模糊 K 均值聚类算法
Posted 音频核
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模糊 K 均值聚类算法相关的知识,希望对你有一定的参考价值。
假设特征矢量集,X={x1,x2,...,xT},T 是语音帧数,每个矢量 xj 都是 p 维的,代表的是第 j 帧的特征参数。模糊 k-means 聚类算法的核心思想在于最小化式(下式)所示的目标函数:
其中,µij 表示矢量 xj 被分到第 i 类的概率,µ=[µij]是一个 K×T 的矩阵,满足下面的一些 性质:
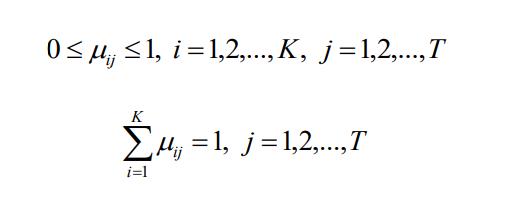
同时,m(m≥2)是控制模糊度的一个加权指数,dij2 表示的是 xj 与 ci 之间的距离,定义式 如下所示:
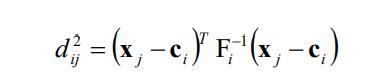
其中,ci 指的是第 i 个聚类中心,Fi 表示的是第 i 个聚类的模糊协方差矩阵,通过令 Jm 相对 µ和 c 的梯度为 0 求得,如下式:
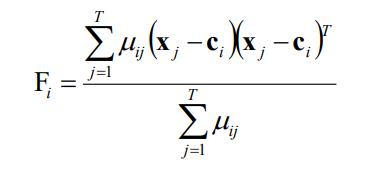
只有在满足下面两式的情况下,才能求得目标函数(即本文第一个公式)的最小化。
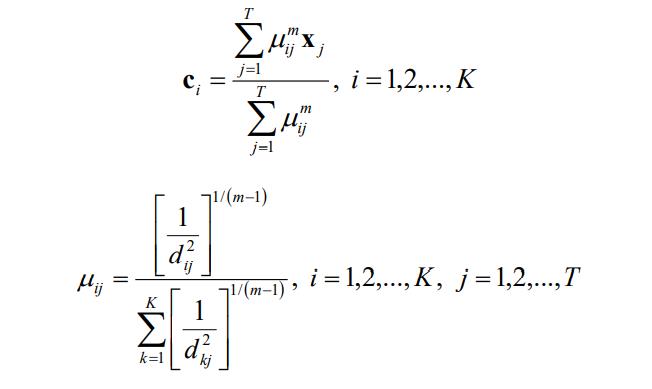
上面两个式子的求解过程如下:
(1) 设定聚类数目 K,加权指数 m(m≥2),终止条件 ε(ε>0)以及迭代次数 l。
(2) 初始化隶属度矩阵 µ(0)。
(3) 计算聚类中心 ci (l)。
(4) 更隶属度矩阵 µij (l),直到满足||µ (l) -µ (l-1)||<ε 或是达到最大迭代次数。
本文中的最终特征矢量的分类就是用到了最大隶属度值,也就是说,对于任意的一个特 征矢量 xj(j=1,2,....,T),如果 µij=max{µ1j,µ2j,...,µKj}成立,那么 xj 就属于第 i 类。
本文中总的高斯混合分量 M 是 64 个,每一类里高斯混合分量的个数 Mi 是由该类中训练 特征矢量的帧数 Ti 占总的训练特征矢量帧数 Tall 的比例来决定的,
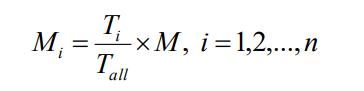
其中,
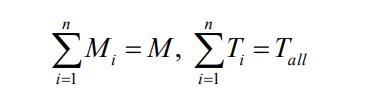
n 是聚类数。
给定 I 和 Ii 分别表示总的训练迭代次数和每个聚类的训练迭代次数。因此,GMM 模型参 数的估计所需的计算时间 P 如下式所示:
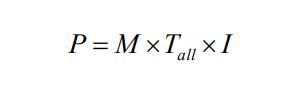
聚类之后,上式可表示为
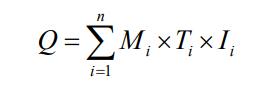
假定每个聚类中的高斯混合分量个数是相同的,则
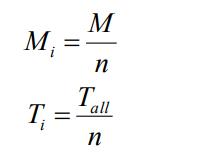
将上面两个公式带入式(聚类之后下面的公式)可得:
由该式可知,随着聚类的每一类中的训练矢量的减少,以及每一类的训练矢量主要集中 在聚类中心周围,训练速度可以得到一定程度的提高。
上图显示的基于不同聚类中心的模糊 K-means 聚类的频谱失真,聚类中心数目分别是 10,20,30 和 40,从图中可以很明显的看出,随着聚类中心数目的增加,频谱失真也随之变 大,因此,本文采用的聚类中心数目为 10 个。
以上是关于模糊 K 均值聚类算法的主要内容,如果未能解决你的问题,请参考以下文章