模糊c–均值聚类算法的原理解释及推导
Posted Spuer_Tiger
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模糊c–均值聚类算法的原理解释及推导相关的知识,希望对你有一定的参考价值。
模糊𝑐–均值聚类算法的原理解释及推导
前置知识:𝑘–均值聚类的缺陷
- 算法要求每个样本数据点在一次迭代过程中只能被划分到某个特定的簇中。
- 样本数据并非都满足这种非此即彼的刚性划分。
在k-均值聚类存在缺陷的情况下,我们提出了模糊c-均值聚类算法。
核心部分:模糊𝑐–均值聚类
基本思想:
- 使用模糊数学中属于[0,1]区间的隶属度指的是度量单个样本隶属于各个簇的程度。
- 规定每个样本到所有簇的隶属度之和均为1,若某个样本到某个簇的隶属度为1,则表示该样本完全隶属于该簇。
原理推导:
-
如图所示:
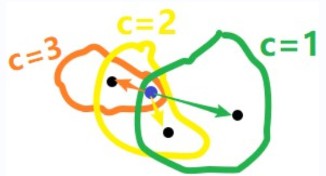
-
给定示例样本数据集𝐷 = {𝑋1, 𝑋2, … , 𝑋𝑛},假设对数据集𝐷进行模糊聚类得到𝑐个簇𝐶1, 𝐶2, … , 𝐶𝑐,𝐷中任意给定单个样本𝑋𝑖对于第𝑗个簇𝐶𝑗的隶属度为𝛼𝑖𝑗,则可使用如下加权欧式距离𝑤𝑖𝑗度量样本𝑋𝑖与簇𝐶𝑗之间的相关性:
w i j = α i j ( ∑ t = 1 m ( x i t − u j t ) 2 ) 1 2 \\mathbf{w}_{\\mathbf{ij}}=\\mathbf{\\alpha }_{\\mathbf{ij}}\\left( \\sum_{\\mathbf{t}=1}^{\\mathbf{m}}{\\left( \\mathbf{x}_{\\mathbf{it}}-\\mathbf{u}_{\\mathbf{jt}} \\right) ^2} \\right) ^{\\frac{1}{2}} wij=αij(t=1∑m(xit−ujt)2)21
其中𝑢𝑗𝑡表示第𝑗个簇𝐶𝑗的聚类中心𝑈𝑗第𝑡个坐标分量。 -
依据上述加权欧式距离𝑤𝑖𝑗计算公式可得所有簇内加权距离之和为:
d ( α i j ) = ∑ j = 1 c ∑ i = 1 n α i j ( ∑ t = 1 m ( x i t − u j t ) 2 ) 1 2 \\mathbf{d}\\left( \\mathbf{\\alpha }_{\\mathbf{ij}} \\right) =\\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\mathbf{\\alpha }_{\\mathbf{ij}}\\left( \\sum_{\\mathbf{t}=1}^{\\mathbf{m}}{\\left( \\mathbf{x}_{\\mathbf{it}}-\\mathbf{u}_{\\mathbf{jt}} \\right) ^2} \\right) ^{\\frac{1}{2}}}} d(αij)=j=1∑ci=1∑nαij(t=1∑m(xit−ujt)2)21 -
为控制隶属度对聚类最终效果的影响并简化计算,可将上述加权距离之和𝑑(𝛼𝑖𝑗)改写为如下形式:
J ( α i j ) = ∑ j = 1 c ∑ i = 1 n α i j p ∑ t = 1 m ( x i t − u j t ) 2 \\mathbf{J}\\left( \\mathbf{\\alpha }_{\\mathbf{ij}} \\right) =\\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\mathbf{\\alpha }_{\\mathbf{ij}}^{\\mathbf{p}}\\sum_{\\mathbf{t}=1}^{\\mathbf{m}}{\\left( \\mathbf{x}_{\\mathbf{it}}-\\mathbf{u}_{\\mathbf{jt}} \\right) ^2}}} J(αij)=j=1∑ci=1∑nαijpt=1∑m(xit−ujt)2
其中𝑝为控制隶属度影响的参数,通常取𝑝 = 2 ,并且𝑝值越大,则隶属度对最终的聚类效果影响就越大。(因为 ∑ j = 1 c α i j = 1 \\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\mathbf{\\alpha }_{\\mathbf{ij}}}=1 ∑j=1cαij=1,然后p越大, α i j p \\mathbf{\\alpha }_{\\mathbf{ij}}^{\\mathbf{p}} αijp使得不同类别的 α i j \\mathbf{\\alpha }_{\\mathbf{ij}} αij之间的差距变大) -
上述关于𝛼𝑖𝑗的函数𝐽(𝛼𝑖𝑗)既包含所有簇内加权总距离,又包含该聚类算法边界划分的模糊程度,故可将其作为目标函数将样本数据集𝐷的模糊聚类问题转化为J(𝛼𝑖𝑗)的最小值优化问题(这里的意思,就是找到使得xi到c个聚类中心的加权距离和最小的𝛼𝑖𝑗,其中i=1,2,…,c),即:
a r g α i j min J ( α i j ) ; s . t . ∑ j = 1 c α i j = 1 \\mathbf{arg}_{\\mathbf{\\alpha }_{\\mathbf{ij}}}\\min \\mathbf{J}\\left( \\mathbf{\\alpha }_{\\mathbf{ij}} \\right) \\text{;}\\mathbf{s}.\\mathbf{t}.\\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\mathbf{\\alpha }_{\\mathbf{ij}}}=1 argαijminJ(αij);s.t.j=1∑cαij=1 -
可用拉格朗日乘数法求解上述条件优化问题。令拉格朗日函数为:
J ∧ ( α i j ) = ∑ j = 1 c ∑ i = 1 n α i j p ∑ t = 1 m ( x i t − u j t ) 2 + ∑ i = 1 n λ i ( ∑ j = 1 c α i j − 1 ) \\overset{\\land}{\\mathbf{J}}\\left( \\mathbf{\\alpha }_{\\mathbf{ij}} \\right) =\\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\mathbf{\\alpha }_{\\mathbf{ij}}^{\\mathbf{p}}\\sum_{\\mathbf{t}=1}^{\\mathbf{m}}{\\left( \\mathbf{x}_{\\mathbf{it}}-\\mathbf{u}_{\\mathbf{jt}} \\right) ^2}}}+\\sum_{\\mathbf{i}=1}^{\\mathbf{n}}{\\mathbf{\\lambda }_{\\mathbf{i}}\\left( \\sum_{\\mathbf{j}=1}^{\\mathbf{c}}{\\mathbf{\\alpha }_{\\mathbf{ij}}}-1 \\right)} J∧(αij)=j=1∑ci=1∑nαijpt=1∑m(xit−ujt)2+i=1∑nλi⎝⎛j=1∑cα以上是关于模糊c–均值聚类算法的原理解释及推导的主要内容,如果未能解决你的问题,请参考以下文章