子。
接下来就是利用约束函数求解 ,采用的拉格朗日乘数法(具体推导,点击: 聚类之详解FCM算法原理及应用 ,这里就不做详细介绍),得到 是 相互关联 的。在算法开始的时候,假设其中一个值(例如 通过对方得计算自己。
可以简单 是样本与贡献度乘积的结果。
6.1 算法流程
输入:样本 ,类的个数c,隶属度因子m(一般取2),迭代次数
输出:模糊Cmeans聚类结果
- 确定分类个数c,指数m的值,确定迭代次数(这是结束的条件,当然结束的条件可以有多种)。
- 初始化一个隶属度
- 根据
- 这个时候可以计算目标函数
了
- 根据
%% 测试 SFCM 在SAR图像陆地掩膜中的效果
close all;
img = imread('mrihead.bmp');
img=imresize(img,[500,500],'nearest');
ds = 2; Ds = 5; h = 15;
% NLMF_img = NonLocalMeansFilter(img, ds, Ds, h); %非局部均值滤波,去盐噪声
% % img=NLMF_img;
% figure,imshow(NLMF_img,[]);
[MF,Cent,Obj]=SFCM2D(img,2);
flag=MF(1,:);
map=img;
map(flag>0.5)=0;
map(map>0)=1;
figure,imshow(img,[]);
figure,imshow(map,[]);


完整代码或者仿真咨询添加QQ1575304183
以上是关于k均值聚类算法、c均值聚类算法、模糊的c均值聚类算法的区别的主要内容,如果未能解决你的问题,请参考以下文章